 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Image Super Resolution with a Single Auto-Regressive Model
Jun 05, 2025In this paper we tackle Image Super Resolution (ISR), using recent advances in Visual Auto-Regressive (VAR) modeling. VAR iteratively estimates the residual in latent space between gradually increasing image scales, a process referred to as next-scale prediction. Thus, the strong priors learned during pre-training align well with the downstream task (ISR). To our knowledge, only VARSR has exploited this synergy so far, showing promising results. However, due to the limitations of existing residual quantizers, VARSR works only at a fixed resolution, i.e. it fails to map intermediate outputs to the corresponding image scales. Additionally, it relies on a 1B transformer architecture (VAR-d24), and leverages a large-scale private dataset to achieve state-of-the-art results. We address these limitations through two novel components: a) a Hierarchical Image Tokenization approach with a multi-scale image tokenizer that progressively represents images at different scales while simultaneously enforcing token overlap across scales, and b) a Direct Preference Optimization (DPO) regularization term that, relying solely on the LR and HR tokenizations, encourages the transformer to produce the latter over the former. To the best of our knowledge, this is the first time a quantizer is trained to force semantically consistent residuals at different scales, and the first time that preference-based optimization is used to train a VAR. Using these two components, our model can denoise the LR image and super-resolve at half and full target upscale factors in a single forward pass. Additionally, we achieve \textit{state-of-the-art results on ISR}, while using a small model (300M params vs ~1B params of VARSR), and without using external training data.
MM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance
Sep 17, 2024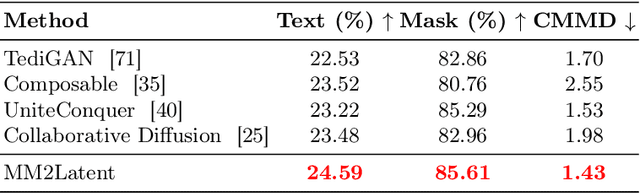
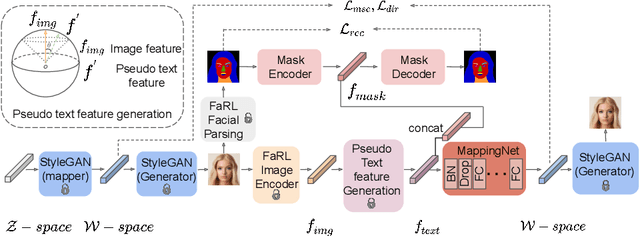
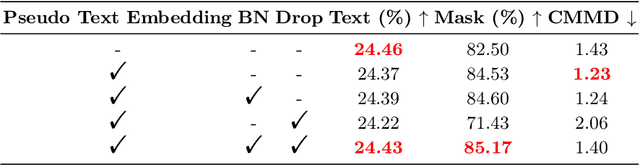

Generating human portraits is a hot topic in the image generation area, e.g. mask-to-face generation and text-to-face generation. However, these unimodal generation methods lack controllability in image generation. Controllability can be enhanced by exploring the advantages and complementarities of various modalities. For instance, we can utilize the advantages of text in controlling diverse attributes and masks in controlling spatial locations. Current state-of-the-art methods in multimodal generation face limitations due to their reliance on extensive hyperparameters, manual operations during the inference stage, substantial computational demands during training and inference, or inability to edit real images. In this paper, we propose a practical framework - MM2Latent - for multimodal image generation and editing. We use StyleGAN2 as our image generator, FaRL for text encoding, and train an autoencoders for spatial modalities like mask, sketch and 3DMM. We propose a strategy that involves training a mapping network to map the multimodal input into the w latent space of StyleGAN. The proposed framework 1) eliminates hyperparameters and manual operations in the inference stage, 2) ensures fast inference speeds, and 3) enables the editing of real images. Extensive experiments demonstrate that our method exhibits superior performance in multimodal image generation, surpassing recent GAN- and diffusion-based methods. Also, it proves effective in multimodal image editing and is faster than GAN- and diffusion-based methods. We make the code publicly available at: https://github.com/Open-Debin/MM2Latent
Are CLIP features all you need for Universal Synthetic Image Origin Attribution?
Aug 17, 2024



The steady improvement of Diffusion Models for visual synthesis has given rise to many new and interesting use cases of synthetic images but also has raised concerns about their potential abuse, which poses significant societal threats. To address this, fake images need to be detected and attributed to their source model, and given the frequent release of new generators, realistic applications need to consider an Open-Set scenario where some models are unseen at training time. Existing forensic techniques are either limited to Closed-Set settings or to GAN-generated images, relying on fragile frequency-based "fingerprint" features. By contrast, we propose a simple yet effective framework that incorporates features from large pre-trained foundation models to perform Open-Set origin attribution of synthetic images produced by various generative models, including Diffusion Models. We show that our method leads to remarkable attribution performance, even in the low-data regime, exceeding the performance of existing methods and generalizes better on images obtained from a diverse set of architectures. We make the code publicly available at: https://github.com/ciodar/UniversalAttribution.
Ensembled Cold-Diffusion Restorations for Unsupervised Anomaly Detection
Jul 09, 2024Unsupervised Anomaly Detection (UAD) methods aim to identify anomalies in test samples comparing them with a normative distribution learned from a dataset known to be anomaly-free. Approaches based on generative models offer interpretability by generating anomaly-free versions of test images, but are typically unable to identify subtle anomalies. Alternatively, approaches using feature modelling or self-supervised methods, such as the ones relying on synthetically generated anomalies, do not provide out-of-the-box interpretability. In this work, we present a novel method that combines the strengths of both strategies: a generative cold-diffusion pipeline (i.e., a diffusion-like pipeline which uses corruptions not based on noise) that is trained with the objective of turning synthetically-corrupted images back to their normal, original appearance. To support our pipeline we introduce a novel synthetic anomaly generation procedure, called DAG, and a novel anomaly score which ensembles restorations conditioned with different degrees of abnormality. Our method surpasses the prior state-of-the art for unsupervised anomaly detection in three different Brain MRI datasets.
DiffusionAct: Controllable Diffusion Autoencoder for One-shot Face Reenactment
Mar 25, 2024



Video-driven neural face reenactment aims to synthesize realistic facial images that successfully preserve the identity and appearance of a source face, while transferring the target head pose and facial expressions. Existing GAN-based methods suffer from either distortions and visual artifacts or poor reconstruction quality, i.e., the background and several important appearance details, such as hair style/color, glasses and accessories, are not faithfully reconstructed. Recent advances in Diffusion Probabilistic Models (DPMs) enable the generation of high-quality realistic images. To this end, in this paper we present DiffusionAct, a novel method that leverages the photo-realistic image generation of diffusion models to perform neural face reenactment. Specifically, we propose to control the semantic space of a Diffusion Autoencoder (DiffAE), in order to edit the facial pose of the input images, defined as the head pose orientation and the facial expressions. Our method allows one-shot, self, and cross-subject reenactment, without requiring subject-specific fine-tuning. We compare against state-of-the-art GAN-, StyleGAN2-, and diffusion-based methods, showing better or on-par reenactment performance.
Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization
Feb 19, 2024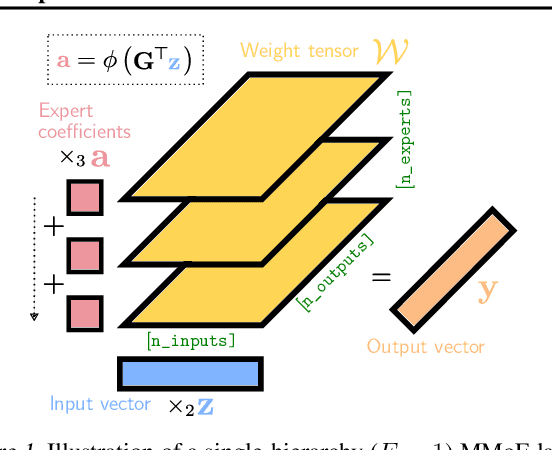



The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification. Our MMoE model code is available at https://github.com/james-oldfield/MMoE.
One-shot Neural Face Reenactment via Finding Directions in GAN's Latent Space
Feb 05, 2024



In this paper, we present our framework for neural face/head reenactment whose goal is to transfer the 3D head orientation and expression of a target face to a source face. Previous methods focus on learning embedding networks for identity and head pose/expression disentanglement which proves to be a rather hard task, degrading the quality of the generated images. We take a different approach, bypassing the training of such networks, by using (fine-tuned) pre-trained GANs which have been shown capable of producing high-quality facial images. Because GANs are characterized by weak controllability, the core of our approach is a method to discover which directions in latent GAN space are responsible for controlling head pose and expression variations. We present a simple pipeline to learn such directions with the aid of a 3D shape model which, by construction, inherently captures disentangled directions for head pose, identity, and expression. Moreover, we show that by embedding real images in the GAN latent space, our method can be successfully used for the reenactment of real-world faces. Our method features several favorable properties including using a single source image (one-shot) and enabling cross-person reenactment. Extensive qualitative and quantitative results show that our approach typically produces reenacted faces of notably higher quality than those produced by state-of-the-art methods for the standard benchmarks of VoxCeleb1 & 2.
DISYRE: Diffusion-Inspired SYnthetic REstoration for Unsupervised Anomaly Detection
Nov 26, 2023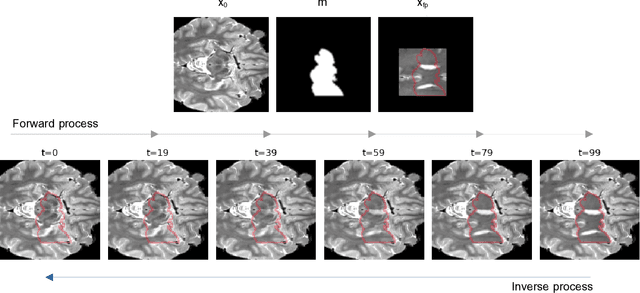
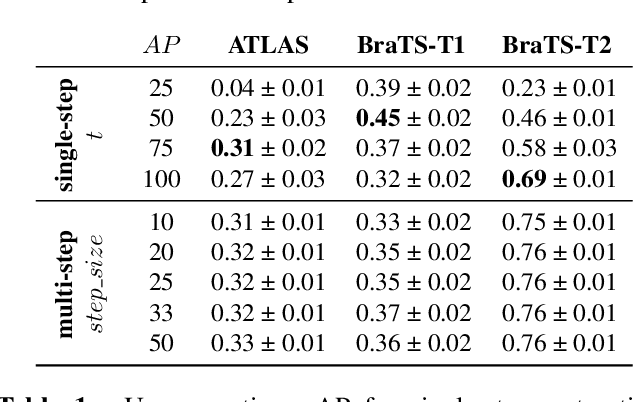
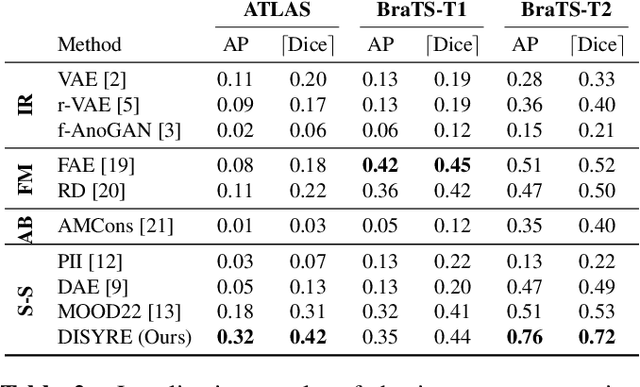
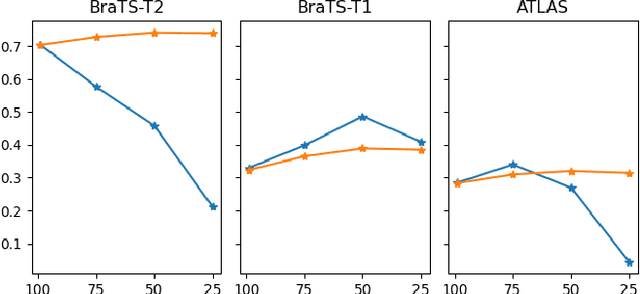
Unsupervised Anomaly Detection (UAD) techniques aim to identify and localize anomalies without relying on annotations, only leveraging a model trained on a dataset known to be free of anomalies. Diffusion models learn to modify inputs $x$ to increase the probability of it belonging to a desired distribution, i.e., they model the score function $\nabla_x \log p(x)$. Such a score function is potentially relevant for UAD, since $\nabla_x \log p(x)$ is itself a pixel-wise anomaly score. However, diffusion models are trained to invert a corruption process based on Gaussian noise and the learned score function is unlikely to generalize to medical anomalies. This work addresses the problem of how to learn a score function relevant for UAD and proposes DISYRE: Diffusion-Inspired SYnthetic REstoration. We retain the diffusion-like pipeline but replace the Gaussian noise corruption with a gradual, synthetic anomaly corruption so the learned score function generalizes to medical, naturally occurring anomalies. We evaluate DISYRE on three common Brain MRI UAD benchmarks and substantially outperform other methods in two out of the three tasks.
Improving Fairness using Vision-Language Driven Image Augmentation
Nov 02, 2023



Fairness is crucial when training a deep-learning discriminative model, especially in the facial domain. Models tend to correlate specific characteristics (such as age and skin color) with unrelated attributes (downstream tasks), resulting in biases which do not correspond to reality. It is common knowledge that these correlations are present in the data and are then transferred to the models during training. This paper proposes a method to mitigate these correlations to improve fairness. To do so, we learn interpretable and meaningful paths lying in the semantic space of a pre-trained diffusion model (DiffAE) -- such paths being supervised by contrastive text dipoles. That is, we learn to edit protected characteristics (age and skin color). These paths are then applied to augment images to improve the fairness of a given dataset. We test the proposed method on CelebA-HQ and UTKFace on several downstream tasks with age and skin color as protected characteristics. As a proxy for fairness, we compute the difference in accuracy with respect to the protected characteristics. Quantitative results show how the augmented images help the model improve the overall accuracy, the aforementioned metric, and the disparity of equal opportunity. Code is available at: https://github.com/Moreno98/Vision-Language-Bias-Control.
HyperReenact: One-Shot Reenactment via Jointly Learning to Refine and Retarget Faces
Jul 20, 2023



In this paper, we present our method for neural face reenactment, called HyperReenact, that aims to generate realistic talking head images of a source identity, driven by a target facial pose. Existing state-of-the-art face reenactment methods train controllable generative models that learn to synthesize realistic facial images, yet producing reenacted faces that are prone to significant visual artifacts, especially under the challenging condition of extreme head pose changes, or requiring expensive few-shot fine-tuning to better preserve the source identity characteristics. We propose to address these limitations by leveraging the photorealistic generation ability and the disentangled properties of a pretrained StyleGAN2 generator, by first inverting the real images into its latent space and then using a hypernetwork to perform: (i) refinement of the source identity characteristics and (ii) facial pose re-targeting, eliminating this way the dependence on external editing methods that typically produce artifacts. Our method operates under the one-shot setting (i.e., using a single source frame) and allows for cross-subject reenactment, without requiring any subject-specific fine-tuning. We compare our method both quantitatively and qualitatively against several state-of-the-art techniques on the standard benchmarks of VoxCeleb1 and VoxCeleb2, demonstrating the superiority of our approach in producing artifact-free images, exhibiting remarkable robustness even under extreme head pose changes. We make the code and the pretrained models publicly available at: https://github.com/StelaBou/HyperReenact .