 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Representations of Vessel Trees
Jun 11, 2025We introduce a novel framework for learning vector representations of tree-structured geometric data focusing on 3D vascular networks. Our approach employs two sequentially trained Transformer-based autoencoders. In the first stage, the Vessel Autoencoder captures continuous geometric details of individual vessel segments by learning embeddings from sampled points along each curve. In the second stage, the Vessel Tree Autoencoder encodes the topology of the vascular network as a single vector representation, leveraging the segment-level embeddings from the first model. A recursive decoding process ensures that the reconstructed topology is a valid tree structure. Compared to 3D convolutional models, this proposed approach substantially lowers GPU memory requirements, facilitating large-scale training. Experimental results on a 2D synthetic tree dataset and a 3D coronary artery dataset demonstrate superior reconstruction fidelity, accurate topology preservation, and realistic interpolations in latent space. Our scalable framework, named VeTTA, offers precise, flexible, and topologically consistent modeling of anatomical tree structures in medical imaging.
Many tasks make light work: Learning to localise medical anomalies from multiple synthetic tasks
Jul 03, 2023There is a growing interest in single-class modelling and out-of-distribution detection as fully supervised machine learning models cannot reliably identify classes not included in their training. The long tail of infinitely many out-of-distribution classes in real-world scenarios, e.g., for screening, triage, and quality control, means that it is often necessary to train single-class models that represent an expected feature distribution, e.g., from only strictly healthy volunteer data. Conventional supervised machine learning would require the collection of datasets that contain enough samples of all possible diseases in every imaging modality, which is not realistic. Self-supervised learning methods with synthetic anomalies are currently amongst the most promising approaches, alongside generative auto-encoders that analyse the residual reconstruction error. However, all methods suffer from a lack of structured validation, which makes calibration for deployment difficult and dataset-dependant. Our method alleviates this by making use of multiple visually-distinct synthetic anomaly learning tasks for both training and validation. This enables more robust training and generalisation. With our approach we can readily outperform state-of-the-art methods, which we demonstrate on exemplars in brain MRI and chest X-rays. Code is available at https://github.com/matt-baugh/many-tasks-make-light-work .
Zero-Shot Anomaly Detection with Pre-trained Segmentation Models
Jun 15, 2023This technical report outlines our submission to the zero-shot track of the Visual Anomaly and Novelty Detection (VAND) 2023 Challenge. Building on the performance of the WINCLIP framework, we aim to enhance the system's localization capabilities by integrating zero-shot segmentation models. In addition, we perform foreground instance segmentation which enables the model to focus on the relevant parts of the image, thus allowing the models to better identify small or subtle deviations. Our pipeline requires no external data or information, allowing for it to be directly applied to new datasets. Our team (Variance Vigilance Vanguard) ranked third in the zero-shot track of the VAND challenge, and achieve an average F1-max score of 81.5/24.2 at a sample/pixel level on the VisA dataset.
Image To Tree with Recursive Prompting
Jan 01, 2023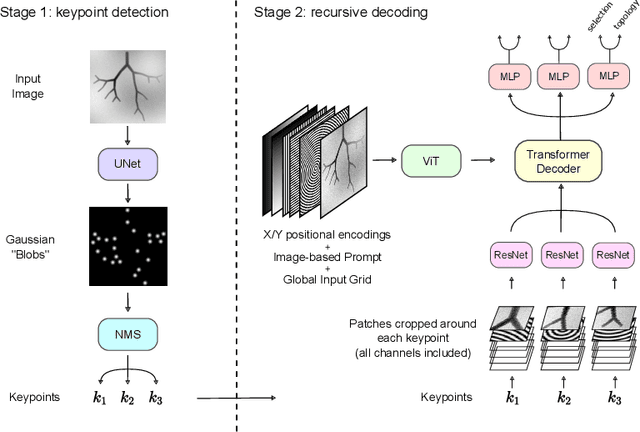
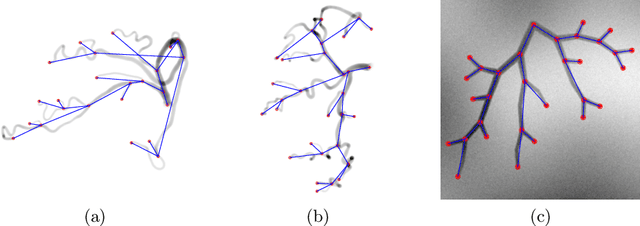

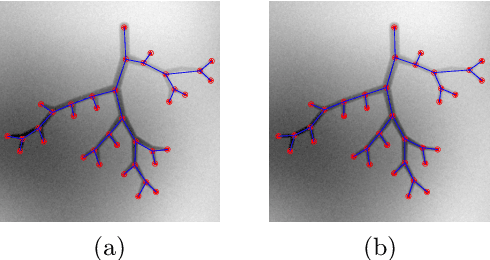
Extracting complex structures from grid-based data is a common key step in automated medical image analysis. The conventional solution to recovering tree-structured geometries typically involves computing the minimal cost path through intermediate representations derived from segmentation masks. However, this methodology has significant limitations in the context of projective imaging of tree-structured 3D anatomical data such as coronary arteries, since there are often overlapping branches in the 2D projection. In this work, we propose a novel approach to predicting tree connectivity structure which reformulates the task as an optimization problem over individual steps of a recursive process. We design and train a two-stage model which leverages the UNet and Transformer architectures and introduces an image-based prompting technique. Our proposed method achieves compelling results on a pair of synthetic datasets, and outperforms a shortest-path baseline.
Atlas-ISTN: Joint Segmentation, Registration and Atlas Construction with Image-and-Spatial Transformer Networks
Dec 18, 2020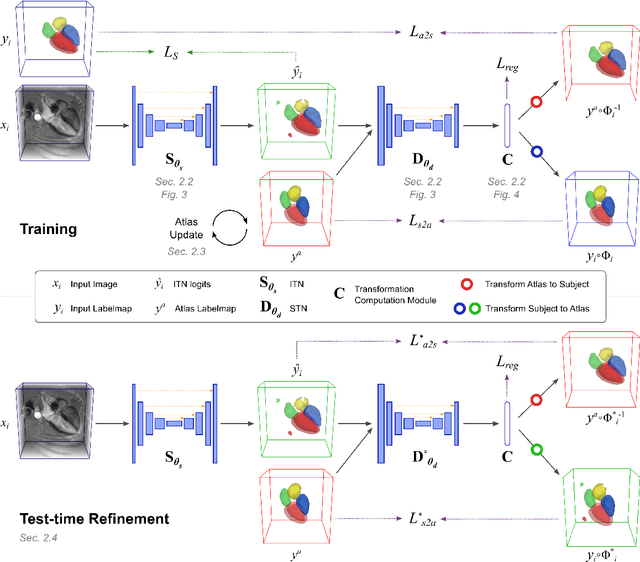
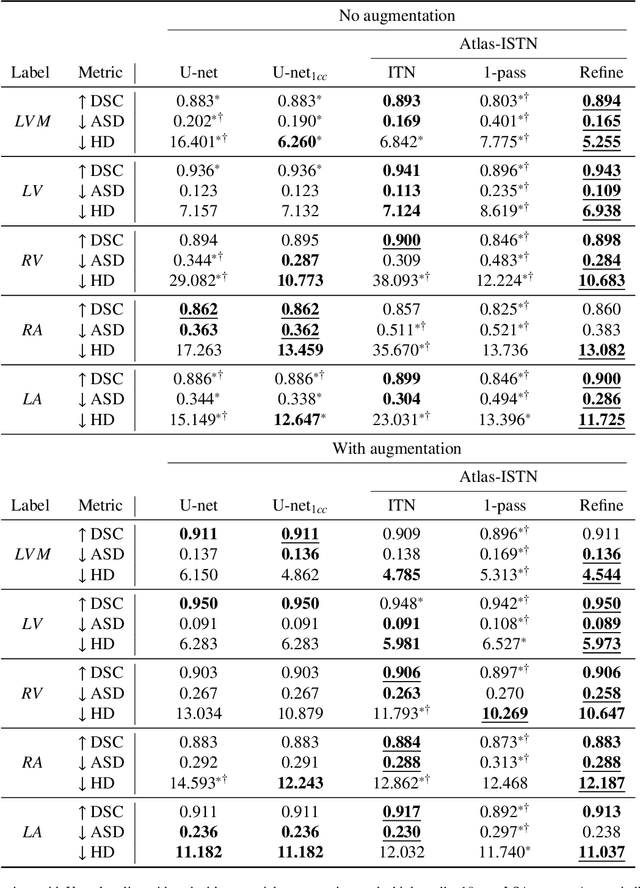
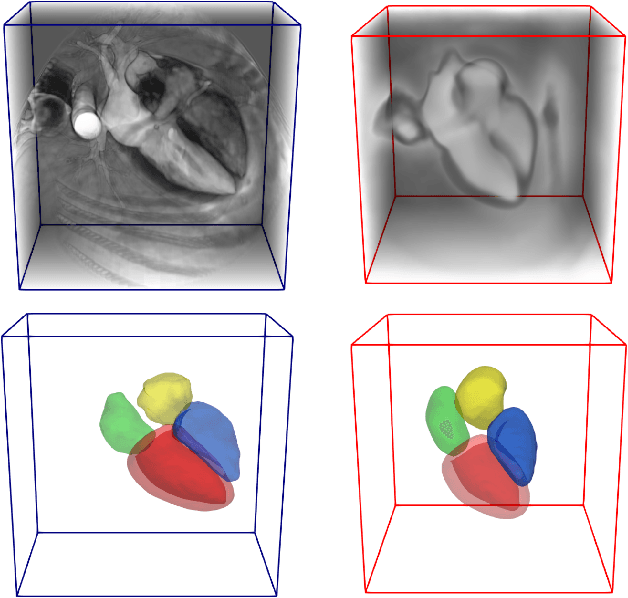
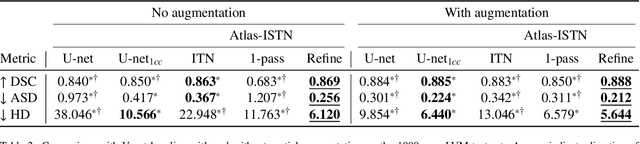
Deep learning models for semantic segmentation are able to learn powerful representations for pixel-wise predictions, but are sensitive to noise at test time and do not guarantee a plausible topology. Image registration models on the other hand are able to warp known topologies to target images as a means of segmentation, but typically require large amounts of training data, and have not widely been benchmarked against pixel-wise segmentation models. We propose Atlas-ISTN, a framework that jointly learns segmentation and registration on 2D and 3D image data, and constructs a population-derived atlas in the process. Atlas-ISTN learns to segment multiple structures of interest and to register the constructed, topologically consistent atlas labelmap to an intermediate pixel-wise segmentation. Additionally, Atlas-ISTN allows for test time refinement of the model's parameters to optimize the alignment of the atlas labelmap to an intermediate pixel-wise segmentation. This process both mitigates for noise in the target image that can result in spurious pixel-wise predictions, as well as improves upon the one-pass prediction of the model. Benefits of the Atlas-ISTN framework are demonstrated qualitatively and quantitatively on 2D synthetic data and 3D cardiac computed tomography and brain magnetic resonance image data, out-performing both segmentation and registration baseline models. Atlas-ISTN also provides inter-subject correspondence of the structures of interest, enabling population-level shape and motion analysis.
Detecting Outliers with Foreign Patch Interpolation
Nov 09, 2020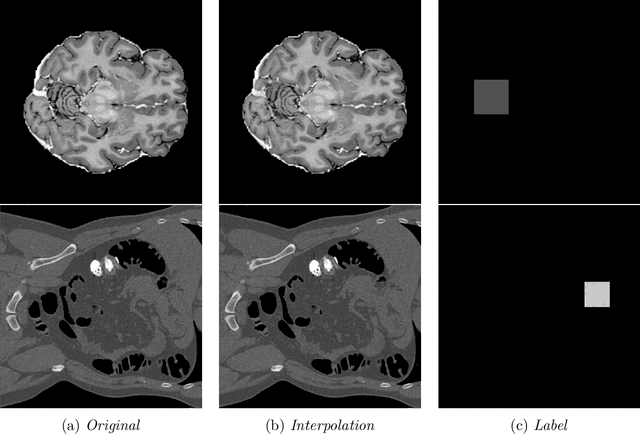
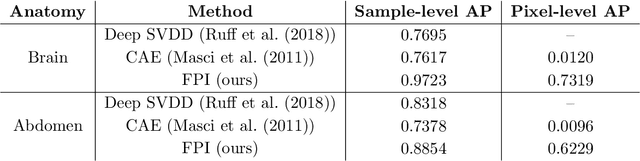
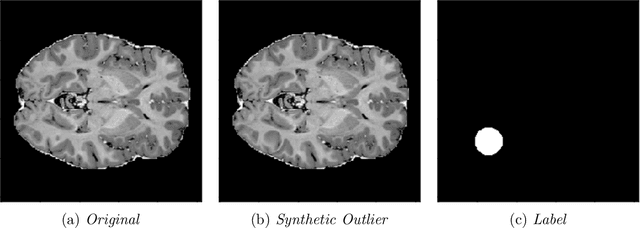
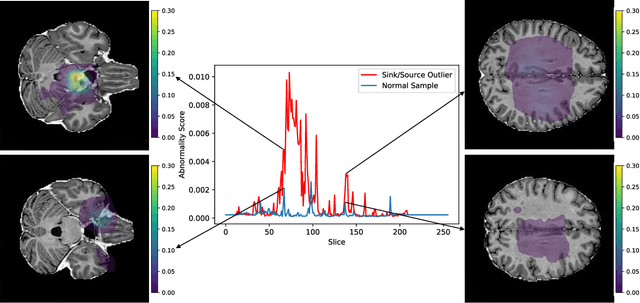
In medical imaging, outliers can contain hypo/hyper-intensities, minor deformations, or completely altered anatomy. To detect these irregularities it is helpful to learn the features present in both normal and abnormal images. However this is difficult because of the wide range of possible abnormalities and also the number of ways that normal anatomy can vary naturally. As such, we leverage the natural variations in normal anatomy to create a range of synthetic abnormalities. Specifically, the same patch region is extracted from two independent samples and replaced with an interpolation between both patches. The interpolation factor, patch size, and patch location are randomly sampled from uniform distributions. A wide residual encoder decoder is trained to give a pixel-wise prediction of the patch and its interpolation factor. This encourages the network to learn what features to expect normally and to identify where foreign patterns have been introduced. The estimate of the interpolation factor lends itself nicely to the derivation of an outlier score. Meanwhile the pixel-wise output allows for pixel- and subject- level predictions using the same model.