 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM-Generated Text Empower Surgical Vision-Language Pre-training?
Apr 20, 2026Recent advancements in self-supervised learning have led to powerful surgical vision encoders capable of spatiotemporal understanding. However, extending these visual foundations to multi-modal reasoning tasks is severely bottlenecked by the prohibitive cost of expert textual annotations. To overcome this scalability limitation, we introduce \textbf{LIME}, a large-scale multi-modal dataset derived from open-access surgical videos using human-free, Large Language Model (LLM)-generated narratives. While LIME offers immense scalability, unverified generated texts may contain errors, including hallucinations, that could potentially lead to catastrophically degraded pre-trained medical priors in standard contrastive pipelines. To mitigate this, we propose \textbf{SurgLIME}, a parameter-efficient Vision-Language Pre-training (VLP) framework designed to learn reliable cross-modal alignments using noisy narratives. SurgLIME preserves foundational medical priors using a LoRA-adapted dual-encoder architecture and introduces an automated confidence estimation mechanism that dynamically down-weights uncertain text during contrastive alignment. Evaluations on the AutoLaparo and Cholec80 benchmarks show that SurgLIME achieves competitive zero-shot cross-modal alignment while preserving the robust linear probing performance of the visual foundation model. Dataset, code, and models are publicly available at \href{https://github.com/visurg-ai/SurgLIME}{https://github.com/visurg-ai/SurgLIME}.
Average Calibration Losses for Reliable Uncertainty in Medical Image Segmentation
Jun 04, 2025Deep neural networks for medical image segmentation are often overconfident, compromising both reliability and clinical utility. In this work, we propose differentiable formulations of marginal L1 Average Calibration Error (mL1-ACE) as an auxiliary loss that can be computed on a per-image basis. We compare both hard- and soft-binning approaches to directly improve pixel-wise calibration. Our experiments on four datasets (ACDC, AMOS, KiTS, BraTS) demonstrate that incorporating mL1-ACE significantly reduces calibration errors, particularly Average Calibration Error (ACE) and Maximum Calibration Error (MCE), while largely maintaining high Dice Similarity Coefficients (DSCs). We find that the soft-binned variant yields the greatest improvements in calibration, over the Dice plus cross-entropy loss baseline, but often compromises segmentation performance, with hard-binned mL1-ACE maintaining segmentation performance, albeit with weaker calibration improvement. To gain further insight into calibration performance and its variability across an imaging dataset, we introduce dataset reliability histograms, an aggregation of per-image reliability diagrams. The resulting analysis highlights improved alignment between predicted confidences and true accuracies. Overall, our approach not only enhances the trustworthiness of segmentation predictions but also shows potential for safer integration of deep learning methods into clinical workflows. We share our code here: https://github.com/cai4cai/Average-Calibration-Losses
Can Local Representation Alignment RNNs Solve Temporal Tasks?
Apr 18, 2025Recurrent Neural Networks (RNNs) are commonly used for real-time processing, streaming data, and cases where the amount of training samples is limited. Backpropagation Through Time (BPTT) is the predominant algorithm for training RNNs; however, it is frequently criticized for being prone to exploding and vanishing gradients and being biologically implausible. In this paper, we present and evaluate a target propagation-based method for RNNs, which uses local updates and seeks to reduce the said instabilities. Having stable RNN models increases their practical use in a wide range of fields such as natural language processing, time-series forecasting, anomaly detection, control systems, and robotics. The proposed solution uses local representation alignment (LRA). We thoroughly analyze the performance of this method, experiment with normalization and different local error functions, and invalidate certain assumptions about the behavior of this type of learning. Namely, we demonstrate that despite the decomposition of the network into sub-graphs, the model still suffers from vanishing gradients. We also show that gradient clipping as proposed in LRA has little to no effect on network performance. This results in an LRA RNN model that is very difficult to train due to vanishing gradients. We address this by introducing gradient regularization in the direction of the update and demonstrate that this modification promotes gradient flow and meaningfully impacts convergence. We compare and discuss the performance of the algorithm, and we show that the regularized LRA RNN considerably outperforms the unregularized version on three landmark tasks: temporal order, 3-bit temporal order, and random permutation.
Surg-3M: A Dataset and Foundation Model for Perception in Surgical Settings
Mar 25, 2025Advancements in computer-assisted surgical procedures heavily rely on accurate visual data interpretation from camera systems used during surgeries. Traditional open-access datasets focusing on surgical procedures are often limited by their small size, typically consisting of fewer than 100 videos with less than 100K images. To address these constraints, a new dataset called Surg-3M has been compiled using a novel aggregation pipeline that collects high-resolution videos from online sources. Featuring an extensive collection of over 4K surgical videos and more than 3 million high-quality images from multiple procedure types, Surg-3M offers a comprehensive resource surpassing existing alternatives in size and scope, including two novel tasks. To demonstrate the effectiveness of this dataset, we present SurgFM, a self-supervised foundation model pretrained on Surg-3M that achieves impressive results in downstream tasks such as surgical phase recognition, action recognition, and tool presence detection. Combining key components from ConvNeXt, DINO, and an innovative augmented distillation method, SurgFM exhibits exceptional performance compared to specialist architectures across various benchmarks. Our experimental results show that SurgFM outperforms state-of-the-art models in multiple downstream tasks, including significant gains in surgical phase recognition (+8.9pp, +4.7pp, and +3.9pp of Jaccard in AutoLaparo, M2CAI16, and Cholec80), action recognition (+3.1pp of mAP in CholecT50) and tool presence detection (+4.6pp of mAP in Cholec80). Moreover, even when using only half of the data, SurgFM outperforms state-of-the-art models in AutoLaparo and achieves state-of-the-art performance in Cholec80. Both Surg-3M and SurgFM have significant potential to accelerate progress towards developing autonomous robotic surgery systems.
SegMatch: A semi-supervised learning method for surgical instrument segmentation
Aug 09, 2023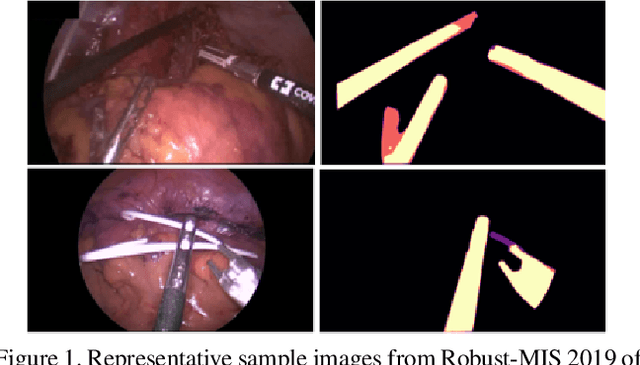
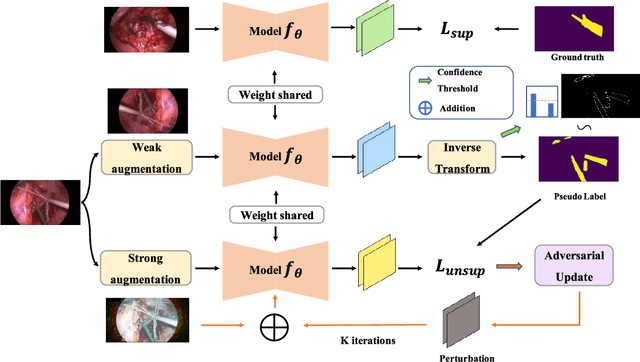
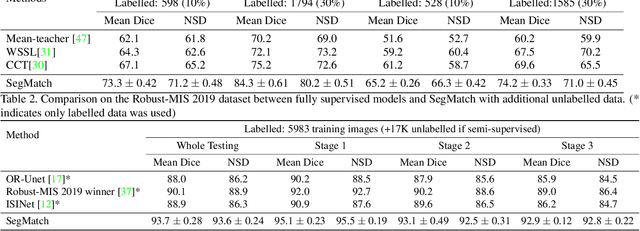
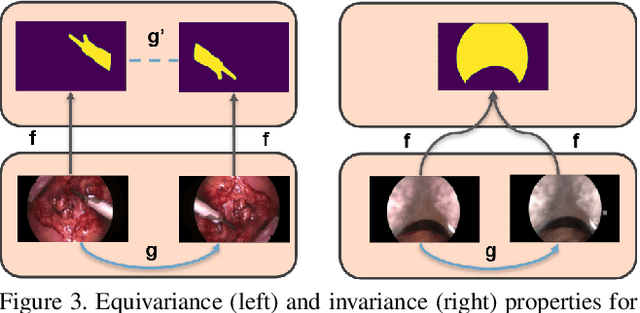
Surgical instrument segmentation is recognised as a key enabler to provide advanced surgical assistance and improve computer assisted interventions. In this work, we propose SegMatch, a semi supervised learning method to reduce the need for expensive annotation for laparoscopic and robotic surgical images. SegMatch builds on FixMatch, a widespread semi supervised classification pipeline combining consistency regularization and pseudo labelling, and adapts it for the purpose of segmentation. In our proposed SegMatch, the unlabelled images are weakly augmented and fed into the segmentation model to generate a pseudo-label to enforce the unsupervised loss against the output of the model for the adversarial augmented image on the pixels with a high confidence score. Our adaptation for segmentation tasks includes carefully considering the equivariance and invariance properties of the augmentation functions we rely on. To increase the relevance of our augmentations, we depart from using only handcrafted augmentations and introduce a trainable adversarial augmentation strategy. Our algorithm was evaluated on the MICCAI Instrument Segmentation Challenge datasets Robust-MIS 2019 and EndoVis 2017. Our results demonstrate that adding unlabelled data for training purposes allows us to surpass the performance of fully supervised approaches which are limited by the availability of training data in these challenges. SegMatch also outperforms a range of state-of-the-art semi-supervised learning semantic segmentation models in different labelled to unlabelled data ratios.
LoViT: Long Video Transformer for Surgical Phase Recognition
May 18, 2023



Online surgical phase recognition plays a significant role towards building contextual tools that could quantify performance and oversee the execution of surgical workflows. Current approaches are limited since they train spatial feature extractors using frame-level supervision that could lead to incorrect predictions due to similar frames appearing at different phases, and poorly fuse local and global features due to computational constraints which can affect the analysis of long videos commonly encountered in surgical interventions. In this paper, we present a two-stage method, called Long Video Transformer (LoViT) for fusing short- and long-term temporal information that combines a temporally-rich spatial feature extractor and a multi-scale temporal aggregator consisting of two cascaded L-Trans modules based on self-attention, followed by a G-Informer module based on ProbSparse self-attention for processing global temporal information. The multi-scale temporal head then combines local and global features and classifies surgical phases using phase transition-aware supervision. Our approach outperforms state-of-the-art methods on the Cholec80 and AutoLaparo datasets consistently. Compared to Trans-SVNet, LoViT achieves a 2.39 pp (percentage point) improvement in video-level accuracy on Cholec80 and a 3.14 pp improvement on AutoLaparo. Moreover, it achieves a 5.25 pp improvement in phase-level Jaccard on AutoLaparo and a 1.55 pp improvement on Cholec80. Our results demonstrate the effectiveness of our approach in achieving state-of-the-art performance of surgical phase recognition on two datasets of different surgical procedures and temporal sequencing characteristics whilst introducing mechanisms that cope with long videos.
Hyperspectral Image Segmentation: A Preliminary Study on the Oral and Dental Spectral Image Database (ODSI-DB)
Mar 14, 2023Visual discrimination of clinical tissue types remains challenging, with traditional RGB imaging providing limited contrast for such tasks. Hyperspectral imaging (HSI) is a promising technology providing rich spectral information that can extend far beyond three-channel RGB imaging. Moreover, recently developed snapshot HSI cameras enable real-time imaging with significant potential for clinical applications. Despite this, the investigation into the relative performance of HSI over RGB imaging for semantic segmentation purposes has been limited, particularly in the context of medical imaging. Here we compare the performance of state-of-the-art deep learning image segmentation methods when trained on hyperspectral images, RGB images, hyperspectral pixels (minus spatial context), and RGB pixels (disregarding spatial context). To achieve this, we employ the recently released Oral and Dental Spectral Image Database (ODSI-DB), which consists of 215 manually segmented dental reflectance spectral images with 35 different classes across 30 human subjects. The recent development of snapshot HSI cameras has made real-time clinical HSI a distinct possibility, though successful application requires a comprehensive understanding of the additional information HSI offers. Our work highlights the relative importance of spectral resolution, spectral range, and spatial information to both guide the development of HSI cameras and inform future clinical HSI applications.
Rapid and robust endoscopic content area estimation: A lean GPU-based pipeline and curated benchmark dataset
Oct 26, 2022Endoscopic content area refers to the informative area enclosed by the dark, non-informative, border regions present in most endoscopic footage. The estimation of the content area is a common task in endoscopic image processing and computer vision pipelines. Despite the apparent simplicity of the problem, several factors make reliable real-time estimation surprisingly challenging. The lack of rigorous investigation into the topic combined with the lack of a common benchmark dataset for this task has been a long-lasting issue in the field. In this paper, we propose two variants of a lean GPU-based computational pipeline combining edge detection and circle fitting. The two variants differ by relying on handcrafted features, and learned features respectively to extract content area edge point candidates. We also present a first-of-its-kind dataset of manually annotated and pseudo-labelled content areas across a range of surgical indications. To encourage further developments, the curated dataset, and an implementation of both algorithms, has been made public (https://doi.org/10.7303/syn32148000, https://github.com/charliebudd/torch-content-area). We compare our proposed algorithm with a state-of-the-art U-Net-based approach and demonstrate significant improvement in terms of both accuracy (Hausdorff distance: 6.3 px versus 118.1 px) and computational time (Average runtime per frame: 0.13 ms versus 11.2 ms).
Autonomous Robotic Endoscope Control based on Semantically Rich Instructions
Jul 05, 2021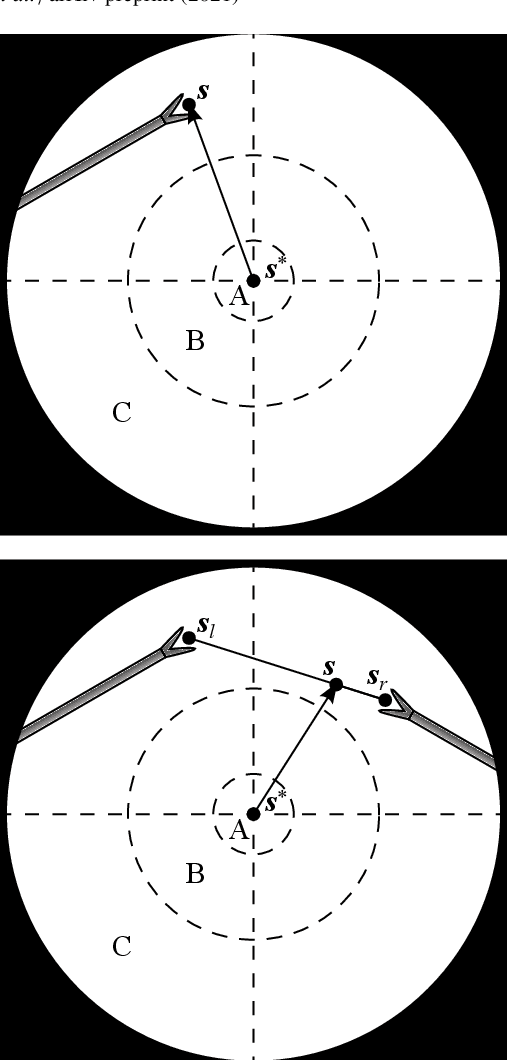
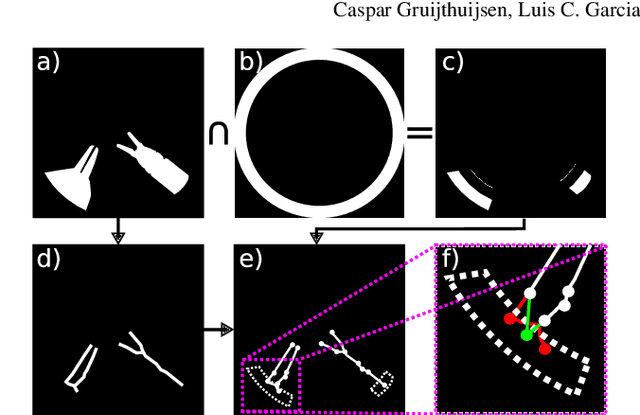
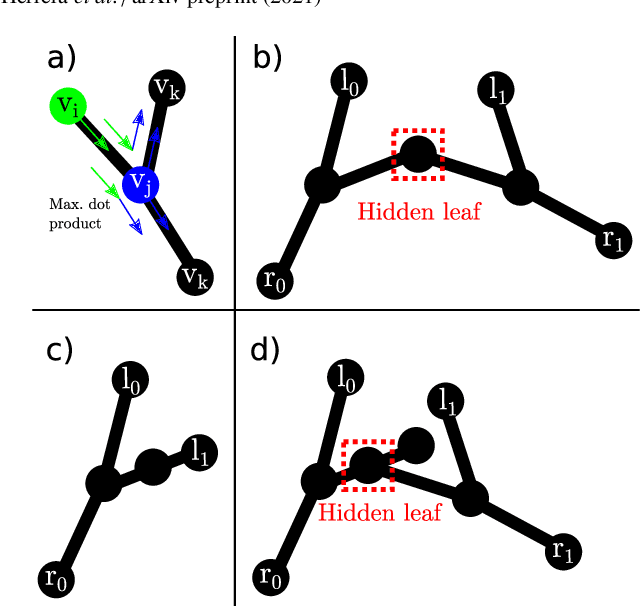
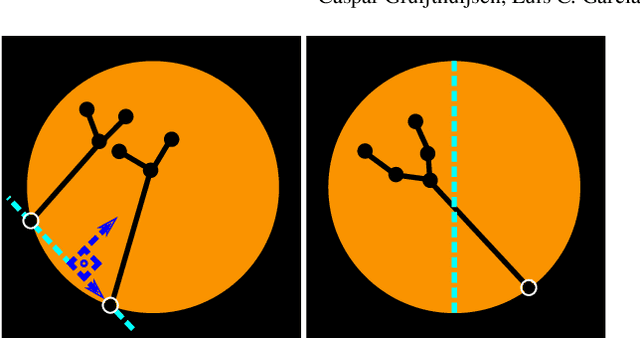
In keyhole interventions, surgeons rely on a colleague to act as a camera assistant when their hands are occupied with surgical instruments. This often leads to reduced image stability, increased task completion times and sometimes errors. Robotic endoscope holders (REHs), controlled by a set of basic instructions, have been proposed as an alternative, but their unnatural handling increases the cognitive load of the surgeon, hindering their widespread clinical acceptance. We propose that REHs collaborate with the operating surgeon via semantically rich instructions that closely resemble those issued to a human camera assistant, such as "focus on my right-hand instrument". As a proof-of-concept, we present a novel system that paves the way towards a synergistic interaction between surgeons and REHs. The proposed platform allows the surgeon to perform a bi-manual coordination and navigation task, while a robotic arm autonomously performs various endoscope positioning tasks. Within our system, we propose a novel tooltip localization method based on surgical tool segmentation, and a novel visual servoing approach that ensures smooth and correct motion of the endoscope camera. We validate our vision pipeline and run a user study of this system. Through successful application in a medically proven bi-manual coordination and navigation task, the framework has shown to be a promising starting point towards broader clinical adoption of REHs.
Intrapapillary Capillary Loop Classification in Magnification Endoscopy: Open Dataset and Baseline Methodology
Feb 19, 2021



Purpose. Early squamous cell neoplasia (ESCN) in the oesophagus is a highly treatable condition. Lesions confined to the mucosal layer can be curatively treated endoscopically. We build a computer-assisted detection (CADe) system that can classify still images or video frames as normal or abnormal with high diagnostic accuracy. Methods. We present a new benchmark dataset containing 68K binary labeled frames extracted from 114 patient videos whose imaged areas have been resected and correlated to histopathology. Our novel convolutional network (CNN) architecture solves the binary classification task and explains what features of the input domain drive the decision-making process of the network. Results. The proposed method achieved an average accuracy of 91.7 % compared to the 94.7 % achieved by a group of 12 senior clinicians. Our novel network architecture produces deeply supervised activation heatmaps that suggest the network is looking at intrapapillary capillary loop (IPCL) patterns when predicting abnormality. Conclusion. We believe that this dataset and baseline method may serve as a reference for future benchmarks on both video frame classification and explainability in the context of ESCN detection. A future work path of high clinical relevance is the extension of the classification to ESCN types.