 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection of Diseases in the Female Pelvis for Real-Time MR Imaging
Feb 05, 2026Pelvic diseases in women of reproductive age represent a major global health burden, with diagnosis frequently delayed due to high anatomical variability, complicating MRI interpretation. Existing AI approaches are largely disease-specific and lack real-time compatibility, limiting generalizability and clinical integration. To address these challenges, we establish a benchmark framework for disease- and parameter-agnostic, real-time-compatible unsupervised anomaly detection in pelvic MRI. The method uses a residual variational autoencoder trained exclusively on healthy sagittal T2-weighted scans acquired across diverse imaging protocols to model normal pelvic anatomy. During inference, reconstruction error heatmaps indicate deviations from learned healthy structure, enabling detection of pathological regions without labeled abnormal data. The model is trained on 294 healthy scans and augmented with diffusion-generated synthetic data to improve robustness. Quantitative evaluation on the publicly available Uterine Myoma MRI Dataset yields an average area-under-the-curve (AUC) value of 0.736, with 0.828 sensitivity and 0.692 specificity. Additional inter-observer clinical evaluation extends analysis to endometrial cancer, endometriosis, and adenomyosis, revealing the influence of anatomical heterogeneity and inter-observer variability on performance interpretation. With a reconstruction time of approximately 92.6 frames per second, the proposed framework establishes a baseline for unsupervised anomaly detection in the female pelvis and supports future integration into real-time MRI. Code is available upon request (https://github.com/AniKnu/UADPelvis), prospective data sets are available for academic collaboration.
Diffusing the Blind Spot: Uterine MRI Synthesis with Diffusion Models
Aug 11, 2025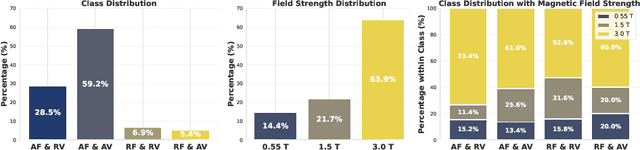
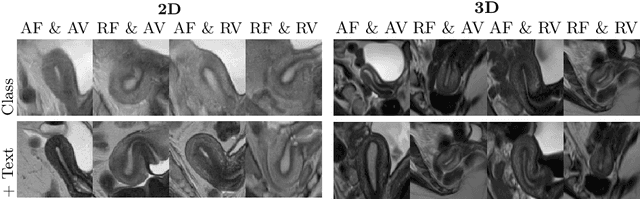
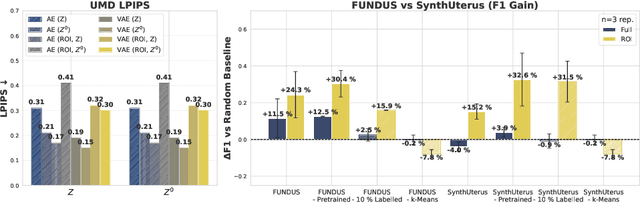
Despite significant progress in generative modelling, existing diffusion models often struggle to produce anatomically precise female pelvic images, limiting their application in gynaecological imaging, where data scarcity and patient privacy concerns are critical. To overcome these barriers, we introduce a novel diffusion-based framework for uterine MRI synthesis, integrating both unconditional and conditioned Denoising Diffusion Probabilistic Models (DDPMs) and Latent Diffusion Models (LDMs) in 2D and 3D. Our approach generates anatomically coherent, high fidelity synthetic images that closely mimic real scans and provide valuable resources for training robust diagnostic models. We evaluate generative quality using advanced perceptual and distributional metrics, benchmarking against standard reconstruction methods, and demonstrate substantial gains in diagnostic accuracy on a key classification task. A blinded expert evaluation further validates the clinical realism of our synthetic images. We release our models with privacy safeguards and a comprehensive synthetic uterine MRI dataset to support reproducible research and advance equitable AI in gynaecology.
L-FUSION: Laplacian Fetal Ultrasound Segmentation & Uncertainty Estimation
Mar 07, 2025

Accurate analysis of prenatal ultrasound (US) is essential for early detection of developmental anomalies. However, operator dependency and technical limitations (e.g. intrinsic artefacts and effects, setting errors) can complicate image interpretation and the assessment of diagnostic uncertainty. We present L-FUSION (Laplacian Fetal US Segmentation with Integrated FoundatiON models), a framework that integrates uncertainty quantification through unsupervised, normative learning and large-scale foundation models for robust segmentation of fetal structures in normal and pathological scans. We propose to utilise the aleatoric logit distributions of Stochastic Segmentation Networks and Laplace approximations with fast Hessian estimations to estimate epistemic uncertainty only from the segmentation head. This enables us to achieve reliable abnormality quantification for instant diagnostic feedback. Combined with an integrated Dropout component, L-FUSION enables reliable differentiation of lesions from normal fetal anatomy with enhanced uncertainty maps and segmentation counterfactuals in US imaging. It improves epistemic and aleatoric uncertainty interpretation and removes the need for manual disease-labelling. Evaluations across multiple datasets show that L-FUSION achieves superior segmentation accuracy and consistent uncertainty quantification, supporting on-site decision-making and offering a scalable solution for advancing fetal ultrasound analysis in clinical settings.
Resource-efficient Medical Image Analysis with Self-adapting Forward-Forward Networks
Jun 20, 2024



We introduce a fast Self-adapting Forward-Forward Network (SaFF-Net) for medical imaging analysis, mitigating power consumption and resource limitations, which currently primarily stem from the prevalent reliance on back-propagation for model training and fine-tuning. Building upon the recently proposed Forward-Forward Algorithm (FFA), we introduce the Convolutional Forward-Forward Algorithm (CFFA), a parameter-efficient reformulation that is suitable for advanced image analysis and overcomes the speed and generalisation constraints of the original FFA. To address hyper-parameter sensitivity of FFAs we are also introducing a self-adapting framework SaFF-Net fine-tuning parameters during warmup and training in parallel. Our approach enables more effective model training and eliminates the previously essential requirement for an arbitrarily chosen Goodness function in FFA. We evaluate our approach on several benchmarking datasets in comparison with standard Back-Propagation (BP) neural networks showing that FFA-based networks with notably fewer parameters and function evaluations can compete with standard models, especially, in one-shot scenarios and large batch sizes. The code will be available at the time of the conference.
Whole Slide Multiple Instance Learning for Predicting Axillary Lymph Node Metastasis
Oct 06, 2023Breast cancer is a major concern for women's health globally, with axillary lymph node (ALN) metastasis identification being critical for prognosis evaluation and treatment guidance. This paper presents a deep learning (DL) classification pipeline for quantifying clinical information from digital core-needle biopsy (CNB) images, with one step less than existing methods. A publicly available dataset of 1058 patients was used to evaluate the performance of different baseline state-of-the-art (SOTA) DL models in classifying ALN metastatic status based on CNB images. An extensive ablation study of various data augmentation techniques was also conducted. Finally, the manual tumor segmentation and annotation step performed by the pathologists was assessed.
* Accepted for MICCAI DEMI Workshop 2023
Many tasks make light work: Learning to localise medical anomalies from multiple synthetic tasks
Jul 03, 2023There is a growing interest in single-class modelling and out-of-distribution detection as fully supervised machine learning models cannot reliably identify classes not included in their training. The long tail of infinitely many out-of-distribution classes in real-world scenarios, e.g., for screening, triage, and quality control, means that it is often necessary to train single-class models that represent an expected feature distribution, e.g., from only strictly healthy volunteer data. Conventional supervised machine learning would require the collection of datasets that contain enough samples of all possible diseases in every imaging modality, which is not realistic. Self-supervised learning methods with synthetic anomalies are currently amongst the most promising approaches, alongside generative auto-encoders that analyse the residual reconstruction error. However, all methods suffer from a lack of structured validation, which makes calibration for deployment difficult and dataset-dependant. Our method alleviates this by making use of multiple visually-distinct synthetic anomaly learning tasks for both training and validation. This enables more robust training and generalisation. With our approach we can readily outperform state-of-the-art methods, which we demonstrate on exemplars in brain MRI and chest X-rays. Code is available at https://github.com/matt-baugh/many-tasks-make-light-work .
Zero-Shot Anomaly Detection with Pre-trained Segmentation Models
Jun 15, 2023This technical report outlines our submission to the zero-shot track of the Visual Anomaly and Novelty Detection (VAND) 2023 Challenge. Building on the performance of the WINCLIP framework, we aim to enhance the system's localization capabilities by integrating zero-shot segmentation models. In addition, we perform foreground instance segmentation which enables the model to focus on the relevant parts of the image, thus allowing the models to better identify small or subtle deviations. Our pipeline requires no external data or information, allowing for it to be directly applied to new datasets. Our team (Variance Vigilance Vanguard) ranked third in the zero-shot track of the VAND challenge, and achieve an average F1-max score of 81.5/24.2 at a sample/pixel level on the VisA dataset.
Pay Attention: Accuracy Versus Interpretability Trade-off in Fine-tuned Diffusion Models
Mar 31, 2023



The recent progress of diffusion models in terms of image quality has led to a major shift in research related to generative models. Current approaches often fine-tune pre-trained foundation models using domain-specific text-to-image pairs. This approach is straightforward for X-ray image generation due to the high availability of radiology reports linked to specific images. However, current approaches hardly ever look at attention layers to verify whether the models understand what they are generating. In this paper, we discover an important trade-off between image fidelity and interpretability in generative diffusion models. In particular, we show that fine-tuning text-to-image models with learnable text encoder leads to a lack of interpretability of diffusion models. Finally, we demonstrate the interpretability of diffusion models by showing that keeping the language encoder frozen, enables diffusion models to achieve state-of-the-art phrase grounding performance on certain diseases for a challenging multi-label segmentation task, without any additional training. Code and models will be available at https://github.com/MischaD/chest-distillation.
Confidence-Aware and Self-Supervised Image Anomaly Localisation
Mar 23, 2023Universal anomaly detection still remains a challenging problem in machine learning and medical image analysis. It is possible to learn an expected distribution from a single class of normative samples, e.g., through epistemic uncertainty estimates, auto-encoding models, or from synthetic anomalies in a self-supervised way. The performance of self-supervised anomaly detection approaches is still inferior compared to methods that use examples from known unknown classes to shape the decision boundary. However, outlier exposure methods often do not identify unknown unknowns. Here we discuss an improved self-supervised single-class training strategy that supports the approximation of probabilistic inference with loosen feature locality constraints. We show that up-scaling of gradients with histogram-equalised images is beneficial for recently proposed self-supervision tasks. Our method is integrated into several out-of-distribution (OOD) detection models and we show evidence that our method outperforms the state-of-the-art on various benchmark datasets. Source code will be publicly available by the time of the conference.
nnOOD: A Framework for Benchmarking Self-supervised Anomaly Localisation Methods
Sep 02, 2022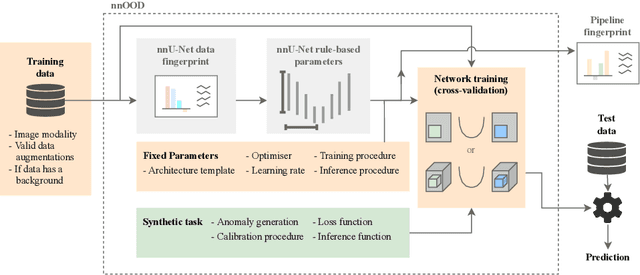

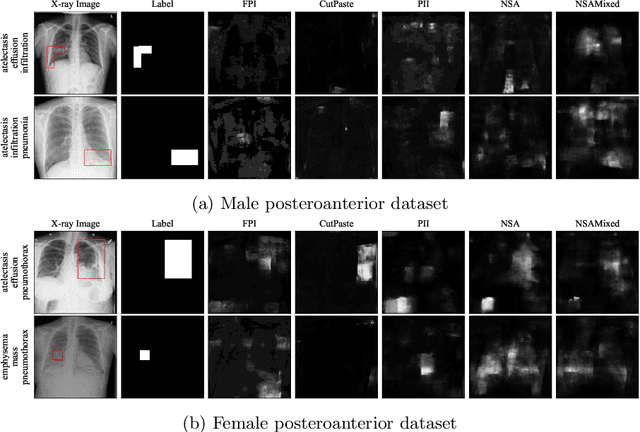
The wide variety of in-distribution and out-of-distribution data in medical imaging makes universal anomaly detection a challenging task. Recently a number of self-supervised methods have been developed that train end-to-end models on healthy data augmented with synthetic anomalies. However, it is difficult to compare these methods as it is not clear whether gains in performance are from the task itself or the training pipeline around it. It is also difficult to assess whether a task generalises well for universal anomaly detection, as they are often only tested on a limited range of anomalies. To assist with this we have developed nnOOD, a framework that adapts nnU-Net to allow for comparison of self-supervised anomaly localisation methods. By isolating the synthetic, self-supervised task from the rest of the training process we perform a more faithful comparison of the tasks, whilst also making the workflow for evaluating over a given dataset quick and easy. Using this we have implemented the current state-of-the-art tasks and evaluated them on a challenging X-ray dataset.