 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantFL: Sustainable Federated Learning for Edge IoT via Pre-Trained Model Quantisation
Mar 18, 2026Federated Learning (FL) enables privacy-preserving intelligence on Internet of Things (IoT) devices but incurs a significant carbon footprint due to the high energy cost of frequent uplink transmission. While pre-trained models are increasingly available on edge devices, their potential to reduce the energy overhead of fine-tuning remains underexplored. In this work, we propose QuantFL, a sustainable FL framework that leverages pre-trained initialisation to enable aggressive, computationally lightweight quantisation. We demonstrate that pre-training naturally concentrates update statistics, allowing us to use memory-efficient bucket quantisation without the energy-intensive overhead of complex error-feedback mechanisms. On MNIST and CIFAR-100, QuantFL reduces total communication by 40\% ($\simeq40\%$ total-bit reduction with full-precision downlink; $\geq80\%$ on uplink or when downlink is quantised) while matching or exceeding uncompressed baselines under strict bandwidth budgets; BU attains 89.00\% (MNIST) and 66.89\% (CIFAR-100) test accuracy with orders of magnitude fewer bits. We also account for uplink and downlink costs and provide ablations on quantisation levels and initialisation. QuantFL delivers a practical, "green" recipe for scalable training on battery-constrained IoT networks.
DSFL: A Dual-Server Byzantine-Resilient Federated Learning Framework via Group-Based Secure Aggregation
Sep 10, 2025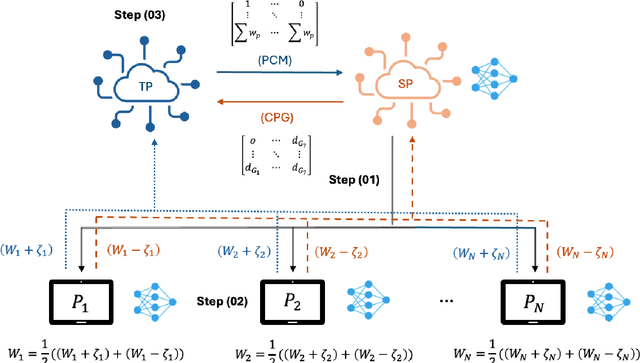
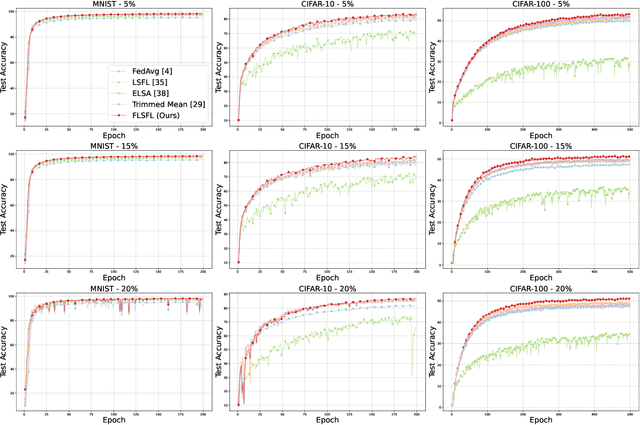
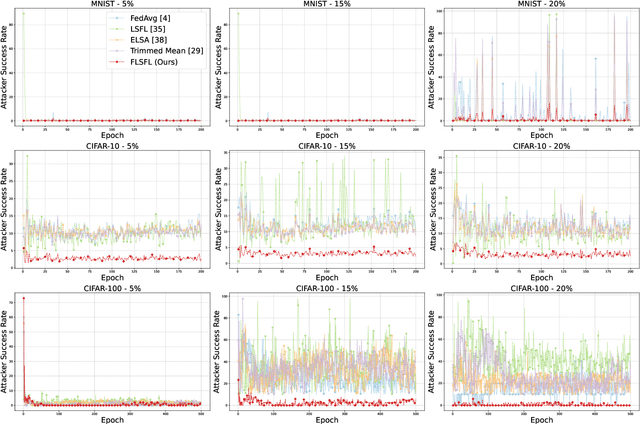
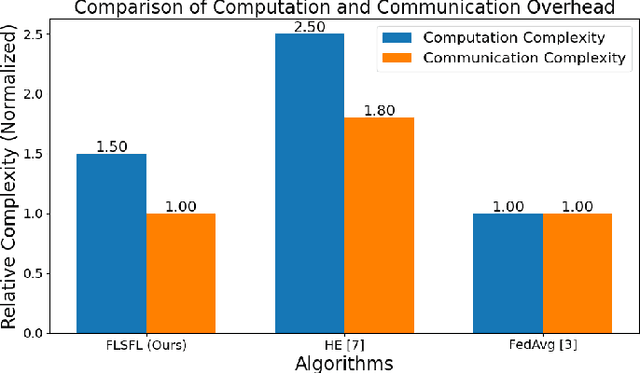
Federated Learning (FL) enables decentralized model training without sharing raw data, offering strong privacy guarantees. However, existing FL protocols struggle to defend against Byzantine participants, maintain model utility under non-independent and identically distributed (non-IID) data, and remain lightweight for edge devices. Prior work either assumes trusted hardware, uses expensive cryptographic tools, or fails to address privacy and robustness simultaneously. We propose DSFL, a Dual-Server Byzantine-Resilient Federated Learning framework that addresses these limitations using a group-based secure aggregation approach. Unlike LSFL, which assumes non-colluding semi-honest servers, DSFL removes this dependency by revealing a key vulnerability: privacy leakage through client-server collusion. DSFL introduces three key innovations: (1) a dual-server secure aggregation protocol that protects updates without encryption or key exchange, (2) a group-wise credit-based filtering mechanism to isolate Byzantine clients based on deviation scores, and (3) a dynamic reward-penalty system for enforcing fair participation. DSFL is evaluated on MNIST, CIFAR-10, and CIFAR-100 under up to 30 percent Byzantine participants in both IID and non-IID settings. It consistently outperforms existing baselines, including LSFL, homomorphic encryption methods, and differential privacy approaches. For example, DSFL achieves 97.15 percent accuracy on CIFAR-10 and 68.60 percent on CIFAR-100, while FedAvg drops to 9.39 percent under similar threats. DSFL remains lightweight, requiring only 55.9 ms runtime and 1088 KB communication per round.
Player Pressure Map -- A Novel Representation of Pressure in Soccer for Evaluating Player Performance in Different Game Contexts
Jan 29, 2024



In soccer, contextual player performance metrics are invaluable to coaches. For example, the ability to perform under pressure during matches distinguishes the elite from the average. Appropriate pressure metric enables teams to assess players' performance accurately under pressure and design targeted training scenarios to address their weaknesses. The primary objective of this paper is to leverage both tracking and event data and game footage to capture the pressure experienced by the possession team in a soccer game scene. We propose a player pressure map to represent a given game scene, which lowers the dimension of raw data and still contains rich contextual information. Not only does it serve as an effective tool for visualizing and evaluating the pressure on the team and each individual, but it can also be utilized as a backbone for accessing players' performance. Overall, our model provides coaches and analysts with a deeper understanding of players' performance under pressure so that they make data-oriented tactical decisions.
Fully Independent Communication in Multi-Agent Reinforcement Learning
Jan 26, 2024



Multi-Agent Reinforcement Learning (MARL) comprises a broad area of research within the field of multi-agent systems. Several recent works have focused specifically on the study of communication approaches in MARL. While multiple communication methods have been proposed, these might still be too complex and not easily transferable to more practical contexts. One of the reasons for that is due to the use of the famous parameter sharing trick. In this paper, we investigate how independent learners in MARL that do not share parameters can communicate. We demonstrate that this setting might incur into some problems, to which we propose a new learning scheme as a solution. Our results show that, despite the challenges, independent agents can still learn communication strategies following our method. Additionally, we use this method to investigate how communication in MARL is affected by different network capacities, both for sharing and not sharing parameters. We observe that communication may not always be needed and that the chosen agent network sizes need to be considered when used together with communication in order to achieve efficient learning.
Learning Independently from Causality in Multi-Agent Environments
Nov 05, 2023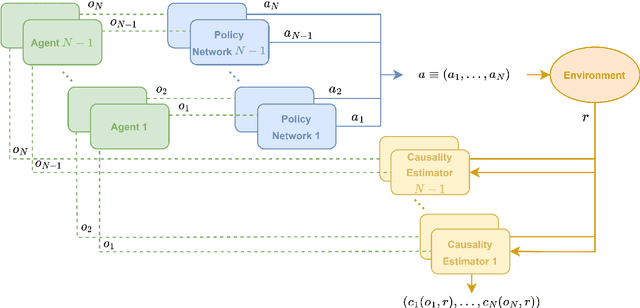
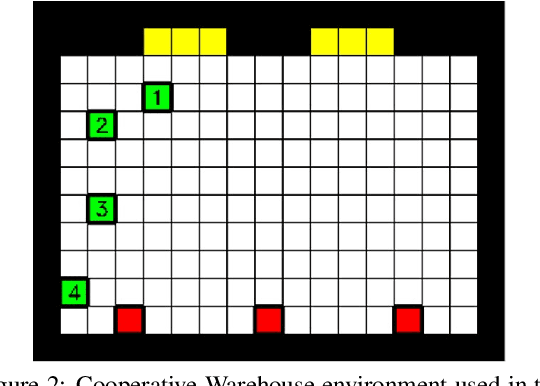
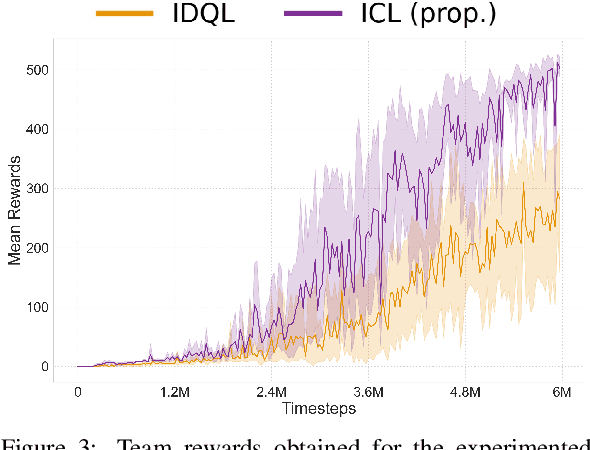
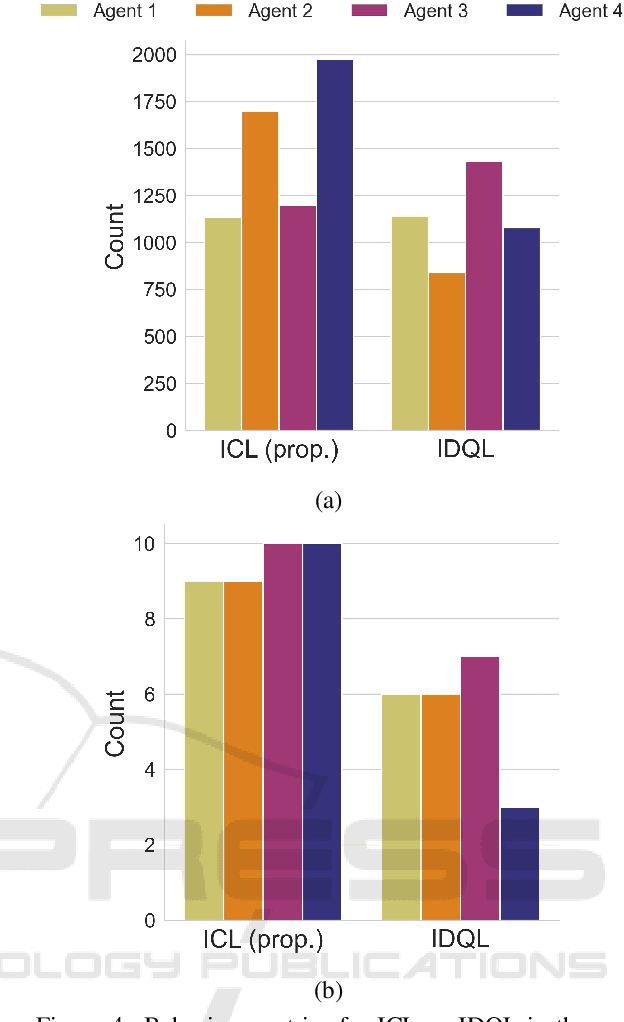
Multi-Agent Reinforcement Learning (MARL) comprises an area of growing interest in the field of machine learning. Despite notable advances, there are still problems that require investigation. The lazy agent pathology is a famous problem in MARL that denotes the event when some of the agents in a MARL team do not contribute to the common goal, letting the teammates do all the work. In this work, we aim to investigate this problem from a causality-based perspective. We intend to create the bridge between the fields of MARL and causality and argue about the usefulness of this link. We study a fully decentralised MARL setup where agents need to learn cooperation strategies and show that there is a causal relation between individual observations and the team reward. The experiments carried show how this relation can be used to improve independent agents in MARL, resulting not only on better performances as a team but also on the rise of more intelligent behaviours on individual agents.
Staged Reinforcement Learning for Complex Tasks through Decomposed Environments
Nov 05, 2023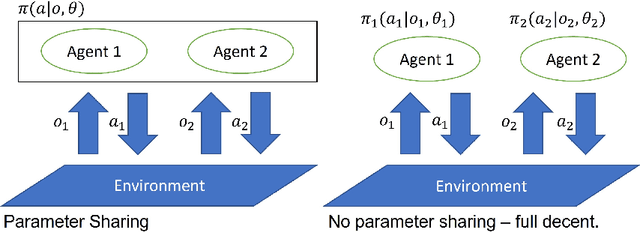
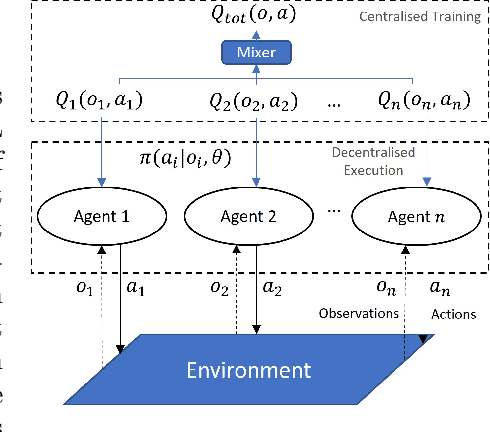
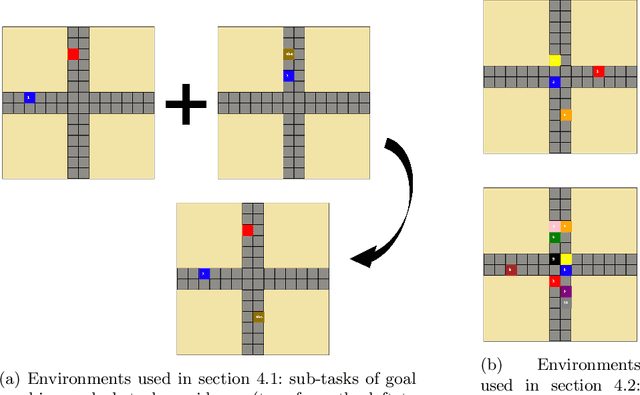
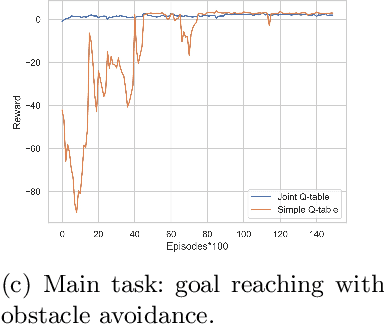
Reinforcement Learning (RL) is an area of growing interest in the field of artificial intelligence due to its many notable applications in diverse fields. Particularly within the context of intelligent vehicle control, RL has made impressive progress. However, currently it is still in simulated controlled environments where RL can achieve its full super-human potential. Although how to apply simulation experience in real scenarios has been studied, how to approximate simulated problems to the real dynamic problems is still a challenge. In this paper, we discuss two methods that approximate RL problems to real problems. In the context of traffic junction simulations, we demonstrate that, if we can decompose a complex task into multiple sub-tasks, solving these tasks first can be advantageous to help minimising possible occurrences of catastrophic events in the complex task. From a multi-agent perspective, we introduce a training structuring mechanism that exploits the use of experience learned under the popular paradigm called Centralised Training Decentralised Execution (CTDE). This experience can then be leveraged in fully decentralised settings that are conceptually closer to real settings, where agents often do not have access to a central oracle and must be treated as isolated independent units. The results show that the proposed approaches improve agents performance in complex tasks related to traffic junctions, minimising potential safety-critical problems that might happen in these scenarios. Although still in simulation, the investigated situations are conceptually closer to real scenarios and thus, with these results, we intend to motivate further research in the subject.
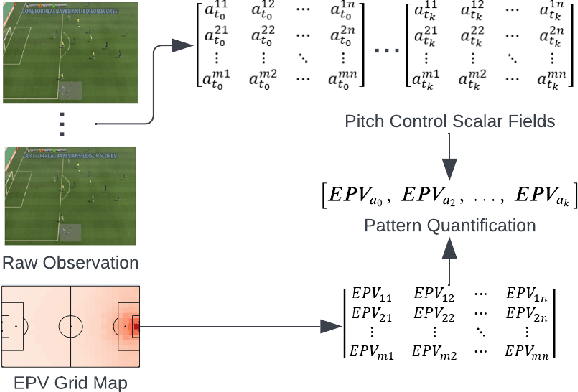
Passing Heatmap Prediction Based on Transformer Model and Tracking Data
Sep 04, 2023Although the data-driven analysis of football players' performance has been developed for years, most research only focuses on the on-ball event including shots and passes, while the off-ball movement remains a little-explored area in this domain. Players' contributions to the whole match are evaluated unfairly, those who have more chances to score goals earn more credit than others, while the indirect and unnoticeable impact that comes from continuous movement has been ignored. This research presents a novel deep-learning network architecture which is capable to predict the potential end location of passes and how players' movement before the pass affects the final outcome. Once analysed more than 28,000 pass events, a robust prediction can be achieved with more than 0.7 Top-1 accuracy. And based on the prediction, a better understanding of the pitch control and pass option could be reached to measure players' off-ball movement contribution to defensive performance. Moreover, this model could provide football analysts a better tool and metric to understand how players' movement over time contributes to the game strategy and final victory.
Discovering Causality for Efficient Cooperation in Multi-Agent Environments
Jun 20, 2023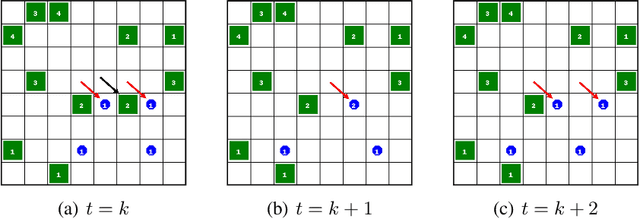
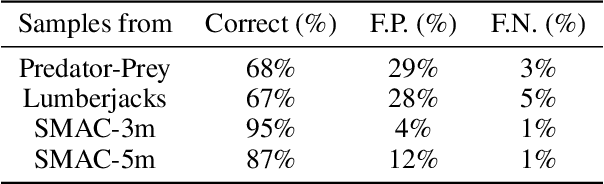
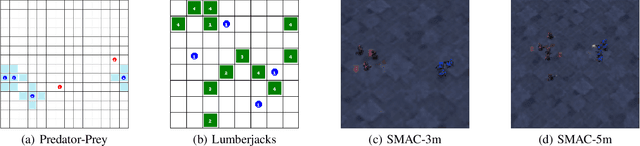
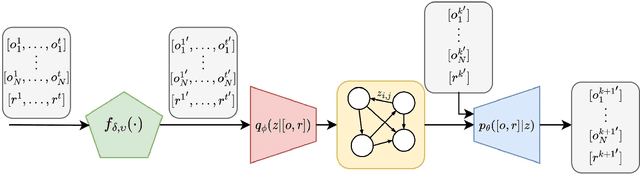
In cooperative Multi-Agent Reinforcement Learning (MARL) agents are required to learn behaviours as a team to achieve a common goal. However, while learning a task, some agents may end up learning sub-optimal policies, not contributing to the objective of the team. Such agents are called lazy agents due to their non-cooperative behaviours that may arise from failing to understand whether they caused the rewards. As a consequence, we observe that the emergence of cooperative behaviours is not necessarily a byproduct of being able to solve a task as a team. In this paper, we investigate the applications of causality in MARL and how it can be applied in MARL to penalise these lazy agents. We observe that causality estimations can be used to improve the credit assignment to the agents and show how it can be leveraged to improve independent learning in MARL. Furthermore, we investigate how Amortized Causal Discovery can be used to automate causality detection within MARL environments. The results demonstrate that causality relations between individual observations and the team reward can be used to detect and punish lazy agents, making them develop more intelligent behaviours. This results in improvements not only in the overall performances of the team but also in their individual capabilities. In addition, results show that Amortized Causal Discovery can be used efficiently to find causal relations in MARL.
Embedding Contextual Information through Reward Shaping in Multi-Agent Learning: A Case Study from Google Football
Mar 25, 2023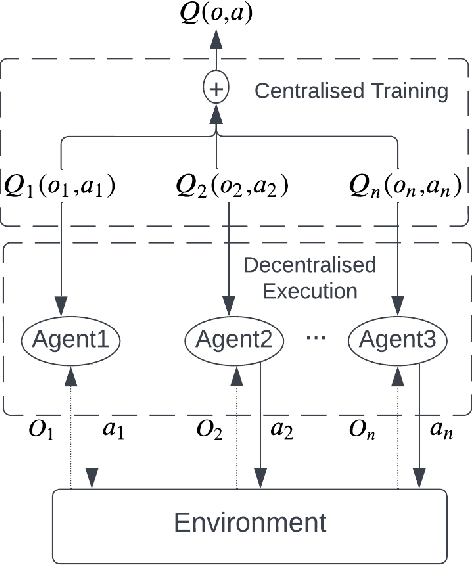
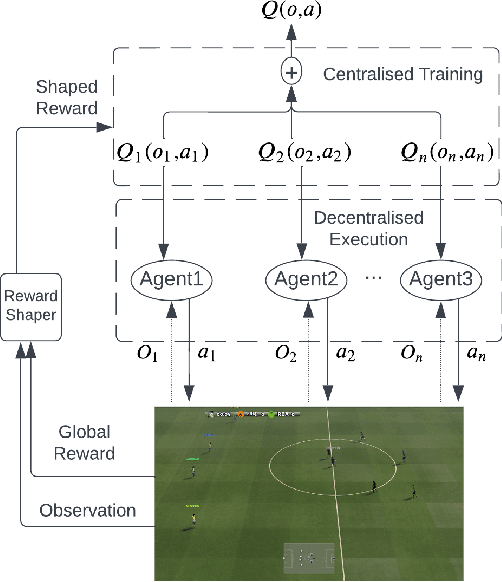
Artificial Intelligence has been used to help human complete difficult tasks in complicated environments by providing optimized strategies for decision-making or replacing the manual labour. In environments including multiple agents, such as football, the most common methods to train agents are Imitation Learning and Multi-Agent Reinforcement Learning (MARL). However, the agents trained by Imitation Learning cannot outperform the expert demonstrator, which makes humans hardly get new insights from the learnt policy. Besides, MARL is prone to the credit assignment problem. In environments with sparse reward signal, this method can be inefficient. The objective of our research is to create a novel reward shaping method by embedding contextual information in reward function to solve the aforementioned challenges. We demonstrate this in the Google Research Football (GRF) environment. We quantify the contextual information extracted from game state observation and use this quantification together with original sparse reward to create the shaped reward. The experiment results in the GRF environment prove that our reward shaping method is a useful addition to state-of-the-art MARL algorithms for training agents in environments with sparse reward signal.
Causality Detection for Efficient Multi-Agent Reinforcement Learning
Mar 24, 2023When learning a task as a team, some agents in Multi-Agent Reinforcement Learning (MARL) may fail to understand their true impact in the performance of the team. Such agents end up learning sub-optimal policies, demonstrating undesired lazy behaviours. To investigate this problem, we start by formalising the use of temporal causality applied to MARL problems. We then show how causality can be used to penalise such lazy agents and improve their behaviours. By understanding how their local observations are causally related to the team reward, each agent in the team can adjust their individual credit based on whether they helped to cause the reward or not. We show empirically that using causality estimations in MARL improves not only the holistic performance of the team, but also the individual capabilities of each agent. We observe that the improvements are consistent in a set of different environments.