 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Conditioned Diffusion for Controllable Histopathology Image Generation
Oct 08, 2025Recent advances in Diffusion Probabilistic Models (DPMs) have set new standards in high-quality image synthesis. Yet, controlled generation remains challenging, particularly in sensitive areas such as medical imaging. Medical images feature inherent structure such as consistent spatial arrangement, shape or texture, all of which are critical for diagnosis. However, existing DPMs operate in noisy latent spaces that lack semantic structure and strong priors, making it difficult to ensure meaningful control over generated content. To address this, we propose graph-based object-level representations for Graph-Conditioned-Diffusion. Our approach generates graph nodes corresponding to each major structure in the image, encapsulating their individual features and relationships. These graph representations are processed by a transformer module and integrated into a diffusion model via the text-conditioning mechanism, enabling fine-grained control over generation. We evaluate this approach using a real-world histopathology use case, demonstrating that our generated data can reliably substitute for annotated patient data in downstream segmentation tasks. The code is available here.
JVID: Joint Video-Image Diffusion for Visual-Quality and Temporal-Consistency in Video Generation
Sep 21, 2024



We introduce the Joint Video-Image Diffusion model (JVID), a novel approach to generating high-quality and temporally coherent videos. We achieve this by integrating two diffusion models: a Latent Image Diffusion Model (LIDM) trained on images and a Latent Video Diffusion Model (LVDM) trained on video data. Our method combines these models in the reverse diffusion process, where the LIDM enhances image quality and the LVDM ensures temporal consistency. This unique combination allows us to effectively handle the complex spatio-temporal dynamics in video generation. Our results demonstrate quantitative and qualitative improvements in producing realistic and coherent videos.
Universal Topology Refinement for Medical Image Segmentation with Polynomial Feature Synthesis
Sep 15, 2024Although existing medical image segmentation methods provide impressive pixel-wise accuracy, they often neglect topological correctness, making their segmentations unusable for many downstream tasks. One option is to retrain such models whilst including a topology-driven loss component. However, this is computationally expensive and often impractical. A better solution would be to have a versatile plug-and-play topology refinement method that is compatible with any domain-specific segmentation pipeline. Directly training a post-processing model to mitigate topological errors often fails as such models tend to be biased towards the topological errors of a target segmentation network. The diversity of these errors is confined to the information provided by a labelled training set, which is especially problematic for small datasets. Our method solves this problem by training a model-agnostic topology refinement network with synthetic segmentations that cover a wide variety of topological errors. Inspired by the Stone-Weierstrass theorem, we synthesize topology-perturbation masks with randomly sampled coefficients of orthogonal polynomial bases, which ensures a complete and unbiased representation. Practically, we verified the efficiency and effectiveness of our methods as being compatible with multiple families of polynomial bases, and show evidence that our universal plug-and-play topology refinement network outperforms both existing topology-driven learning-based and post-processing methods. We also show that combining our method with learning-based models provides an effortless add-on, which can further improve the performance of existing approaches.
URCDM: Ultra-Resolution Image Synthesis in Histopathology
Jul 18, 2024Diagnosing medical conditions from histopathology data requires a thorough analysis across the various resolutions of Whole Slide Images (WSI). However, existing generative methods fail to consistently represent the hierarchical structure of WSIs due to a focus on high-fidelity patches. To tackle this, we propose Ultra-Resolution Cascaded Diffusion Models (URCDMs) which are capable of synthesising entire histopathology images at high resolutions whilst authentically capturing the details of both the underlying anatomy and pathology at all magnification levels. We evaluate our method on three separate datasets, consisting of brain, breast and kidney tissue, and surpass existing state-of-the-art multi-resolution models. Furthermore, an expert evaluation study was conducted, demonstrating that URCDMs consistently generate outputs across various resolutions that trained evaluators cannot distinguish from real images. All code and additional examples can be found on GitHub.
Ensembled Cold-Diffusion Restorations for Unsupervised Anomaly Detection
Jul 09, 2024Unsupervised Anomaly Detection (UAD) methods aim to identify anomalies in test samples comparing them with a normative distribution learned from a dataset known to be anomaly-free. Approaches based on generative models offer interpretability by generating anomaly-free versions of test images, but are typically unable to identify subtle anomalies. Alternatively, approaches using feature modelling or self-supervised methods, such as the ones relying on synthetically generated anomalies, do not provide out-of-the-box interpretability. In this work, we present a novel method that combines the strengths of both strategies: a generative cold-diffusion pipeline (i.e., a diffusion-like pipeline which uses corruptions not based on noise) that is trained with the objective of turning synthetically-corrupted images back to their normal, original appearance. To support our pipeline we introduce a novel synthetic anomaly generation procedure, called DAG, and a novel anomaly score which ensembles restorations conditioned with different degrees of abnormality. Our method surpasses the prior state-of-the art for unsupervised anomaly detection in three different Brain MRI datasets.
DISYRE: Diffusion-Inspired SYnthetic REstoration for Unsupervised Anomaly Detection
Nov 26, 2023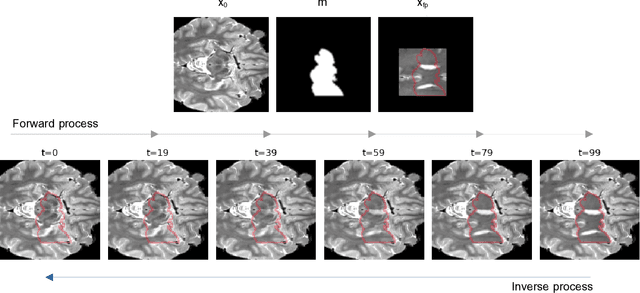
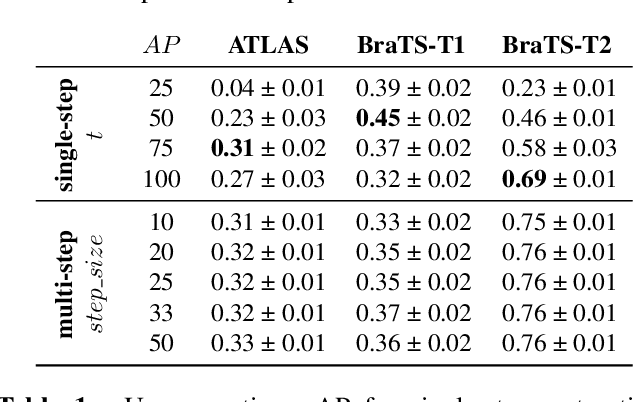
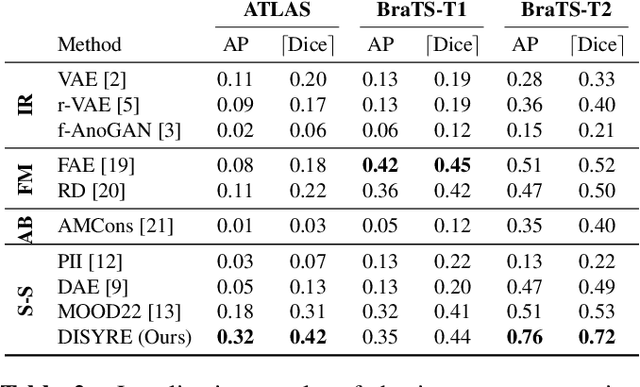
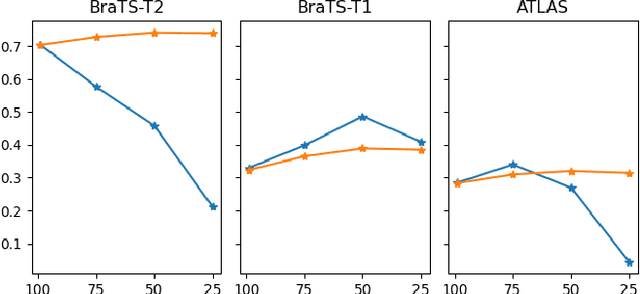
Unsupervised Anomaly Detection (UAD) techniques aim to identify and localize anomalies without relying on annotations, only leveraging a model trained on a dataset known to be free of anomalies. Diffusion models learn to modify inputs $x$ to increase the probability of it belonging to a desired distribution, i.e., they model the score function $\nabla_x \log p(x)$. Such a score function is potentially relevant for UAD, since $\nabla_x \log p(x)$ is itself a pixel-wise anomaly score. However, diffusion models are trained to invert a corruption process based on Gaussian noise and the learned score function is unlikely to generalize to medical anomalies. This work addresses the problem of how to learn a score function relevant for UAD and proposes DISYRE: Diffusion-Inspired SYnthetic REstoration. We retain the diffusion-like pipeline but replace the Gaussian noise corruption with a gradual, synthetic anomaly corruption so the learned score function generalizes to medical, naturally occurring anomalies. We evaluate DISYRE on three common Brain MRI UAD benchmarks and substantially outperform other methods in two out of the three tasks.
Many tasks make light work: Learning to localise medical anomalies from multiple synthetic tasks
Jul 03, 2023There is a growing interest in single-class modelling and out-of-distribution detection as fully supervised machine learning models cannot reliably identify classes not included in their training. The long tail of infinitely many out-of-distribution classes in real-world scenarios, e.g., for screening, triage, and quality control, means that it is often necessary to train single-class models that represent an expected feature distribution, e.g., from only strictly healthy volunteer data. Conventional supervised machine learning would require the collection of datasets that contain enough samples of all possible diseases in every imaging modality, which is not realistic. Self-supervised learning methods with synthetic anomalies are currently amongst the most promising approaches, alongside generative auto-encoders that analyse the residual reconstruction error. However, all methods suffer from a lack of structured validation, which makes calibration for deployment difficult and dataset-dependant. Our method alleviates this by making use of multiple visually-distinct synthetic anomaly learning tasks for both training and validation. This enables more robust training and generalisation. With our approach we can readily outperform state-of-the-art methods, which we demonstrate on exemplars in brain MRI and chest X-rays. Code is available at https://github.com/matt-baugh/many-tasks-make-light-work .
Zero-Shot Anomaly Detection with Pre-trained Segmentation Models
Jun 15, 2023This technical report outlines our submission to the zero-shot track of the Visual Anomaly and Novelty Detection (VAND) 2023 Challenge. Building on the performance of the WINCLIP framework, we aim to enhance the system's localization capabilities by integrating zero-shot segmentation models. In addition, we perform foreground instance segmentation which enables the model to focus on the relevant parts of the image, thus allowing the models to better identify small or subtle deviations. Our pipeline requires no external data or information, allowing for it to be directly applied to new datasets. Our team (Variance Vigilance Vanguard) ranked third in the zero-shot track of the VAND challenge, and achieve an average F1-max score of 81.5/24.2 at a sample/pixel level on the VisA dataset.
Pay Attention: Accuracy Versus Interpretability Trade-off in Fine-tuned Diffusion Models
Mar 31, 2023



The recent progress of diffusion models in terms of image quality has led to a major shift in research related to generative models. Current approaches often fine-tune pre-trained foundation models using domain-specific text-to-image pairs. This approach is straightforward for X-ray image generation due to the high availability of radiology reports linked to specific images. However, current approaches hardly ever look at attention layers to verify whether the models understand what they are generating. In this paper, we discover an important trade-off between image fidelity and interpretability in generative diffusion models. In particular, we show that fine-tuning text-to-image models with learnable text encoder leads to a lack of interpretability of diffusion models. Finally, we demonstrate the interpretability of diffusion models by showing that keeping the language encoder frozen, enables diffusion models to achieve state-of-the-art phrase grounding performance on certain diseases for a challenging multi-label segmentation task, without any additional training. Code and models will be available at https://github.com/MischaD/chest-distillation.
Confidence-Aware and Self-Supervised Image Anomaly Localisation
Mar 23, 2023Universal anomaly detection still remains a challenging problem in machine learning and medical image analysis. It is possible to learn an expected distribution from a single class of normative samples, e.g., through epistemic uncertainty estimates, auto-encoding models, or from synthetic anomalies in a self-supervised way. The performance of self-supervised anomaly detection approaches is still inferior compared to methods that use examples from known unknown classes to shape the decision boundary. However, outlier exposure methods often do not identify unknown unknowns. Here we discuss an improved self-supervised single-class training strategy that supports the approximation of probabilistic inference with loosen feature locality constraints. We show that up-scaling of gradients with histogram-equalised images is beneficial for recently proposed self-supervision tasks. Our method is integrated into several out-of-distribution (OOD) detection models and we show evidence that our method outperforms the state-of-the-art on various benchmark datasets. Source code will be publicly available by the time of the conference.