 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a novel Comorbidities Index for predicting 10-year mortality in Prostate Cancer patients: A computational data-driven approach
May 29, 2026The Charlson Comorbidities Index (CCI) is a weighted additive index widely used to estimate ten-year mortality risk, but its original weights may not reflect contemporary prognoses. This limitation is critical in Prostate Cancer (PCa), where radical treatment is recommended only for patients with a life expectancy of at least ten years. For candidates eligible for Radical Prostatectomy (RP), accurate estimation of ten-year other-cause mortality is essential to balance oncological benefit against competing risks and avoid overtreatment. We propose a data-driven framework to derive a comorbidity index tailored to PCa patients considered for RP. Using a retrospective single-institution cohort, we apply Population-Based Bio-Inspired Algorithms (PBBIAs) to recalibrate comorbidity weights and evolve alternative symbolic formulations optimized for ten-year survival discrimination. We compared six optimization strategies, including symbolic regression approaches based on Genetic Programming (GP), population-based metaheuristics, clinically validated baselines, and survival prediction models. Results show that GA, FST-PSO, and SLIM outperform both the original CCI and the PCCI, particularly when PCa-specific variables are included, improving the Concordance Index by up to 0.1. GPLearn yields compact and interpretable models with competitive performance. Overall, the proposed approach provides an updated and interpretable tool to improve patient selection for RP.
Towards Real-Time Autonomous Navigation: Transformer-Based Catheter Tip Tracking in Fluoroscopy
May 14, 2026Purpose: Mechanical thrombectomy (MT) improves stroke outcomes, but is limited by a lack of local treatment access. Widespread distribution of reinforcement learning (RL)-based robotic systems can be used to alleviate this challenge through autonomous navigation, but current RL methods require live device tip coordinate tracking to function. This paper aims to develop and evaluate a real-time catheter tip tracking pipeline under fluoroscopy, addressing challenges such as low contrast, noise, and device occlusion. Methods: A multi-threaded pipeline was designed, incorporating frame reading, preprocessing, inference, and post-processing. Deep learning segmentation models, including U-Net, U-Net+Transformer, and SegFormer, were trained and benchmarked using two-class and three-class formulations. Post-processing involved two-step component filtering, one-pixel medial skeletonization, and greedy arc-length path following with contour fall-back. Results: On manually-labeled moderate complexity fluoroscopic video data, the two-class SegFormer achieved a mean absolute error of 4.44 mm, outperforming U-Net (4.60 mm), U-Net+Transformer (6.20 mm) and all three-class models (5.19-7.74 mm). On segmentation benchmarks, the system exceeded state-of-the-art CathAction results with improvements of up to +5% in Dice scores for three-segmentation. Conclusion: The results demonstrate that the proposed multi-threaded tracking framework maintains stable performance under challenging imaging conditions, outperforming prior benchmarks, while providing a reliable and efficient foundation for RL-based autonomous MT navigation.
* Harry Robertshaw and Yanghe Hao contributed equally to this work. Published in the International Journal of Computer Assisted Radiology and Surgery
Toward Safe Autonomous Robotic Endovascular Interventions using World Models
Apr 22, 2026Autonomous mechanical thrombectomy (MT) presents substantial challenges due to highly variable vascular geometries and the requirements for accurate, real-time control. While reinforcement learning (RL) has emerged as a promising paradigm for the automation of endovascular navigation, existing approaches often show limited robustness when faced with diverse patient anatomies or extended navigation horizons. In this work, we investigate a world-model-based framework for autonomous endovascular navigation built on TD-MPC2, a model-based RL method that integrates planning and learned dynamics. We evaluate a TD-MPC2 agent trained on multiple navigation tasks across hold out patient-specific vasculatures and benchmark its performance against the state-of-the-art Soft Actor-Critic (SAC) algorithm agent. Both approaches are further validated in vitro using patient-specific vascular phantoms under fluoroscopic guidance. In simulation, TD-MPC2 demonstrates a significantly higher mean success rate than SAC (58% vs. 36%, p < 0.001), and mean tip contact forces of 0.15 N, well below the proposed 1.5 N vessel rupture threshold. Mean success rates for TD-MPC2 (68%) were comparable to SAC (60%) in vitro, but TD-MPC2 achieved superior path ratios (p = 0.017) at the cost of longer procedure times (p < 0.001). Together, these results provide the first demonstration of autonomous MT navigation validated across both hold out in silico data and fluoroscopy-guided in vitro experiments, highlighting the promise of world models for safe and generalizable AI-assisted endovascular interventions.
A Position Statement on Endovascular Models and Effectiveness Metrics for Mechanical Thrombectomy Navigation, on behalf of the Stakeholder Taskforce for AI-assisted Robotic Thrombectomy (START)
Mar 30, 2026While we are making progress in overcoming infectious diseases and cancer; one of the major medical challenges of the mid-21st century will be the rising prevalence of stroke. Large vessels occlusions are especially debilitating, yet effective treatment (needed within hours to achieve best outcomes) remains limited due to geography. One solution for improving timely access to mechanical thrombectomy in geographically diverse populations is the deployment of robotic surgical systems. Artificial intelligence (AI) assistance may enable the upskilling of operators in this emerging therapeutic delivery approach. Our aim was to establish consensus frameworks for developing and validating AI-assisted robots for thrombectomy. Objectives included standardizing effectiveness metrics and defining reference testbeds across in silico, in vitro, ex vivo, and in vivo environments. To achieve this, we convened experts in neurointervention, robotics, data science, health economics, policy, statistics, and patient advocacy. Consensus was built through an incubator day, a Delphi process, and a final Position Statement. We identified that the four essential testbed environments each had distinct validation roles. Realism requirements vary: simpler testbeds should include realistic vessel anatomy compatible with guidewire and catheter use, while standard testbeds should incorporate deformable vessels. More advanced testbeds should include blood flow, pulsatility, and disease features. There are two macro-classes of effectiveness metrics: one for in silico, in vitro, and ex vivo stages focusing on technical navigation, and another for in vivo stages, focused on clinical outcomes. Patient safety is central to this technology's development. One requisite patient safety task needed now is to correlate in vitro measurements to in vivo complications.
* Published in Journal of the American Heart Association
From Pre- to Intra-operative MRI: Predicting Brain Shift in Temporal Lobe Resection for Epilepsy Surgery
Feb 03, 2026Introduction: In neurosurgery, image-guided Neurosurgery Systems (IGNS) highly rely on preoperative brain magnetic resonance images (MRI) to assist surgeons in locating surgical targets and determining surgical paths. However, brain shift invalidates the preoperative MRI after dural opening. Updated intraoperative brain MRI with brain shift compensation is crucial for enhancing the precision of neuronavigation systems and ensuring the optimal outcome of surgical interventions. Methodology: We propose NeuralShift, a U-Net-based model that predicts brain shift entirely from pre-operative MRI for patients undergoing temporal lobe resection. We evaluated our results using Target Registration Errors (TREs) computed on anatomical landmarks located on the resection side and along the midline, and DICE scores comparing predicted intraoperative masks with masks derived from intraoperative MRI. Results: Our experimental results show that our model can predict the global deformation of the brain (DICE of 0.97) with accurate local displacements (achieve landmark TRE as low as 1.12 mm), compensating for large brain shifts during temporal lobe removal neurosurgery. Conclusion: Our proposed model is capable of predicting the global deformation of the brain during temporal lobe resection using only preoperative images, providing potential opportunities to the surgical team to increase safety and efficiency of neurosurgery and better outcomes to patients. Our contributions will be publicly available after acceptance in https://github.com/SurgicalDataScienceKCL/NeuralShift.
Reinforcement Learning for Safe Autonomous Two Device Navigation of Cerebral Vessels in Mechanical Thrombectomy
Mar 31, 2025Purpose: Autonomous systems in mechanical thrombectomy (MT) hold promise for reducing procedure times, minimizing radiation exposure, and enhancing patient safety. However, current reinforcement learning (RL) methods only reach the carotid arteries, are not generalizable to other patient vasculatures, and do not consider safety. We propose a safe dual-device RL algorithm that can navigate beyond the carotid arteries to cerebral vessels. Methods: We used the Simulation Open Framework Architecture to represent the intricacies of cerebral vessels, and a modified Soft Actor-Critic RL algorithm to learn, for the first time, the navigation of micro-catheters and micro-guidewires. We incorporate patient safety metrics into our reward function by integrating guidewire tip forces. Inverse RL is used with demonstrator data on 12 patient-specific vascular cases. Results: Our simulation demonstrates successful autonomous navigation within unseen cerebral vessels, achieving a 96% success rate, 7.0s procedure time, and 0.24 N mean forces, well below the proposed 1.5 N vessel rupture threshold. Conclusion: To the best of our knowledge, our proposed autonomous system for MT two-device navigation reaches cerebral vessels, considers safety, and is generalizable to unseen patient-specific cases for the first time. We envisage future work will extend the validation to vasculatures of different complexity and on in vitro models. While our contributions pave the way towards deploying agents in clinical settings, safety and trustworthiness will be crucial elements to consider when proposing new methodology.
UltraFlwr -- An Efficient Federated Medical and Surgical Object Detection Framework
Mar 19, 2025Object detection shows promise for medical and surgical applications such as cell counting and tool tracking. However, its faces multiple real-world edge deployment challenges including limited high-quality annotated data, data sharing restrictions, and computational constraints. In this work, we introduce UltraFlwr, a framework for federated medical and surgical object detection. By leveraging Federated Learning (FL), UltraFlwr enables decentralized model training across multiple sites without sharing raw data. To further enhance UltraFlwr's efficiency, we propose YOLO-PA, a set of novel Partial Aggregation (PA) strategies specifically designed for YOLO models in FL. YOLO-PA significantly reduces communication overhead by up to 83% per round while maintaining performance comparable to Full Aggregation (FA) strategies. Our extensive experiments on BCCD and m2cai16-tool-locations datasets demonstrate that YOLO-PA not only provides better client models compared to client-wise centralized training and FA strategies, but also facilitates efficient training and deployment across resource-constrained edge devices. Further, we also establish one of the first benchmarks in federated medical and surgical object detection. This paper advances the feasibility of training and deploying detection models on the edge, making federated object detection more practical for time-critical and resource-constrained medical and surgical applications. UltraFlwr is publicly available at https://github.com/KCL-BMEIS/UltraFlwr.
SWAG: Long-term Surgical Workflow Prediction with Generative-based Anticipation
Dec 25, 2024
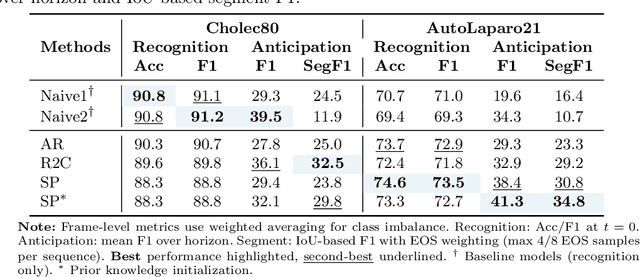
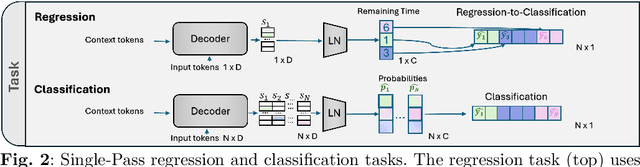
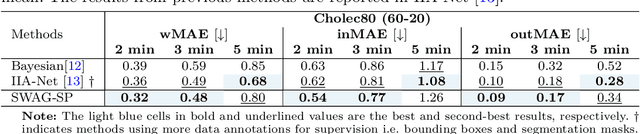
While existing recognition approaches excel at identifying current surgical phases, they provide limited foresight into future procedural steps, restricting their intraoperative utility. Similarly, current anticipation methods are constrained to predicting short-term events or singular future occurrences, neglecting the dynamic and sequential nature of surgical workflows. To address these limitations, we propose SWAG (Surgical Workflow Anticipative Generation), a unified framework for phase recognition and long-term anticipation of surgical workflows. SWAG employs two generative decoding methods -- single-pass (SP) and auto-regressive (AR) -- to predict sequences of future surgical phases. A novel prior knowledge embedding mechanism enhances the accuracy of anticipatory predictions. The framework addresses future phase classification and remaining time regression tasks. Additionally, a regression-to-classification (R2C) method is introduced to map continuous predictions to discrete temporal segments. SWAG's performance was evaluated on the Cholec80 and AutoLaparo21 datasets. The single-pass classification model with prior knowledge embeddings (SWAG-SP\*) achieved 53.5\% accuracy in 15-minute anticipation on AutoLaparo21, while the R2C model reached 60.8\% accuracy on Cholec80. SWAG's single-pass regression approach outperformed existing methods for remaining time prediction, achieving weighted mean absolute errors of 0.32 and 0.48 minutes for 2- and 3-minute horizons, respectively. SWAG demonstrates versatility across classification and regression tasks, offering robust tools for real-time surgical workflow anticipation. By unifying recognition and anticipatory capabilities, SWAG provides actionable predictions to enhance intraoperative decision-making.
Autonomous navigation of catheters and guidewires in mechanical thrombectomy using inverse reinforcement learning
Jun 18, 2024Purpose: Autonomous navigation of catheters and guidewires can enhance endovascular surgery safety and efficacy, reducing procedure times and operator radiation exposure. Integrating tele-operated robotics could widen access to time-sensitive emergency procedures like mechanical thrombectomy (MT). Reinforcement learning (RL) shows potential in endovascular navigation, yet its application encounters challenges without a reward signal. This study explores the viability of autonomous navigation in MT vasculature using inverse RL (IRL) to leverage expert demonstrations. Methods: This study established a simulation-based training and evaluation environment for MT navigation. We used IRL to infer reward functions from expert behaviour when navigating a guidewire and catheter. We utilized soft actor-critic to train models with various reward functions and compared their performance in silico. Results: We demonstrated feasibility of navigation using IRL. When evaluating single versus dual device (i.e. guidewire versus catheter and guidewire) tracking, both methods achieved high success rates of 95% and 96%, respectively. Dual-tracking, however, utilized both devices mimicking an expert. A success rate of 100% and procedure time of 22.6 s were obtained when training with a reward function obtained through reward shaping. This outperformed a dense reward function (96%, 24.9 s) and an IRL-derived reward function (48%, 59.2 s). Conclusions: We have contributed to the advancement of autonomous endovascular intervention navigation, particularly MT, by employing IRL. The results underscore the potential of using reward shaping to train models, offering a promising avenue for enhancing the accessibility and precision of MT. We envisage that future research can extend our methodology to diverse anatomical structures to enhance generalizability.
* Abstract shortened for arXiv character limit
Artificial Intelligence in the Autonomous Navigation of Endovascular Interventions: A Systematic Review
May 06, 2024
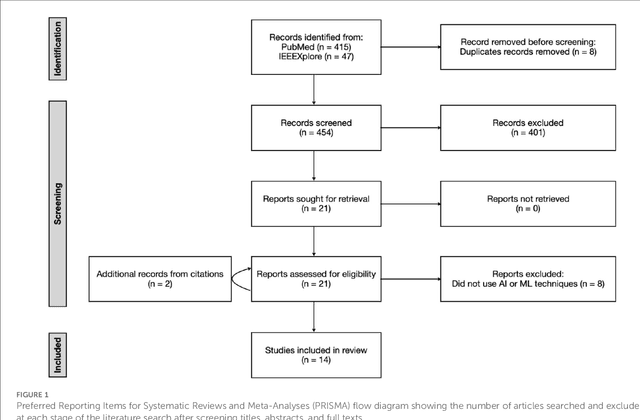

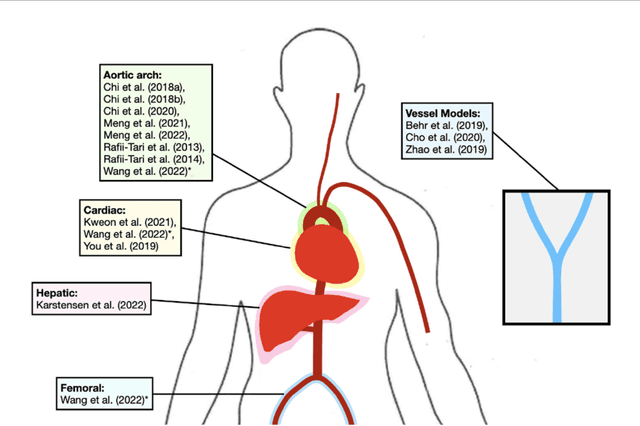
Purpose: Autonomous navigation of devices in endovascular interventions can decrease operation times, improve decision-making during surgery, and reduce operator radiation exposure while increasing access to treatment. This systematic review explores recent literature to assess the impact, challenges, and opportunities artificial intelligence (AI) has for the autonomous endovascular intervention navigation. Methods: PubMed and IEEEXplore databases were queried. Eligibility criteria included studies investigating the use of AI in enabling the autonomous navigation of catheters/guidewires in endovascular interventions. Following PRISMA, articles were assessed using QUADAS-2. PROSPERO: CRD42023392259. Results: Among 462 studies, fourteen met inclusion criteria. Reinforcement learning (9/14, 64%) and learning from demonstration (7/14, 50%) were used as data-driven models for autonomous navigation. Studies predominantly utilised physical phantoms (10/14, 71%) and in silico (4/14, 29%) models. Experiments within or around the blood vessels of the heart were reported by the majority of studies (10/14, 71%), while simple non-anatomical vessel platforms were used in three studies (3/14, 21%), and the porcine liver venous system in one study. We observed that risk of bias and poor generalisability were present across studies. No procedures were performed on patients in any of the studies reviewed. Studies lacked patient selection criteria, reference standards, and reproducibility, resulting in low clinical evidence levels. Conclusions: AI's potential in autonomous endovascular navigation is promising, but in an experimental proof-of-concept stage, with a technology readiness level of 3. We highlight that reference standards with well-identified performance metrics are crucial to allow for comparisons of data-driven algorithms proposed in the years to come.
* Abstract shortened for arXiv character limit