 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Stress Testing for Image Classification Models
May 11, 2026Deep learning models in medical imaging often fail when deployed in new clinical environments due to distribution shifts in demographics, scanner hardware, or acquisition protocols. A central challenge is underspecification, where models with similar validation performance exhibit divergent real-world failure modes. Although stress testing has emerged as a tool to assess this, current methods typically rely on simple, uninformed perturbations (e.g., brightness or contrast changes), which fail to capture clinically realistic variation and can overestimate robustness. In this work, we introduce a counterfactual stress testing framework based on causal generative models that create realistic "what if" images by intervening on attributes such as scanner type and patient sex while preserving anatomical identity, enabling controlled and semantically meaningful evaluation under targeted distribution shifts. Across two imaging modalities (chest X-ray and mammography), three model architectures, and multiple shift scenarios, we show that counterfactual stress tests provide a substantially more accurate proxy for real out-of-distribution performance than classical perturbations, capturing the direction and relative magnitude of performance changes as well as model ranking. These results suggest that causal generative models can serve as practical simulators for robustness assessment, offering a more reliable basis for evaluating medical AI systems prior to deployment.
Positional Segmentor-Guided Counterfactual Fine-Tuning for Spatially Localized Image Synthesis
Mar 22, 2026Counterfactual image generation enables controlled data augmentation, bias mitigation, and disease modeling. However, existing methods guided by external classifiers or regressors are limited to subject-level factors (e.g., age) and fail to produce localized structural changes, often resulting in global artifacts. Pixel-level guidance using segmentation masks has been explored, but requires user-defined counterfactual masks, which are tedious and impractical. Segmentor-guided Counterfactual Fine-Tuning (Seg-CFT) addressed this by using segmentation-derived measurements to supervise structure-specific variables, yet it remains restricted to global interventions. We propose Positional Seg-CFT, which subdivides each structure into regional segments and derives independent measurements per region, enabling spatially localized and anatomically coherent counterfactuals. Experiments on coronary CT angiography show that Pos-Seg-CFT generates realistic, region-specific modifications, providing finer spatial control for modeling disease progression.
Pixel-level Counterfactual Contrastive Learning for Medical Image Segmentation
Mar 17, 2026Image segmentation relies on large annotated datasets, which are expensive and slow to produce. Silver-standard (AI-generated) labels are easier to obtain, but they risk introducing bias. Self-supervised learning, needing only images, has become key for pre-training. Recent work combining contrastive learning with counterfactual generation improves representation learning for classification but does not readily extend to pixel-level tasks. We propose a pipeline combining counterfactual generation with dense contrastive learning via Dual-View (DVD-CL) and Multi-View (MVD-CL) methods, along with supervised variants that utilize available silver-standard annotations. A new visualisation algorithm, the Color-coded High Resolution Overlay map (CHRO-map) is also introduced. Experiments show annotation-free DVD-CL outperforms other dense contrastive learning methods, while supervised variants using silver-standard labels outperform training on the silver-standard labeled data directly, achieving $\sim$94% DSC on challenging data. These results highlight that pixel-level contrastive learning, enhanced by counterfactuals and silver-standard annotations, improves robustness to acquisition and pathological variations.
A Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
A Primer on Causal and Statistical Dataset Biases for Fair and Robust Image Analysis
Sep 04, 2025Machine learning methods often fail when deployed in the real world. Worse still, they fail in high-stakes situations and across socially sensitive lines. These issues have a chilling effect on the adoption of machine learning methods in settings such as medical diagnosis, where they are arguably best-placed to provide benefits if safely deployed. In this primer, we introduce the causal and statistical structures which induce failure in machine learning methods for image analysis. We highlight two previously overlooked problems, which we call the \textit{no fair lunch} problem and the \textit{subgroup separability} problem. We elucidate why today's fair representation learning methods fail to adequately solve them and propose potential paths forward for the field.
Exploring the interplay of label bias with subgroup size and separability: A case study in mammographic density classification
Jul 24, 2025Systematic mislabelling affecting specific subgroups (i.e., label bias) in medical imaging datasets represents an understudied issue concerning the fairness of medical AI systems. In this work, we investigated how size and separability of subgroups affected by label bias influence the learned features and performance of a deep learning model. Therefore, we trained deep learning models for binary tissue density classification using the EMory BrEast imaging Dataset (EMBED), where label bias affected separable subgroups (based on imaging manufacturer) or non-separable "pseudo-subgroups". We found that simulated subgroup label bias led to prominent shifts in the learned feature representations of the models. Importantly, these shifts within the feature space were dependent on both the relative size and the separability of the subgroup affected by label bias. We also observed notable differences in subgroup performance depending on whether a validation set with clean labels was used to define the classification threshold for the model. For instance, with label bias affecting the majority separable subgroup, the true positive rate for that subgroup fell from 0.898, when the validation set had clean labels, to 0.518, when the validation set had biased labels. Our work represents a key contribution toward understanding the consequences of label bias on subgroup fairness in medical imaging AI.
Where are we with calibration under dataset shift in image classification?
Jul 10, 2025
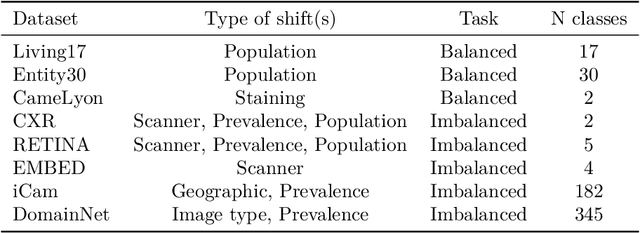

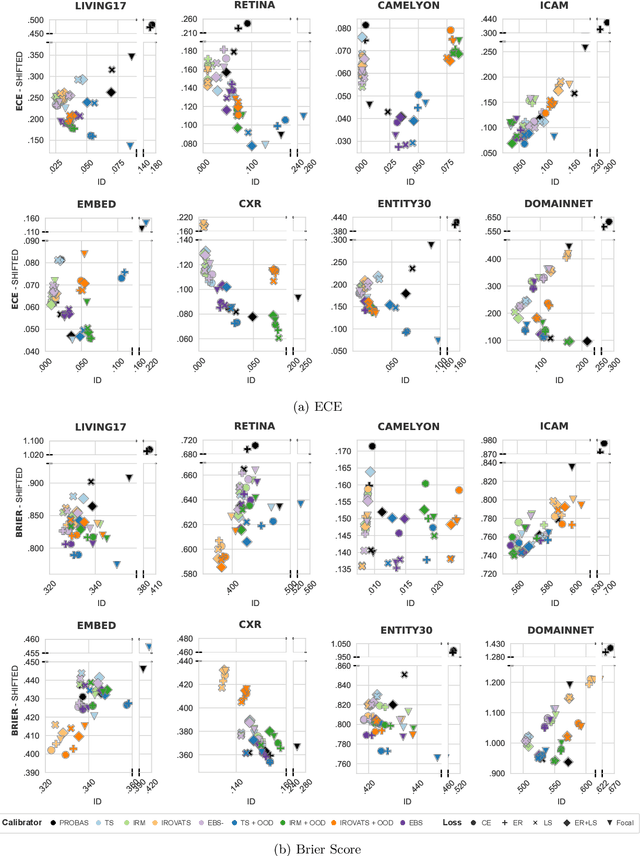
We conduct an extensive study on the state of calibration under real-world dataset shift for image classification. Our work provides important insights on the choice of post-hoc and in-training calibration techniques, and yields practical guidelines for all practitioners interested in robust calibration under shift. We compare various post-hoc calibration methods, and their interactions with common in-training calibration strategies (e.g., label smoothing), across a wide range of natural shifts, on eight different classification tasks across several imaging domains. We find that: (i) simultaneously applying entropy regularisation and label smoothing yield the best calibrated raw probabilities under dataset shift, (ii) post-hoc calibrators exposed to a small amount of semantic out-of-distribution data (unrelated to the task) are most robust under shift, (iii) recent calibration methods specifically aimed at increasing calibration under shifts do not necessarily offer significant improvements over simpler post-hoc calibration methods, (iv) improving calibration under shifts often comes at the cost of worsening in-distribution calibration. Importantly, these findings hold for randomly initialised classifiers, as well as for those finetuned from foundation models, the latter being consistently better calibrated compared to models trained from scratch. Finally, we conduct an in-depth analysis of ensembling effects, finding that (i) applying calibration prior to ensembling (instead of after) is more effective for calibration under shifts, (ii) for ensembles, OOD exposure deteriorates the ID-shifted calibration trade-off, (iii) ensembling remains one of the most effective methods to improve calibration robustness and, combined with finetuning from foundation models, yields best calibration results overall.
Decoupled Classifier-Free Guidance for Counterfactual Diffusion Models
Jun 17, 2025Counterfactual image generation aims to simulate realistic visual outcomes under specific causal interventions. Diffusion models have recently emerged as a powerful tool for this task, combining DDIM inversion with conditional generation via classifier-free guidance (CFG). However, standard CFG applies a single global weight across all conditioning variables, which can lead to poor identity preservation and spurious attribute changes - a phenomenon known as attribute amplification. To address this, we propose Decoupled Classifier-Free Guidance (DCFG), a flexible and model-agnostic framework that introduces group-wise conditioning control. DCFG builds on an attribute-split embedding strategy that disentangles semantic inputs, enabling selective guidance on user-defined attribute groups. For counterfactual generation, we partition attributes into intervened and invariant sets based on a causal graph and apply distinct guidance to each. Experiments on CelebA-HQ, MIMIC-CXR, and EMBED show that DCFG improves intervention fidelity, mitigates unintended changes, and enhances reversibility, enabling more faithful and interpretable counterfactual image generation.
Object-Centric Neuro-Argumentative Learning
Jun 17, 2025Over the last decade, as we rely more on deep learning technologies to make critical decisions, concerns regarding their safety, reliability and interpretability have emerged. We introduce a novel Neural Argumentative Learning (NAL) architecture that integrates Assumption-Based Argumentation (ABA) with deep learning for image analysis. Our architecture consists of neural and symbolic components. The former segments and encodes images into facts using object-centric learning, while the latter applies ABA learning to develop ABA frameworks enabling predictions with images. Experiments on synthetic data show that the NAL architecture can be competitive with a state-of-the-art alternative.
Vector Representations of Vessel Trees
Jun 11, 2025We introduce a novel framework for learning vector representations of tree-structured geometric data focusing on 3D vascular networks. Our approach employs two sequentially trained Transformer-based autoencoders. In the first stage, the Vessel Autoencoder captures continuous geometric details of individual vessel segments by learning embeddings from sampled points along each curve. In the second stage, the Vessel Tree Autoencoder encodes the topology of the vascular network as a single vector representation, leveraging the segment-level embeddings from the first model. A recursive decoding process ensures that the reconstructed topology is a valid tree structure. Compared to 3D convolutional models, this proposed approach substantially lowers GPU memory requirements, facilitating large-scale training. Experimental results on a 2D synthetic tree dataset and a 3D coronary artery dataset demonstrate superior reconstruction fidelity, accurate topology preservation, and realistic interpolations in latent space. Our scalable framework, named VeTTA, offers precise, flexible, and topologically consistent modeling of anatomical tree structures in medical imaging.