 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGalaxy: A Cognition-Centered Framework for Proactive, Privacy-Preserving, and Self-Evolving LLM Agents
Aug 06, 2025Intelligent personal assistants (IPAs) such as Siri and Google Assistant are designed to enhance human capabilities and perform tasks on behalf of users. The emergence of LLM agents brings new opportunities for the development of IPAs. While responsive capabilities have been widely studied, proactive behaviors remain underexplored. Designing an IPA that is proactive, privacy-preserving, and capable of self-evolution remains a significant challenge. Designing such IPAs relies on the cognitive architecture of LLM agents. This work proposes Cognition Forest, a semantic structure designed to align cognitive modeling with system-level design. We unify cognitive architecture and system design into a self-reinforcing loop instead of treating them separately. Based on this principle, we present Galaxy, a framework that supports multidimensional interactions and personalized capability generation. Two cooperative agents are implemented based on Galaxy: KoRa, a cognition-enhanced generative agent that supports both responsive and proactive skills; and Kernel, a meta-cognition-based meta-agent that enables Galaxy's self-evolution and privacy preservation. Experimental results show that Galaxy outperforms multiple state-of-the-art benchmarks. Ablation studies and real-world interaction cases validate the effectiveness of Galaxy.
Maximizing Uncertainty for Federated learning via Bayesian Optimisation-based Model Poisoning
Jan 15, 2025As we transition from Narrow Artificial Intelligence towards Artificial Super Intelligence, users are increasingly concerned about their privacy and the trustworthiness of machine learning (ML) technology. A common denominator for the metrics of trustworthiness is the quantification of uncertainty inherent in DL algorithms, and specifically in the model parameters, input data, and model predictions. One of the common approaches to address privacy-related issues in DL is to adopt distributed learning such as federated learning (FL), where private raw data is not shared among users. Despite the privacy-preserving mechanisms in FL, it still faces challenges in trustworthiness. Specifically, the malicious users, during training, can systematically create malicious model parameters to compromise the models predictive and generative capabilities, resulting in high uncertainty about their reliability. To demonstrate malicious behaviour, we propose a novel model poisoning attack method named Delphi which aims to maximise the uncertainty of the global model output. We achieve this by taking advantage of the relationship between the uncertainty and the model parameters of the first hidden layer of the local model. Delphi employs two types of optimisation , Bayesian Optimisation and Least Squares Trust Region, to search for the optimal poisoned model parameters, named as Delphi-BO and Delphi-LSTR. We quantify the uncertainty using the KL Divergence to minimise the distance of the predictive probability distribution towards an uncertain distribution of model output. Furthermore, we establish a mathematical proof for the attack effectiveness demonstrated in FL. Numerical results demonstrate that Delphi-BO induces a higher amount of uncertainty than Delphi-LSTR highlighting vulnerability of FL systems to model poisoning attacks.
A General Sensing-assisted Channel Estimation Framework in Distributed MIMO Network
Nov 24, 2024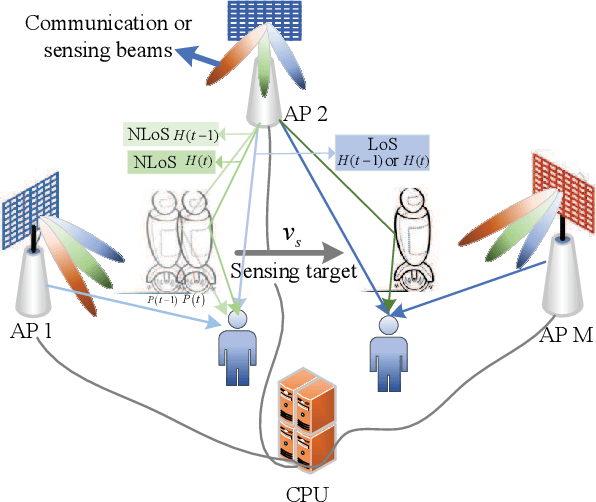
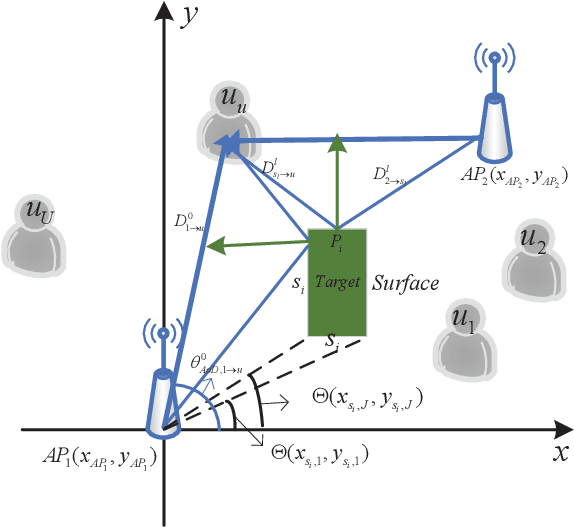
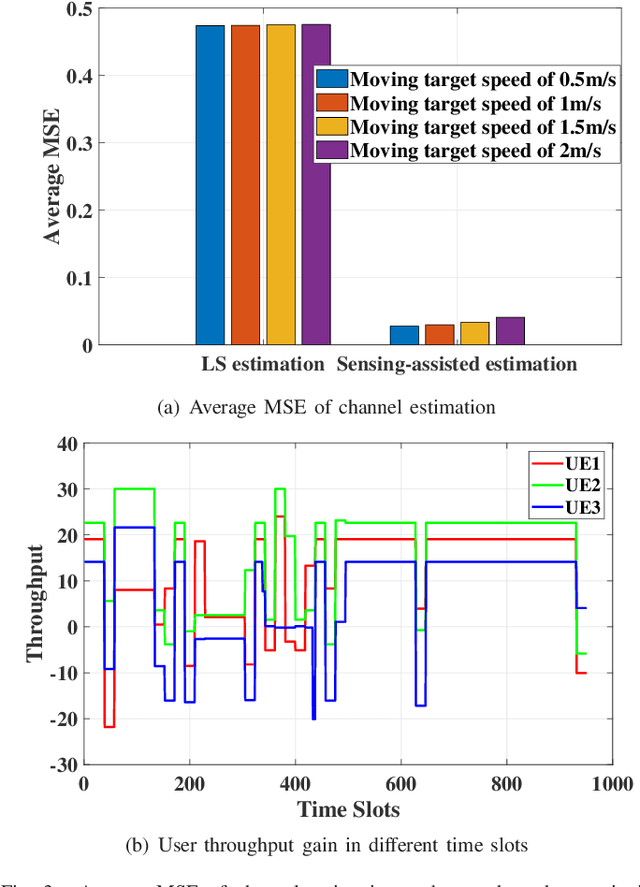
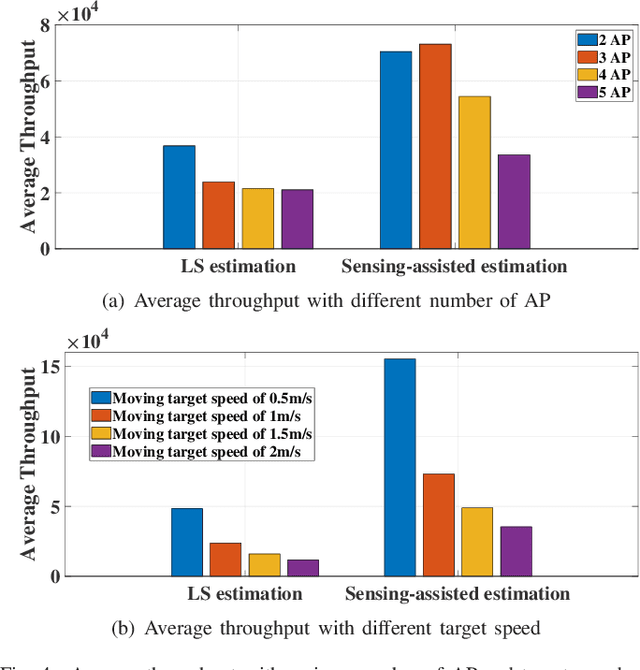
Joint sensing and communication (JSC) research direction has been envisioned to be a key technology in 6G communications, which has the potential to equip the traditional base station with sensing capability by fully exploiting the existing wireless communication infrastructures. To further enhance wireless communication performance in JSC, sensing-assisted communication has attracted attention from both industry and academia. However, most existing papers focused on sensing-assisted communication under line-of-sight (LoS) scenarios due to sensing limitations, where the sensing target and communication user remain the same. In this paper, we propose a general sensing-assisted channel estimation framework, where the channel estimation accuracy for both Los and non-line-of-sight (NLoS) are considered. Simulation results demonstrate that our proposed sensing-assisted communication framework achieves higher channel estimation accuracy and throughput compared to the traditional least-square (LS) estimation. More importantly, the feasibility of the proposed framework has been validated to solve the complex channel estimation challenge in distributed multiple input and multiple output (MIMO) network.
Enhancing Federated Learning Convergence with Dynamic Data Queue and Data Entropy-driven Participant Selection
Oct 23, 2024Federated Learning (FL) is a decentralized approach for collaborative model training on edge devices. This distributed method of model training offers advantages in privacy, security, regulatory compliance, and cost-efficiency. Our emphasis in this research lies in addressing statistical complexity in FL, especially when the data stored locally across devices is not identically and independently distributed (non-IID). We have observed an accuracy reduction of up to approximately 10\% to 30\%, particularly in skewed scenarios where each edge device trains with only 1 class of data. This reduction is attributed to weight divergence, quantified using the Euclidean distance between device-level class distributions and the population distribution, resulting in a bias term (\(\delta_k\)). As a solution, we present a method to improve convergence in FL by creating a global subset of data on the server and dynamically distributing it across devices using a Dynamic Data queue-driven Federated Learning (DDFL). Next, we leverage Data Entropy metrics to observe the process during each training round and enable reasonable device selection for aggregation. Furthermore, we provide a convergence analysis of our proposed DDFL to justify their viability in practical FL scenarios, aiming for better device selection, a non-sub-optimal global model, and faster convergence. We observe that our approach results in a substantial accuracy boost of approximately 5\% for the MNIST dataset, around 18\% for CIFAR-10, and 20\% for CIFAR-100 with a 10\% global subset of data, outperforming the state-of-the-art (SOTA) aggregation algorithms.
Fully Independent Communication in Multi-Agent Reinforcement Learning
Jan 26, 2024



Multi-Agent Reinforcement Learning (MARL) comprises a broad area of research within the field of multi-agent systems. Several recent works have focused specifically on the study of communication approaches in MARL. While multiple communication methods have been proposed, these might still be too complex and not easily transferable to more practical contexts. One of the reasons for that is due to the use of the famous parameter sharing trick. In this paper, we investigate how independent learners in MARL that do not share parameters can communicate. We demonstrate that this setting might incur into some problems, to which we propose a new learning scheme as a solution. Our results show that, despite the challenges, independent agents can still learn communication strategies following our method. Additionally, we use this method to investigate how communication in MARL is affected by different network capacities, both for sharing and not sharing parameters. We observe that communication may not always be needed and that the chosen agent network sizes need to be considered when used together with communication in order to achieve efficient learning.
Staged Reinforcement Learning for Complex Tasks through Decomposed Environments
Nov 05, 2023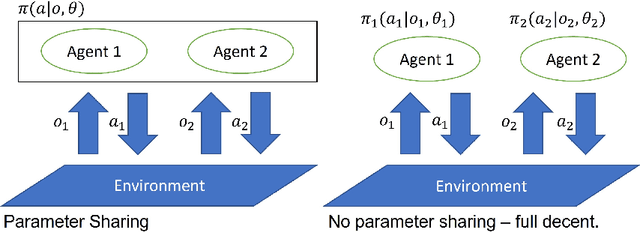
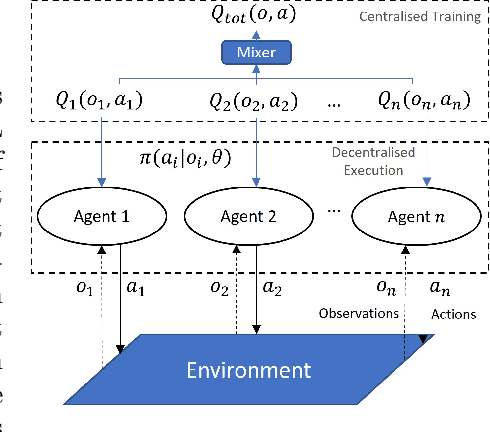
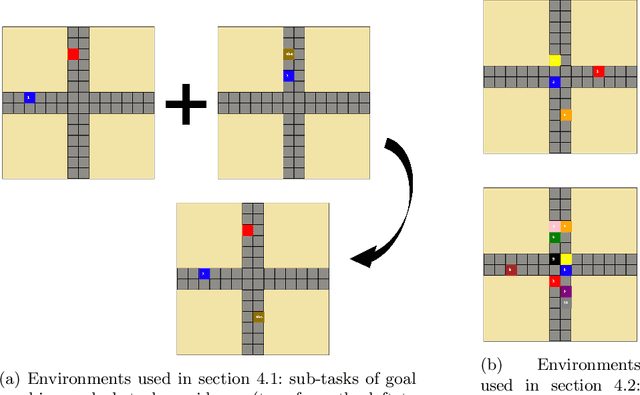
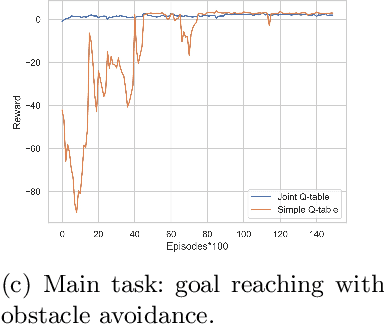
Reinforcement Learning (RL) is an area of growing interest in the field of artificial intelligence due to its many notable applications in diverse fields. Particularly within the context of intelligent vehicle control, RL has made impressive progress. However, currently it is still in simulated controlled environments where RL can achieve its full super-human potential. Although how to apply simulation experience in real scenarios has been studied, how to approximate simulated problems to the real dynamic problems is still a challenge. In this paper, we discuss two methods that approximate RL problems to real problems. In the context of traffic junction simulations, we demonstrate that, if we can decompose a complex task into multiple sub-tasks, solving these tasks first can be advantageous to help minimising possible occurrences of catastrophic events in the complex task. From a multi-agent perspective, we introduce a training structuring mechanism that exploits the use of experience learned under the popular paradigm called Centralised Training Decentralised Execution (CTDE). This experience can then be leveraged in fully decentralised settings that are conceptually closer to real settings, where agents often do not have access to a central oracle and must be treated as isolated independent units. The results show that the proposed approaches improve agents performance in complex tasks related to traffic junctions, minimising potential safety-critical problems that might happen in these scenarios. Although still in simulation, the investigated situations are conceptually closer to real scenarios and thus, with these results, we intend to motivate further research in the subject.
FheFL: Fully Homomorphic Encryption Friendly Privacy-Preserving Federated Learning with Byzantine Users
Jun 26, 2023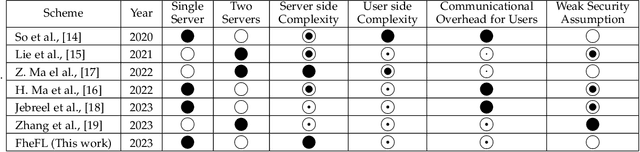
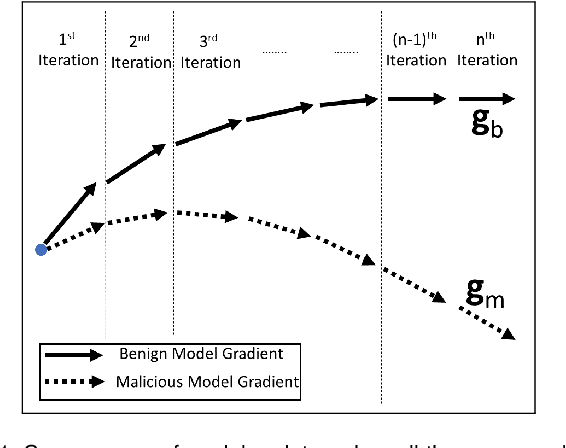
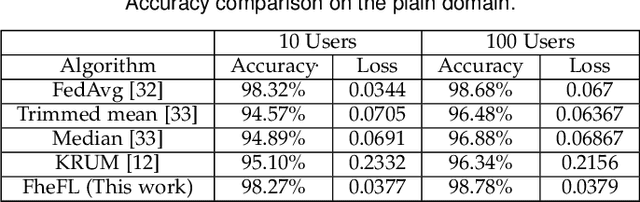
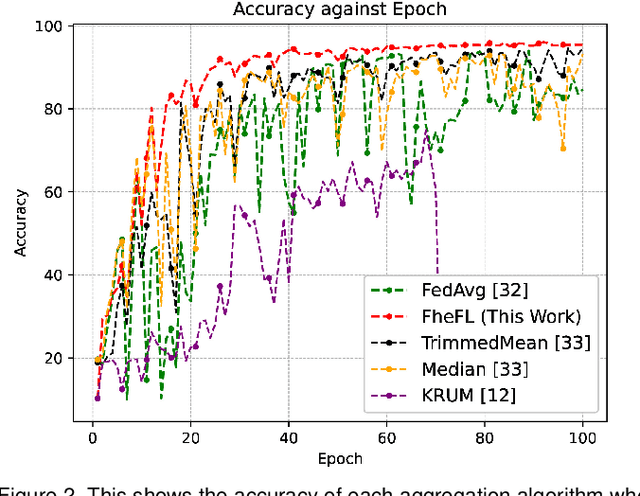
The federated learning (FL) technique was developed to mitigate data privacy issues in the traditional machine learning paradigm. While FL ensures that a user's data always remain with the user, the gradients are shared with the centralized server to build the global model. This results in privacy leakage, where the server can infer private information from the shared gradients. To mitigate this flaw, the next-generation FL architectures proposed encryption and anonymization techniques to protect the model updates from the server. However, this approach creates other challenges, such as malicious users sharing false gradients. Since the gradients are encrypted, the server is unable to identify rogue users. To mitigate both attacks, this paper proposes a novel FL algorithm based on a fully homomorphic encryption (FHE) scheme. We develop a distributed multi-key additive homomorphic encryption scheme that supports model aggregation in FL. We also develop a novel aggregation scheme within the encrypted domain, utilizing users' non-poisoning rates, to effectively address data poisoning attacks while ensuring privacy is preserved by the proposed encryption scheme. Rigorous security, privacy, convergence, and experimental analyses have been provided to show that FheFL is novel, secure, and private, and achieves comparable accuracy at reasonable computational cost.
Recursive Euclidean Distance Based Robust Aggregation Technique For Federated Learning
Mar 20, 2023Federated learning has gained popularity as a solution to data availability and privacy challenges in machine learning. However, the aggregation process of local model updates to obtain a global model in federated learning is susceptible to malicious attacks, such as backdoor poisoning, label-flipping, and membership inference. Malicious users aim to sabotage the collaborative learning process by training the local model with malicious data. In this paper, we propose a novel robust aggregation approach based on recursive Euclidean distance calculation. Our approach measures the distance of the local models from the previous global model and assigns weights accordingly. Local models far away from the global model are assigned smaller weights to minimize the data poisoning effect during aggregation. Our experiments demonstrate that the proposed algorithm outperforms state-of-the-art algorithms by at least $5\%$ in accuracy while reducing time complexity by less than $55\%$. Our contribution is significant as it addresses the critical issue of malicious attacks in federated learning while improving the accuracy of the global model.
IRS Assisted NOMA Aided Mobile Edge Computing with Queue Stability: Heterogeneous Multi-Agent Reinforcement Learning
Sep 21, 2022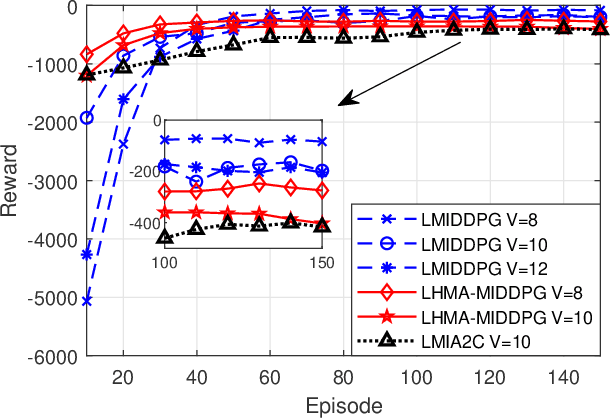
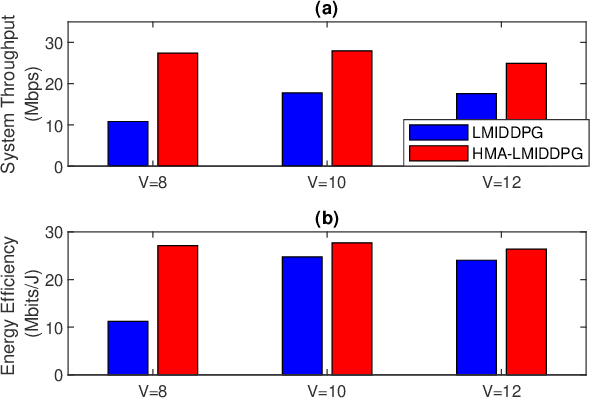
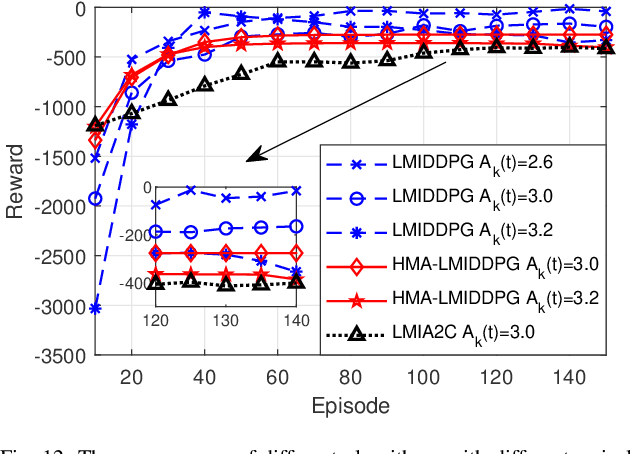
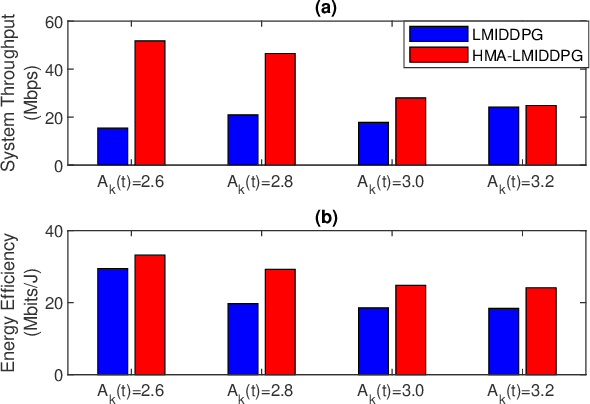
By employing powerful edge servers for data processing, mobile edge computing (MEC) has been recognized as a promising technology to support emerging computation-intensive applications. Besides, non-orthogonal multiple access (NOMA)-aided MEC system can further enhance the spectral-efficiency with massive tasks offloading. However, with more dynamic devices brought online and the uncontrollable stochastic channel environment, it is even desirable to deploy appealing technique, i.e., intelligent reflecting surfaces (IRS), in the MEC system to flexibly tune the communication environment and improve the system energy efficiency. In this paper, we investigate the joint offloading, communication and computation resource allocation for IRS-assisted NOMA MEC system. We firstly formulate a mixed integer energy efficiency maximization problem with system queue stability constraint. We then propose the Lyapunov-function-based Mixed Integer Deep Deterministic Policy Gradient (LMIDDPG) algorithm which is based on the centralized reinforcement learning (RL) framework. To be specific, we design the mixed integer action space mapping which contains both continuous mapping and integer mapping. Moreover, the award function is defined as the upper-bound of the Lyapunov drift-plus-penalty function. To enable end devices (EDs) to choose actions independently at the execution stage, we further propose the Heterogeneous Multi-agent LMIDDPG (HMA-LMIDDPG) algorithm based on distributed RL framework with homogeneous EDs and heterogeneous base station (BS) as heterogeneous multi-agent. Numerical results show that our proposed algorithms can achieve superior energy efficiency performance to the benchmark algorithms while maintaining the queue stability. Specially, the distributed structure HMA-LMIDDPG can acquire more energy efficiency gain than centralized structure LMIDDPG.
Distributed Intelligence in Wireless Networks
Aug 01, 2022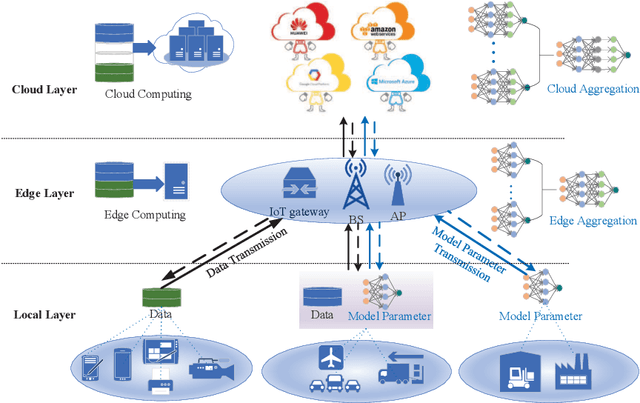
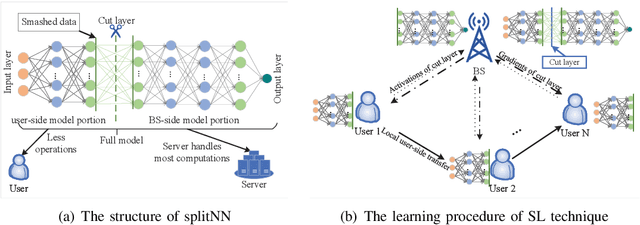
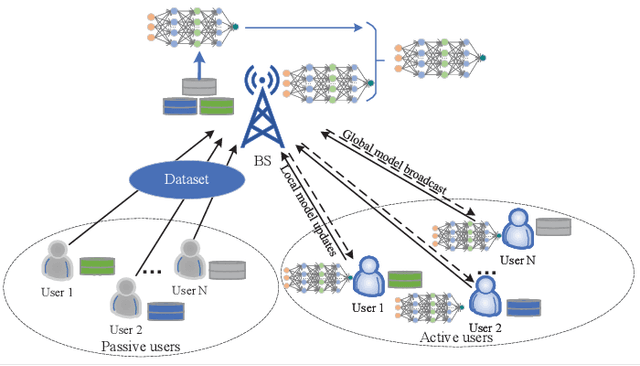
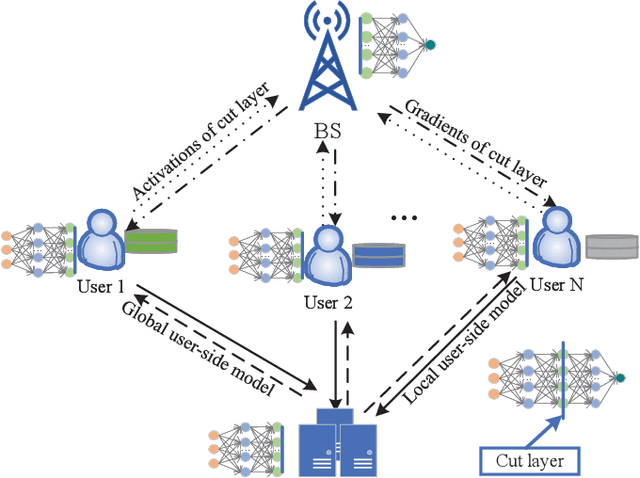
The cloud-based solutions are becoming inefficient due to considerably large time delays, high power consumption, security and privacy concerns caused by billions of connected wireless devices and typically zillions bytes of data they produce at the network edge. A blend of edge computing and Artificial Intelligence (AI) techniques could optimally shift the resourceful computation servers closer to the network edge, which provides the support for advanced AI applications (e.g., video/audio surveillance and personal recommendation system) by enabling intelligent decision making on computing at the point of data generation as and when it is needed, and distributed Machine Learning (ML) with its potential to avoid the transmission of large dataset and possible compromise of privacy that may exist in cloud-based centralized learning. Therefore, AI is envisioned to become native and ubiquitous in future communication and networking systems. In this paper, we conduct a comprehensive overview of recent advances in distributed intelligence in wireless networks under the umbrella of native-AI wireless networks, with a focus on the basic concepts of native-AI wireless networks, on the AI-enabled edge computing, on the design of distributed learning architectures for heterogeneous networks, on the communication-efficient technologies to support distributed learning, and on the AI-empowered end-to-end communications. We highlight the advantages of hybrid distributed learning architectures compared to the state-of-art distributed learning techniques. We summarize the challenges of existing research contributions in distributed intelligence in wireless networks and identify the potential future opportunities.