 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Independent Communication in Multi-Agent Reinforcement Learning
Jan 26, 2024



Multi-Agent Reinforcement Learning (MARL) comprises a broad area of research within the field of multi-agent systems. Several recent works have focused specifically on the study of communication approaches in MARL. While multiple communication methods have been proposed, these might still be too complex and not easily transferable to more practical contexts. One of the reasons for that is due to the use of the famous parameter sharing trick. In this paper, we investigate how independent learners in MARL that do not share parameters can communicate. We demonstrate that this setting might incur into some problems, to which we propose a new learning scheme as a solution. Our results show that, despite the challenges, independent agents can still learn communication strategies following our method. Additionally, we use this method to investigate how communication in MARL is affected by different network capacities, both for sharing and not sharing parameters. We observe that communication may not always be needed and that the chosen agent network sizes need to be considered when used together with communication in order to achieve efficient learning.
Learning Independently from Causality in Multi-Agent Environments
Nov 05, 2023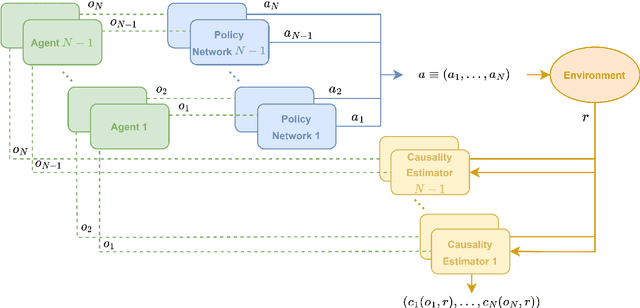
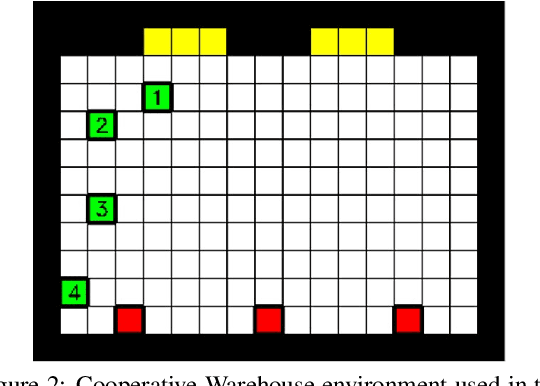
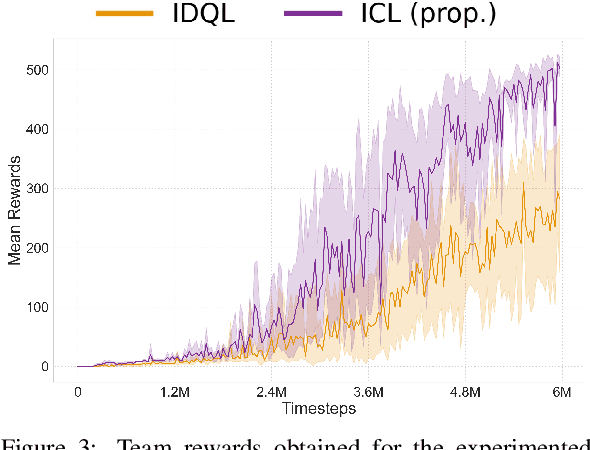
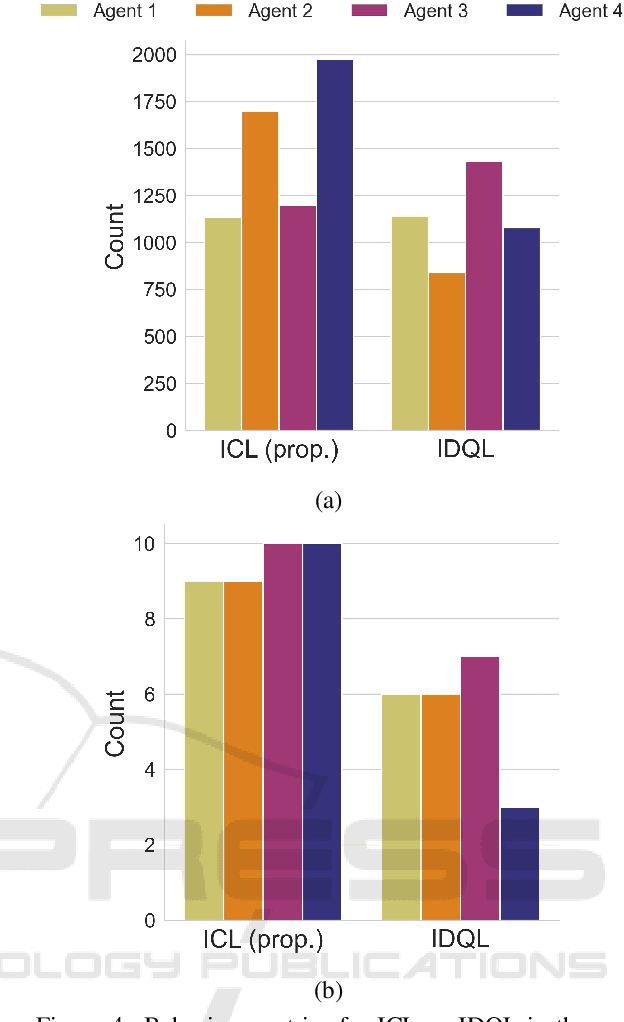
Multi-Agent Reinforcement Learning (MARL) comprises an area of growing interest in the field of machine learning. Despite notable advances, there are still problems that require investigation. The lazy agent pathology is a famous problem in MARL that denotes the event when some of the agents in a MARL team do not contribute to the common goal, letting the teammates do all the work. In this work, we aim to investigate this problem from a causality-based perspective. We intend to create the bridge between the fields of MARL and causality and argue about the usefulness of this link. We study a fully decentralised MARL setup where agents need to learn cooperation strategies and show that there is a causal relation between individual observations and the team reward. The experiments carried show how this relation can be used to improve independent agents in MARL, resulting not only on better performances as a team but also on the rise of more intelligent behaviours on individual agents.
Staged Reinforcement Learning for Complex Tasks through Decomposed Environments
Nov 05, 2023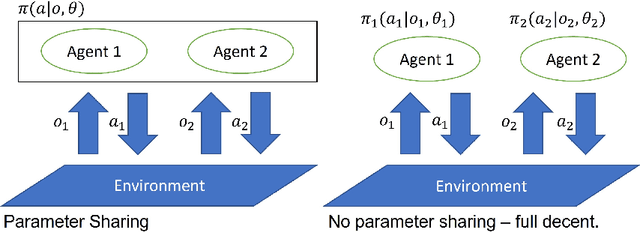
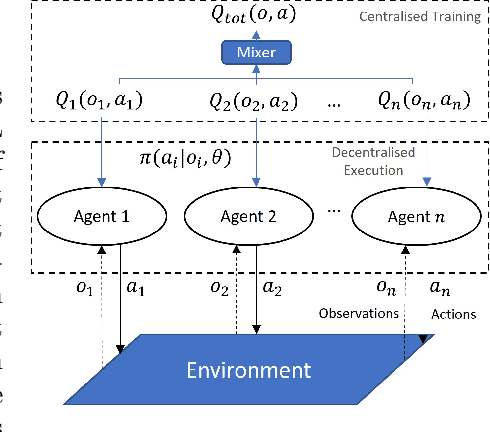
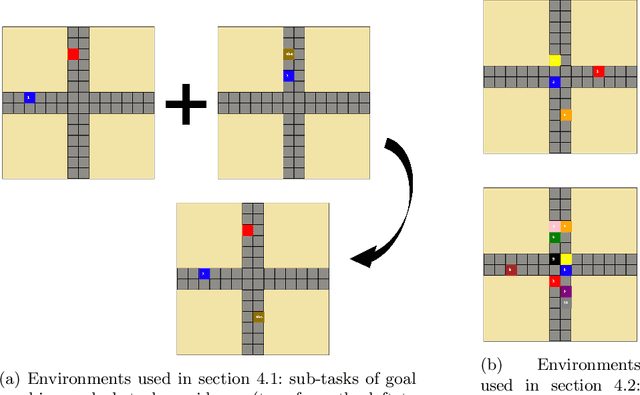
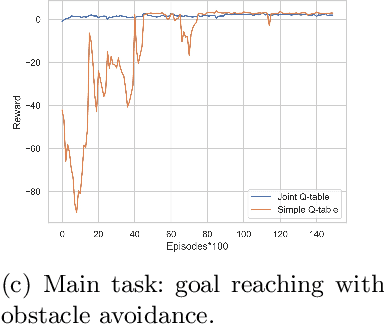
Reinforcement Learning (RL) is an area of growing interest in the field of artificial intelligence due to its many notable applications in diverse fields. Particularly within the context of intelligent vehicle control, RL has made impressive progress. However, currently it is still in simulated controlled environments where RL can achieve its full super-human potential. Although how to apply simulation experience in real scenarios has been studied, how to approximate simulated problems to the real dynamic problems is still a challenge. In this paper, we discuss two methods that approximate RL problems to real problems. In the context of traffic junction simulations, we demonstrate that, if we can decompose a complex task into multiple sub-tasks, solving these tasks first can be advantageous to help minimising possible occurrences of catastrophic events in the complex task. From a multi-agent perspective, we introduce a training structuring mechanism that exploits the use of experience learned under the popular paradigm called Centralised Training Decentralised Execution (CTDE). This experience can then be leveraged in fully decentralised settings that are conceptually closer to real settings, where agents often do not have access to a central oracle and must be treated as isolated independent units. The results show that the proposed approaches improve agents performance in complex tasks related to traffic junctions, minimising potential safety-critical problems that might happen in these scenarios. Although still in simulation, the investigated situations are conceptually closer to real scenarios and thus, with these results, we intend to motivate further research in the subject.
Discovering Causality for Efficient Cooperation in Multi-Agent Environments
Jun 20, 2023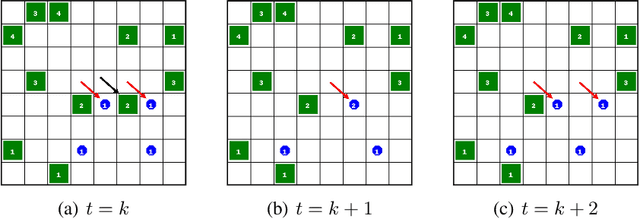
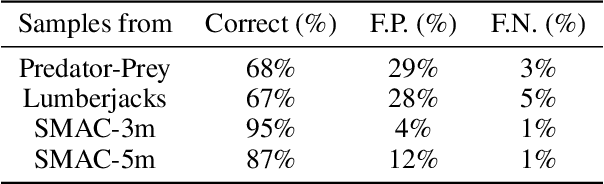
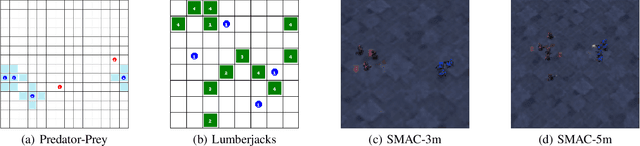
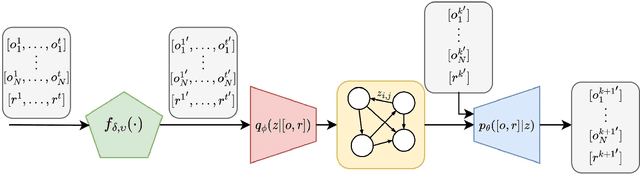
In cooperative Multi-Agent Reinforcement Learning (MARL) agents are required to learn behaviours as a team to achieve a common goal. However, while learning a task, some agents may end up learning sub-optimal policies, not contributing to the objective of the team. Such agents are called lazy agents due to their non-cooperative behaviours that may arise from failing to understand whether they caused the rewards. As a consequence, we observe that the emergence of cooperative behaviours is not necessarily a byproduct of being able to solve a task as a team. In this paper, we investigate the applications of causality in MARL and how it can be applied in MARL to penalise these lazy agents. We observe that causality estimations can be used to improve the credit assignment to the agents and show how it can be leveraged to improve independent learning in MARL. Furthermore, we investigate how Amortized Causal Discovery can be used to automate causality detection within MARL environments. The results demonstrate that causality relations between individual observations and the team reward can be used to detect and punish lazy agents, making them develop more intelligent behaviours. This results in improvements not only in the overall performances of the team but also in their individual capabilities. In addition, results show that Amortized Causal Discovery can be used efficiently to find causal relations in MARL.
Embedding Contextual Information through Reward Shaping in Multi-Agent Learning: A Case Study from Google Football
Mar 25, 2023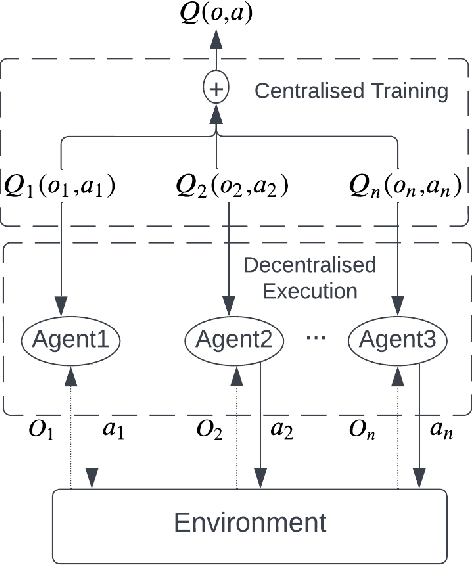
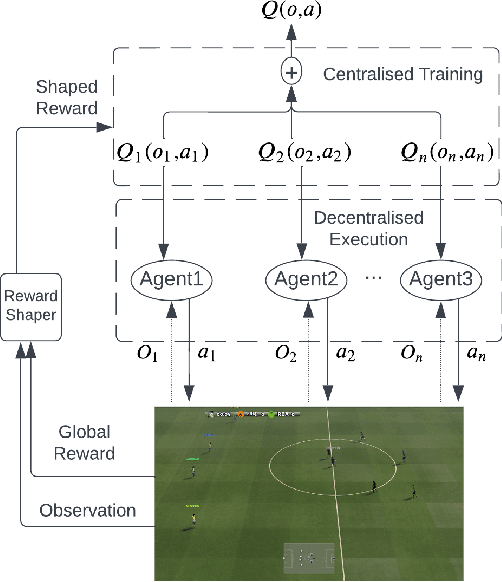
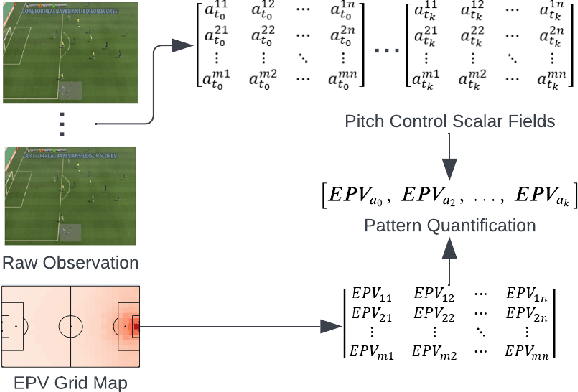
Artificial Intelligence has been used to help human complete difficult tasks in complicated environments by providing optimized strategies for decision-making or replacing the manual labour. In environments including multiple agents, such as football, the most common methods to train agents are Imitation Learning and Multi-Agent Reinforcement Learning (MARL). However, the agents trained by Imitation Learning cannot outperform the expert demonstrator, which makes humans hardly get new insights from the learnt policy. Besides, MARL is prone to the credit assignment problem. In environments with sparse reward signal, this method can be inefficient. The objective of our research is to create a novel reward shaping method by embedding contextual information in reward function to solve the aforementioned challenges. We demonstrate this in the Google Research Football (GRF) environment. We quantify the contextual information extracted from game state observation and use this quantification together with original sparse reward to create the shaped reward. The experiment results in the GRF environment prove that our reward shaping method is a useful addition to state-of-the-art MARL algorithms for training agents in environments with sparse reward signal.
Causality Detection for Efficient Multi-Agent Reinforcement Learning
Mar 24, 2023When learning a task as a team, some agents in Multi-Agent Reinforcement Learning (MARL) may fail to understand their true impact in the performance of the team. Such agents end up learning sub-optimal policies, demonstrating undesired lazy behaviours. To investigate this problem, we start by formalising the use of temporal causality applied to MARL problems. We then show how causality can be used to penalise such lazy agents and improve their behaviours. By understanding how their local observations are causally related to the team reward, each agent in the team can adjust their individual credit based on whether they helped to cause the reward or not. We show empirically that using causality estimations in MARL improves not only the holistic performance of the team, but also the individual capabilities of each agent. We observe that the improvements are consistent in a set of different environments.