 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-Prune: Joint Model Pruning and Resource Allocation for Communication-efficient Time-triggered Federated Learning
Nov 06, 2025Federated learning (FL) offers new opportunities in machine learning, particularly in addressing data privacy concerns. In contrast to conventional event-based federated learning, time-triggered federated learning (TT-Fed), as a general form of both asynchronous and synchronous FL, clusters users into different tiers based on fixed time intervals. However, the FL network consists of a growing number of user devices with limited wireless bandwidth, consequently magnifying issues such as stragglers and communication overhead. In this paper, we introduce adaptive model pruning to wireless TT-Fed systems and study the problem of jointly optimizing the pruning ratio and bandwidth allocation to minimize the training loss while ensuring minimal learning latency. To answer this question, we perform convergence analysis on the gradient l_2 norm of the TT-Fed model based on model pruning. Based on the obtained convergence upper bound, a joint optimization problem of pruning ratio and wireless bandwidth is formulated to minimize the model training loss under a given delay threshold. Then, we derive closed-form solutions for wireless bandwidth and pruning ratio using Karush-Kuhn-Tucker(KKT) conditions. The simulation results show that model pruning could reduce the communication cost by 40% while maintaining the model performance at the same level.
xApp Conflict Mitigation with Scheduler
Apr 09, 2025Open RAN (O-RAN) fosters multi-vendor interoperability and data-driven control but simultaneously introduces the challenge of managing pre-trained xApps that can produce conflicting actions. Although O-RAN specifications mandate offline training and validation to prevent untrained models, operational conflicts remain likely under dynamic, context-dependent conditions. This work proposes a scheduler-based conflict mitigation framework to address these challenges without requiring training xApps together or further xApp re-training. By examining an indirect conflict involving power and resource block allocation xApps and employing an Advantage Actor-Critic (A2C) approach to train both xApps and the scheduler, we illustrate that a straightforward A2C-based scheduler improves performance relative to independently deployed xApps and conflicting cases. Notably, augmenting the system with baseline xApps and allowing the scheduler to select from a broader pool yields the best results, underscoring the importance of adaptive scheduling mechanisms. These findings highlight the context-dependent nature of conflicts in automated network management, as two xApps may conflict under certain conditions but coexist under others. Consequently, the ability to dynamically update and adapt the scheduler to accommodate diverse operational intents is vital for future network deployments. By offering dynamic scheduling without re-training xApps, this framework advances practical conflict resolution solutions while supporting real-world scalability.
UltraFlwr -- An Efficient Federated Medical and Surgical Object Detection Framework
Mar 19, 2025Object detection shows promise for medical and surgical applications such as cell counting and tool tracking. However, its faces multiple real-world edge deployment challenges including limited high-quality annotated data, data sharing restrictions, and computational constraints. In this work, we introduce UltraFlwr, a framework for federated medical and surgical object detection. By leveraging Federated Learning (FL), UltraFlwr enables decentralized model training across multiple sites without sharing raw data. To further enhance UltraFlwr's efficiency, we propose YOLO-PA, a set of novel Partial Aggregation (PA) strategies specifically designed for YOLO models in FL. YOLO-PA significantly reduces communication overhead by up to 83% per round while maintaining performance comparable to Full Aggregation (FA) strategies. Our extensive experiments on BCCD and m2cai16-tool-locations datasets demonstrate that YOLO-PA not only provides better client models compared to client-wise centralized training and FA strategies, but also facilitates efficient training and deployment across resource-constrained edge devices. Further, we also establish one of the first benchmarks in federated medical and surgical object detection. This paper advances the feasibility of training and deploying detection models on the edge, making federated object detection more practical for time-critical and resource-constrained medical and surgical applications. UltraFlwr is publicly available at https://github.com/KCL-BMEIS/UltraFlwr.
AI-Native Multi-Access Future Networks -- The REASON Architecture
Nov 25, 2024

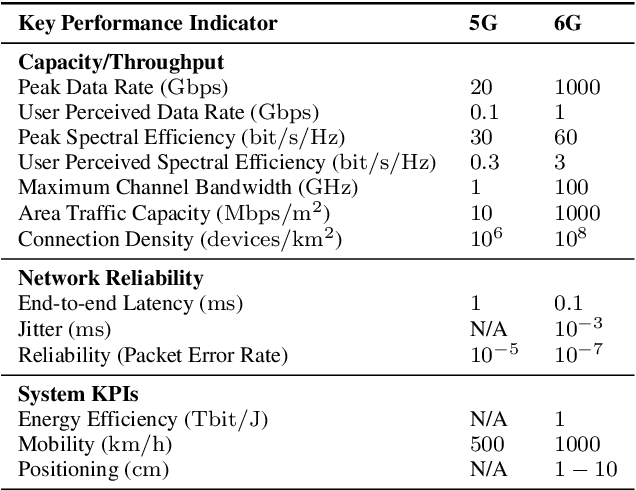
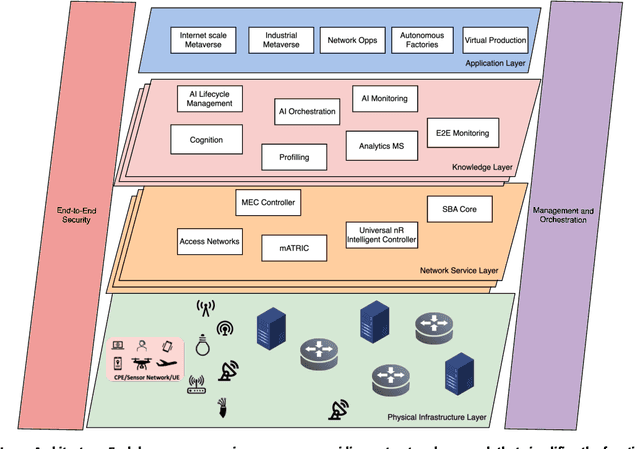
The development of the sixth generation of communication networks (6G) has been gaining momentum over the past years, with a target of being introduced by 2030. Several initiatives worldwide are developing innovative solutions and setting the direction for the key features of these networks. Some common emerging themes are the tight integration of AI, the convergence of multiple access technologies and sustainable operation, aiming to meet stringent performance and societal requirements. To that end, we are introducing REASON - Realising Enabling Architectures and Solutions for Open Networks. The REASON project aims to address technical challenges in future network deployments, such as E2E service orchestration, sustainability, security and trust management, and policy management, utilising AI-native principles, considering multiple access technologies and cloud-native solutions. This paper presents REASON's architecture and the identified requirements for future networks. The architecture is meticulously designed for modularity, interoperability, scalability, simplified troubleshooting, flexibility, and enhanced security, taking into consideration current and future standardisation efforts, and the ease of implementation and training. It is structured into four horizontal layers: Physical Infrastructure, Network Service, Knowledge, and End-User Application, complemented by two vertical layers: Management and Orchestration, and E2E Security. This layered approach ensures a robust, adaptable framework to support the diverse and evolving requirements of 6G networks, fostering innovation and facilitating seamless integration of advanced technologies.
Joint Model Pruning and Resource Allocation for Wireless Time-triggered Federated Learning
Aug 03, 2024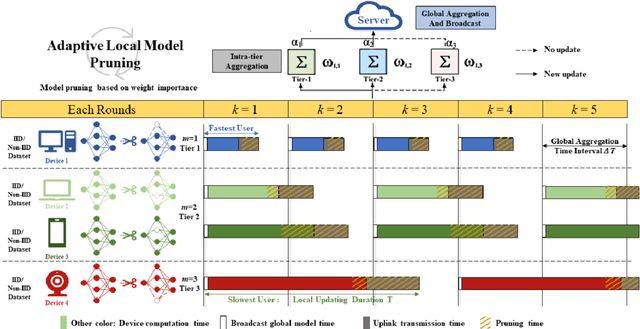
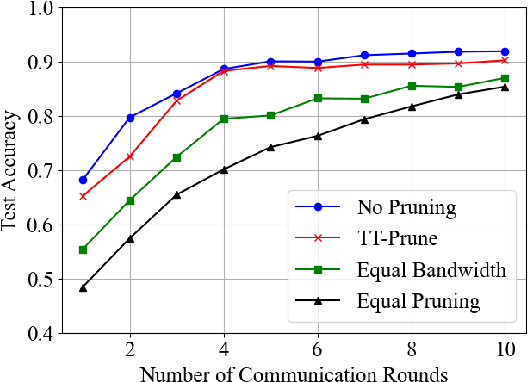
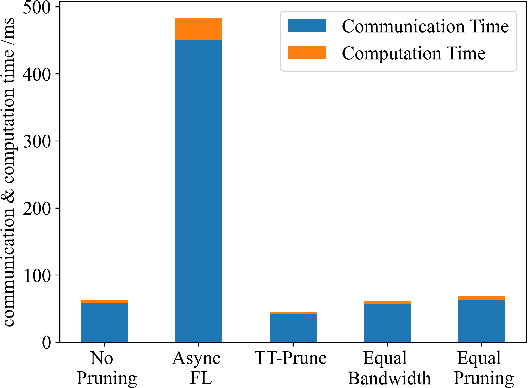
Time-triggered federated learning, in contrast to conventional event-based federated learning, organizes users into tiers based on fixed time intervals. However, this network still faces challenges due to a growing number of devices and limited wireless bandwidth, increasing issues like stragglers and communication overhead. In this paper, we apply model pruning to wireless Time-triggered systems and jointly study the problem of optimizing the pruning ratio and bandwidth allocation to minimize training loss under communication latency constraints. To solve this joint optimization problem, we perform a convergence analysis on the gradient $l_2$-norm of the asynchronous multi-tier federated learning (FL) model with adaptive model pruning. The convergence upper bound is derived and a joint optimization problem of pruning ratio and wireless bandwidth is defined to minimize the model training loss under a given communication latency constraint. The closed-form solutions for wireless bandwidth and pruning ratio by using KKT conditions are then formulated. As indicated in the simulation experiments, our proposed TT-Prune demonstrates a 40% reduction in communication cost, compared with the asynchronous multi-tier FL without model pruning, while maintaining the model convergence at the same level.
Decentralized federated learning methods for reducing communication cost and energy consumption in UAV networks
Apr 13, 2023Unmanned aerial vehicles (UAV) or drones play many roles in a modern smart city such as the delivery of goods, mapping real-time road traffic and monitoring pollution. The ability of drones to perform these functions often requires the support of machine learning technology. However, traditional machine learning models for drones encounter data privacy problems, communication costs and energy limitations. Federated Learning, an emerging distributed machine learning approach, is an excellent solution to address these issues. Federated learning (FL) allows drones to train local models without transmitting raw data. However, existing FL requires a central server to aggregate the trained model parameters of the UAV. A failure of the central server can significantly impact the overall training. In this paper, we propose two aggregation methods: Commutative FL and Alternate FL, based on the existing architecture of decentralised Federated Learning for UAV Networks (DFL-UN) by adding a unique aggregation method of decentralised FL. Those two methods can effectively control energy consumption and communication cost by controlling the number of local training epochs, local communication, and global communication. The simulation results of the proposed training methods are also presented to verify the feasibility and efficiency of the architecture compared with two benchmark methods (e.g. standard machine learning training and standard single aggregation server training). The simulation results show that the proposed methods outperform the benchmark methods in terms of operational stability, energy consumption and communication cost.
Distributed Learning in Heterogeneous Environment: federated learning with adaptive aggregation and computation reduction
Feb 16, 2023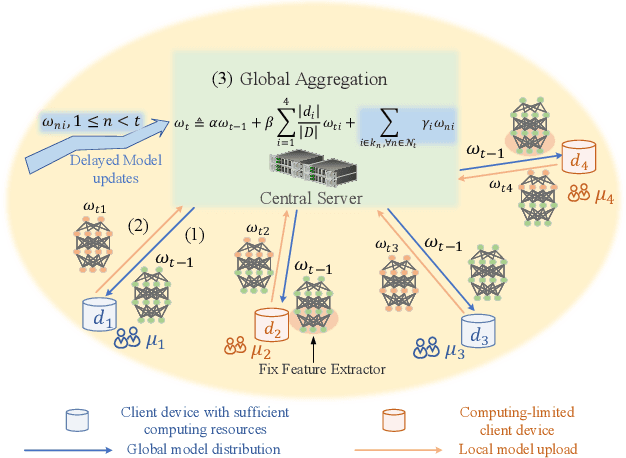
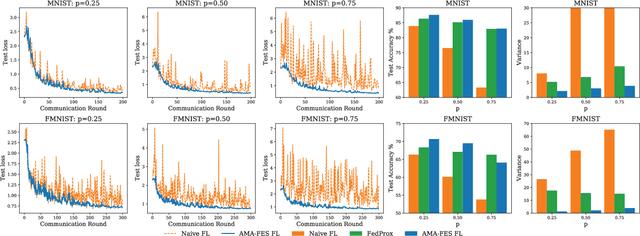
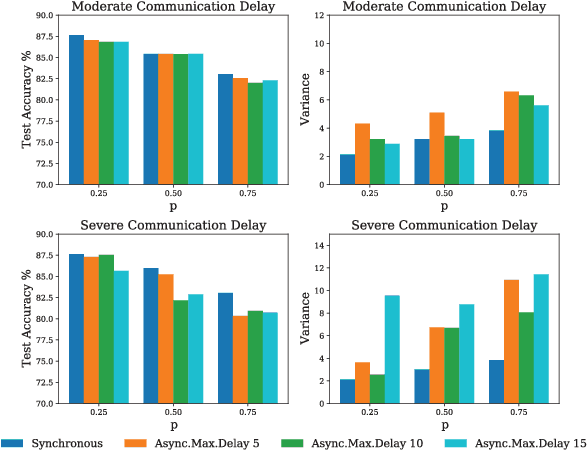
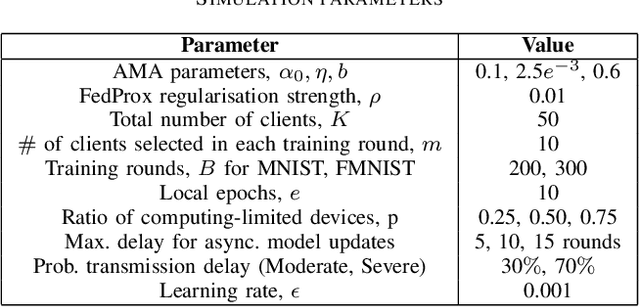
Although federated learning has achieved many breakthroughs recently, the heterogeneous nature of the learning environment greatly limits its performance and hinders its real-world applications. The heterogeneous data, time-varying wireless conditions and computing-limited devices are three main challenges, which often result in an unstable training process and degraded accuracy. Herein, we propose strategies to address these challenges. Targeting the heterogeneous data distribution, we propose a novel adaptive mixing aggregation (AMA) scheme that mixes the model updates from previous rounds with current rounds to avoid large model shifts and thus, maintain training stability. We further propose a novel staleness-based weighting scheme for the asynchronous model updates caused by the dynamic wireless environment. Lastly, we propose a novel CPU-friendly computation-reduction scheme based on transfer learning by sharing the feature extractor (FES) and letting the computing-limited devices update only the classifier. The simulation results show that the proposed framework outperforms existing state-of-the-art solutions and increases the test accuracy, and training stability by up to 2.38%, 93.10% respectively. Additionally, the proposed framework can tolerate communication delay of up to 15 rounds under a moderate delay environment without significant accuracy degradation.
Distributed Intelligence in Wireless Networks
Aug 01, 2022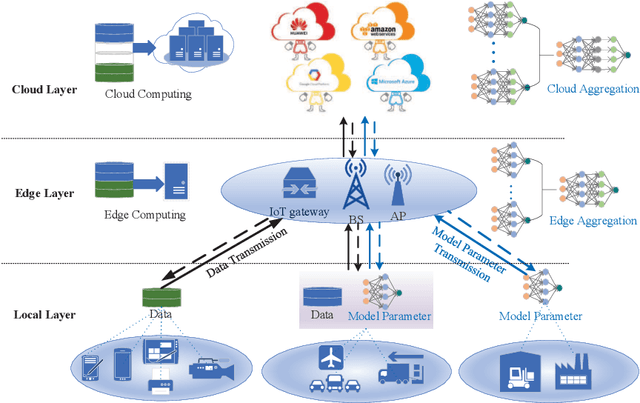
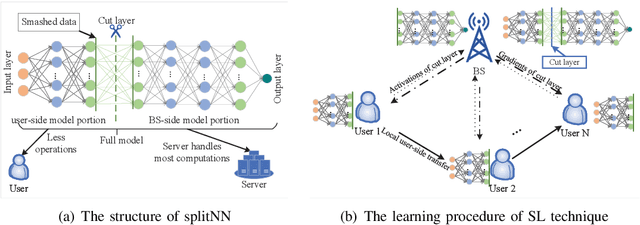
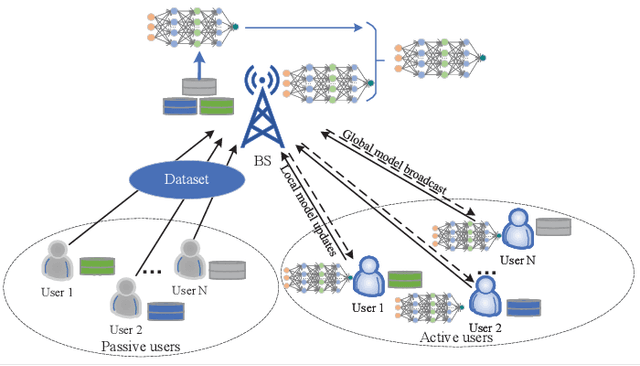
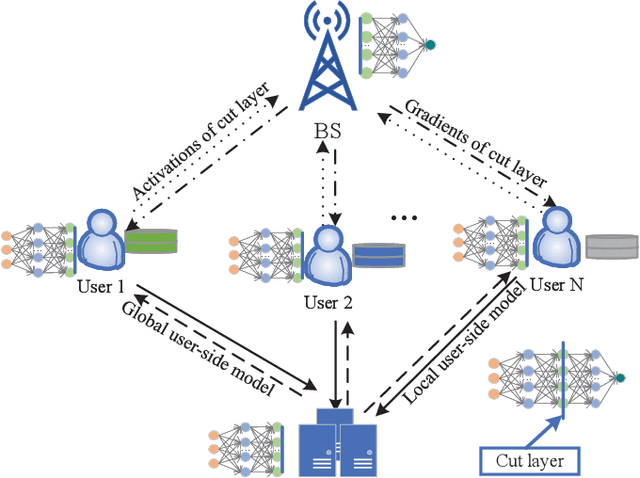
The cloud-based solutions are becoming inefficient due to considerably large time delays, high power consumption, security and privacy concerns caused by billions of connected wireless devices and typically zillions bytes of data they produce at the network edge. A blend of edge computing and Artificial Intelligence (AI) techniques could optimally shift the resourceful computation servers closer to the network edge, which provides the support for advanced AI applications (e.g., video/audio surveillance and personal recommendation system) by enabling intelligent decision making on computing at the point of data generation as and when it is needed, and distributed Machine Learning (ML) with its potential to avoid the transmission of large dataset and possible compromise of privacy that may exist in cloud-based centralized learning. Therefore, AI is envisioned to become native and ubiquitous in future communication and networking systems. In this paper, we conduct a comprehensive overview of recent advances in distributed intelligence in wireless networks under the umbrella of native-AI wireless networks, with a focus on the basic concepts of native-AI wireless networks, on the AI-enabled edge computing, on the design of distributed learning architectures for heterogeneous networks, on the communication-efficient technologies to support distributed learning, and on the AI-empowered end-to-end communications. We highlight the advantages of hybrid distributed learning architectures compared to the state-of-art distributed learning techniques. We summarize the challenges of existing research contributions in distributed intelligence in wireless networks and identify the potential future opportunities.
The Role of Machine Learning for Trajectory Prediction in Cooperative Driving
Oct 21, 2020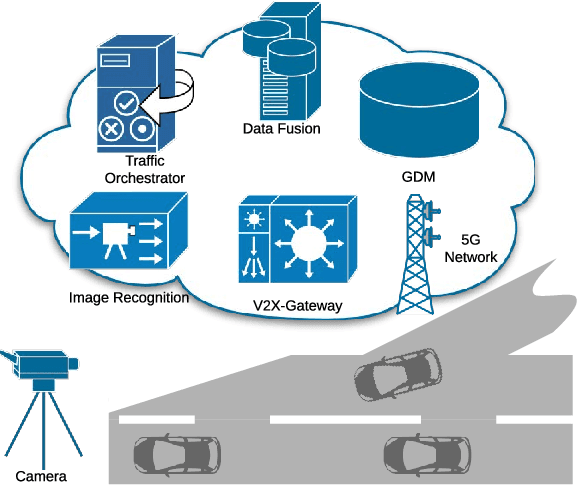

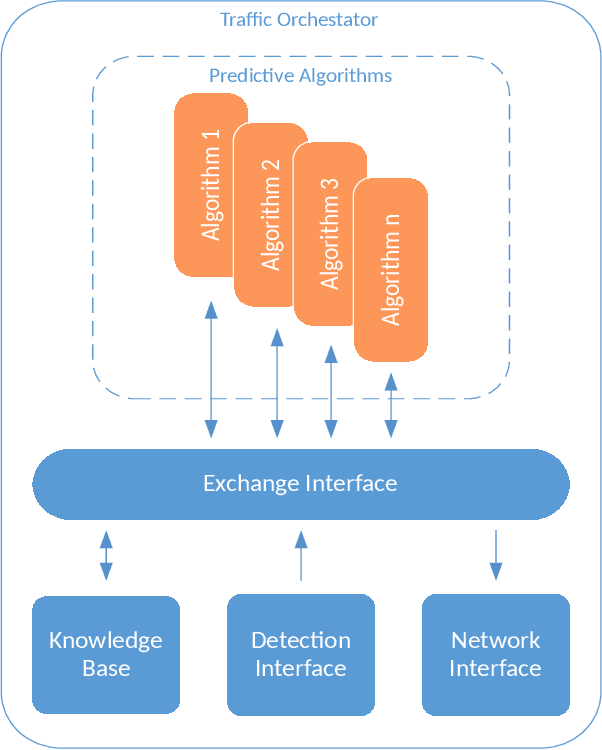

In this paper, we study the role that machine learning can play in cooperative driving. Given the increasing rate of connectivity in modern vehicles, and road infrastructure, cooperative driving is a promising first step in automated driving. The example scenario we explored in this paper, is coordinated lane merge, with data collection, test and evaluation all conducted in an automotive test track. The assumption is that vehicles are a mix of those equipped with communication units on board, i.e. connected vehicles, and those that are not connected. However, roadside cameras are connected and can capture all vehicles including those without connectivity. We develop a Traffic Orchestrator that suggests trajectories based on these two sources of information, i.e. connected vehicles, and connected roadside cameras. Recommended trajectories are built, which are then communicated back to the connected vehicles. We explore the use of different machine learning techniques in accurately and timely prediction of trajectories.
* arXiv admin note: text overlap with arXiv:2010.10426
Deep Reinforcement Learning in Lane Merge Coordination for Connected Vehicles
Oct 20, 2020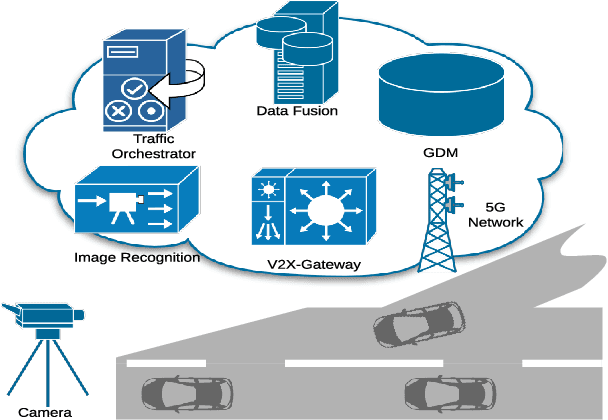
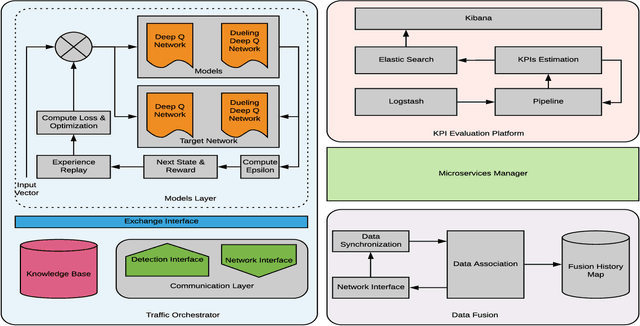
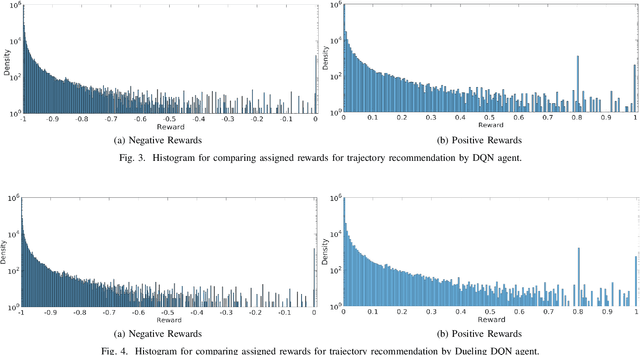
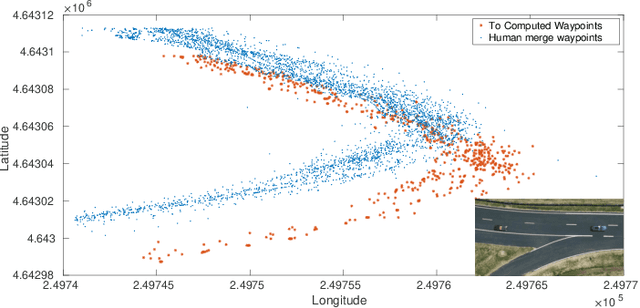
In this paper, a framework for lane merge coordination is presented utilising a centralised system, for connected vehicles. The delivery of trajectory recommendations to the connected vehicles on the road is based on a Traffic Orchestrator and a Data Fusion as the main components. Deep Reinforcement Learning and data analysis is used to predict trajectory recommendations for connected vehicles, taking into account unconnected vehicles for those suggestions. The results highlight the adaptability of the Traffic Orchestrator, when employing Dueling Deep Q-Network in an unseen real world merging scenario. A performance comparison of different reinforcement learning models and evaluation against Key Performance Indicator (KPI) are also presented.