 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Neural Optimization Based Antenna Coding Design for Pixel Antenna Systems
Jun 19, 2026Pixel antennas enable highly radiation pattern reconfigurability to enhance wireless systems, but its antenna coding design, that is optimizing the states of switches embedded in pixel antennas, remains an NP-hard challenge. Conventional approaches for antenna coding design typically rely on heuristic search algorithms, which suffer from high computational complexity. To overcome this issue, we propose a novel efficient data-free optimization algorithm called physics-informed neural optimizer (PINO) for antenna coding design. By integrating a deep convolutional neural network prior and a Gumbel-Sigmoid continuous relaxation into a differentiable physics engine, the proposed algorithm transforms the binary optimization problem into a continuous differentiable problem, which enables the antenna coding optimization problem to be efficiently solved via gradient descent. Simulation results demonstrate that the proposed algorithm outperforms the heuristic search based algorithms, reducing computational time while achieving higher average channel gain.
Real-Time Network Traffic Forecasting with Missing Data: A Generative Model Approach
Jun 11, 2025Real-time network traffic forecasting is crucial for network management and early resource allocation. Existing network traffic forecasting approaches operate under the assumption that the network traffic data is fully observed. However, in practical scenarios, the collected data are often incomplete due to various human and natural factors. In this paper, we propose a generative model approach for real-time network traffic forecasting with missing data. Firstly, we model the network traffic forecasting task as a tensor completion problem. Secondly, we incorporate a pre-trained generative model to achieve the low-rank structure commonly associated with tensor completion. The generative model effectively captures the intrinsic low-rank structure of network traffic data during pre-training and enables the mapping from a compact latent representation to the tensor space. Thirdly, rather than directly optimizing the high-dimensional tensor, we optimize its latent representation, which simplifies the optimization process and enables real-time forecasting. We also establish a theoretical recovery guarantee that quantifies the error bound of the proposed approach. Experiments on real-world datasets demonstrate that our approach achieves accurate network traffic forecasting within 100 ms, with a mean absolute error (MAE) below 0.002, as validated on the Abilene dataset.
Learning Design-Score Manifold to Guide Diffusion Models for Offline Optimization
Jun 06, 2025Optimizing complex systems, from discovering therapeutic drugs to designing high-performance materials, remains a fundamental challenge across science and engineering, as the underlying rules are often unknown and costly to evaluate. Offline optimization aims to optimize designs for target scores using pre-collected datasets without system interaction. However, conventional approaches may fail beyond training data, predicting inaccurate scores and generating inferior designs. This paper introduces ManGO, a diffusion-based framework that learns the design-score manifold, capturing the design-score interdependencies holistically. Unlike existing methods that treat design and score spaces in isolation, ManGO unifies forward prediction and backward generation, attaining generalization beyond training data. Key to this is its derivative-free guidance for conditional generation, coupled with adaptive inference-time scaling that dynamically optimizes denoising paths. Extensive evaluations demonstrate that ManGO outperforms 24 single- and 10 multi-objective optimization methods across diverse domains, including synthetic tasks, robot control, material design, DNA sequence, and real-world engineering optimization.
Is Locational Marginal Price All You Need for Locational Marginal Emission?
Nov 18, 2024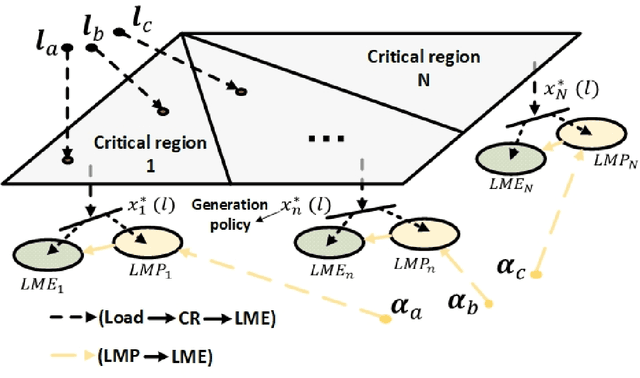
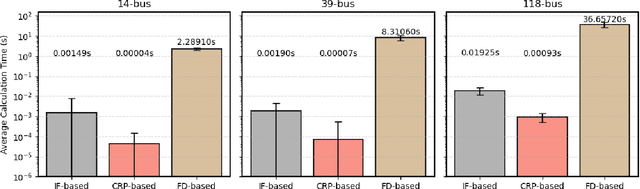
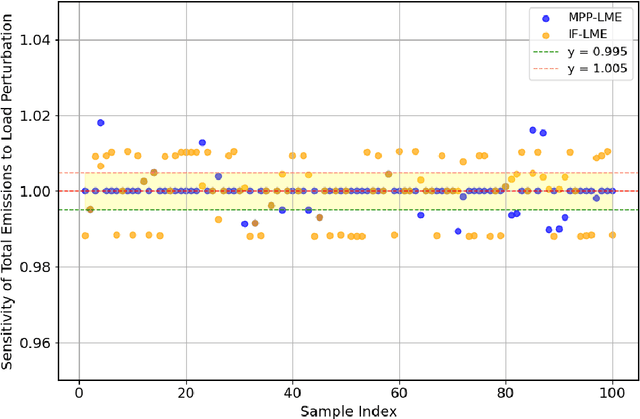
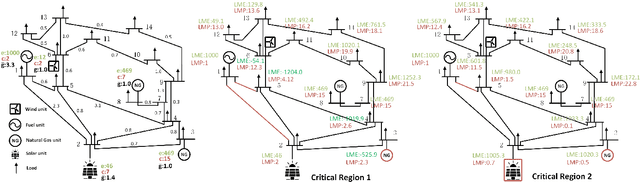
Growing concerns over climate change call for improved techniques for estimating and quantifying the greenhouse gas emissions associated with electricity generation and transmission. Among the emission metrics designated for power grids, locational marginal emission (LME) can provide system operators and electricity market participants with valuable information on the emissions associated with electricity usage at various locations in the power network. In this paper, by investigating the operating patterns and physical interpretations of marginal emissions and costs in the security-constrained economic dispatch (SCED) problem, we identify and draw the exact connection between locational marginal price (LMP) and LME. Such interpretation helps instantly derive LME given nodal demand vectors or LMP, and also reveals the interplay between network congestion and nodal emission pattern. Our proposed approach helps reduce the computation time of LME by an order of magnitude compared to analytical approaches, while it can also serve as a plug-and-play module accompanied by an off-the-shelf market clearing and LMP calculation process.
Bayesian Federated Model Compression for Communication and Computation Efficiency
Apr 11, 2024In this paper, we investigate Bayesian model compression in federated learning (FL) to construct sparse models that can achieve both communication and computation efficiencies. We propose a decentralized Turbo variational Bayesian inference (D-Turbo-VBI) FL framework where we firstly propose a hierarchical sparse prior to promote a clustered sparse structure in the weight matrix. Then, by carefully integrating message passing and VBI with a decentralized turbo framework, we propose the D-Turbo-VBI algorithm which can (i) reduce both upstream and downstream communication overhead during federated training, and (ii) reduce the computational complexity during local inference. Additionally, we establish the convergence property for thr proposed D-Turbo-VBI algorithm. Simulation results show the significant gain of our proposed algorithm over the baselines in reducing communication overhead during federated training and computational complexity of final model.
Federated Prompt-based Decision Transformer for Customized VR Services in Mobile Edge Computing System
Feb 15, 2024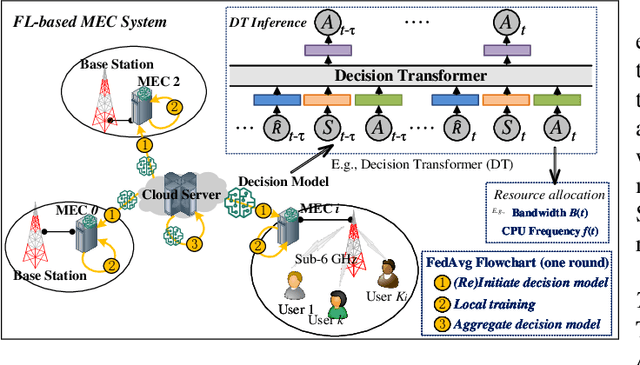
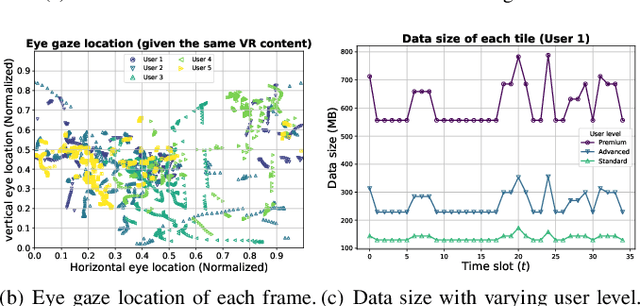
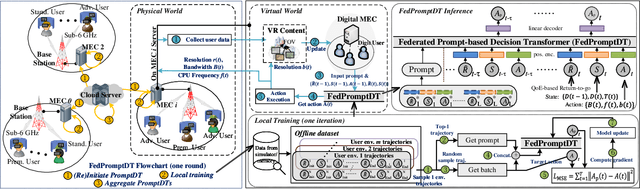
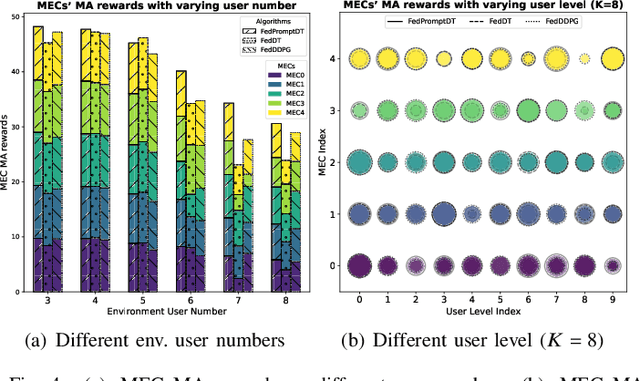
This paper investigates resource allocation to provide heterogeneous users with customized virtual reality (VR) services in a mobile edge computing (MEC) system. We first introduce a quality of experience (QoE) metric to measure user experience, which considers the MEC system's latency, user attention levels, and preferred resolutions. Then, a QoE maximization problem is formulated for resource allocation to ensure the highest possible user experience,which is cast as a reinforcement learning problem, aiming to learn a generalized policy applicable across diverse user environments for all MEC servers. To learn the generalized policy, we propose a framework that employs federated learning (FL) and prompt-based sequence modeling to pre-train a common decision model across MEC servers, which is named FedPromptDT. Using FL solves the problem of insufficient local MEC data while protecting user privacy during offline training. The design of prompts integrating user-environment cues and user-preferred allocation improves the model's adaptability to various user environments during online execution.
Mode Connectivity and Data Heterogeneity of Federated Learning
Sep 29, 2023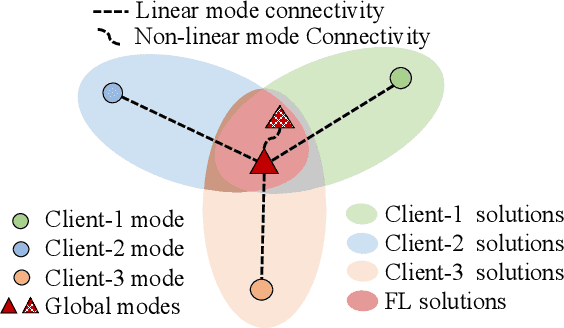
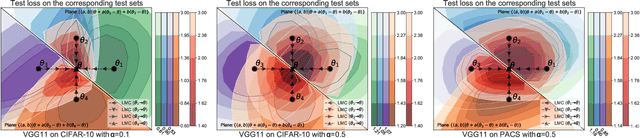
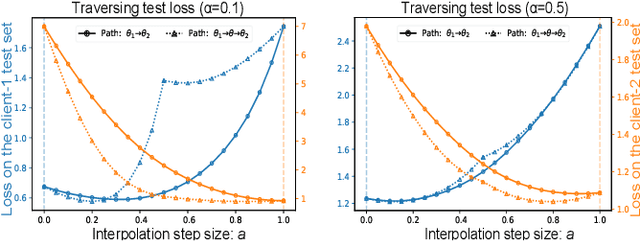
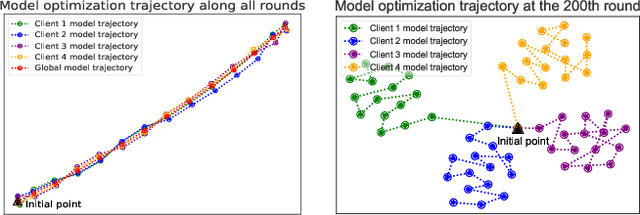
Federated learning (FL) enables multiple clients to train a model while keeping their data private collaboratively. Previous studies have shown that data heterogeneity between clients leads to drifts across client updates. However, there are few studies on the relationship between client and global modes, making it unclear where these updates end up drifting. We perform empirical and theoretical studies on this relationship by utilizing mode connectivity, which measures performance change (i.e., connectivity) along parametric paths between different modes. Empirically, reducing data heterogeneity makes the connectivity on different paths more similar, forming more low-error overlaps between client and global modes. We also find that a barrier to connectivity occurs when linearly connecting two global modes, while it disappears with considering non-linear mode connectivity. Theoretically, we establish a quantitative bound on the global-mode connectivity using mean-field theory or dropout stability. The bound demonstrates that the connectivity improves when reducing data heterogeneity and widening trained models. Numerical results further corroborate our analytical findings.
Understanding Model Averaging in Federated Learning on Heterogeneous Data
May 20, 2023Model averaging, a widely adopted technique in federated learning (FL), aggregates multiple client models trained on heterogeneous data to obtain a well-performed global model. However, the rationale behind its success is not well understood. To shed light on this issue, we investigate the geometric properties of model averaging by visualizing the loss/error landscape. The geometrical visualization shows that the client models surround the global model within a common basin, and the global model may deviate from the bottom of the basin even though it performs better than the client models. To further understand this phenomenon, we decompose the expected prediction error of the global model into five factors related to client models. Specifically, we find that the global-model error after early training mainly comes from i) the client-model error on non-overlapping data between client datasets and the global dataset and ii) the maximal distance between the global and client models. Inspired by these findings, we propose adopting iterative moving averaging (IMA) on global models to reduce the prediction error and limiting client exploration to control the maximal distance at the late training. Our experiments demonstrate that IMA significantly improves the accuracy and training speed of existing FL methods on benchmark datasets with various data heterogeneity.
Structured Bayesian Compression for Deep Neural Networks Based on The Turbo-VBI Approach
Feb 21, 2023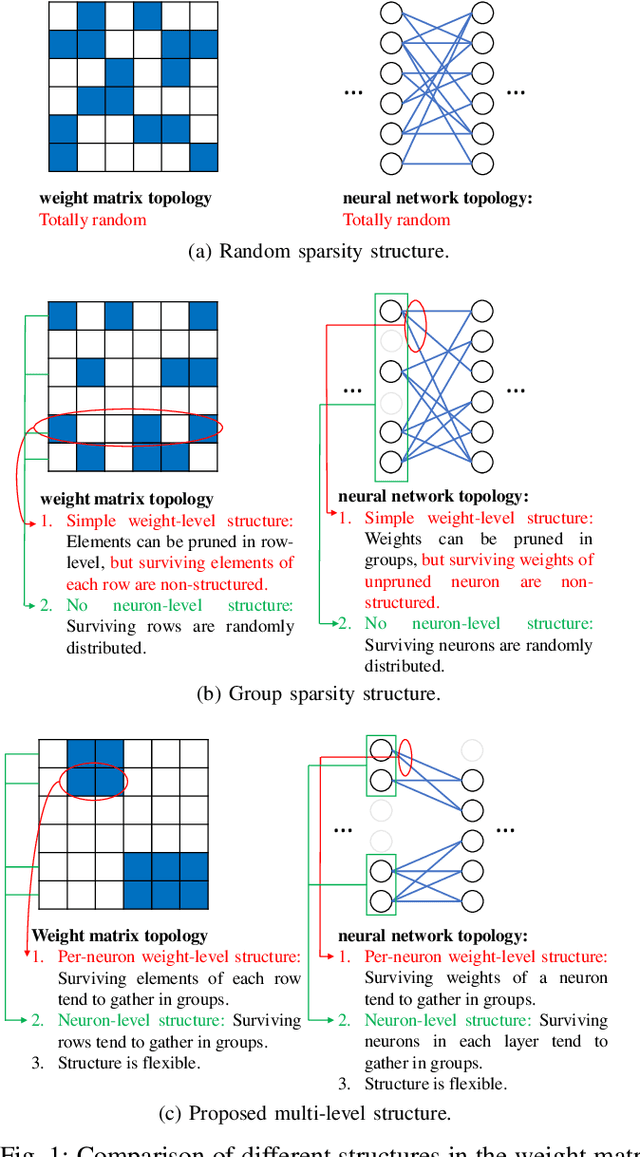
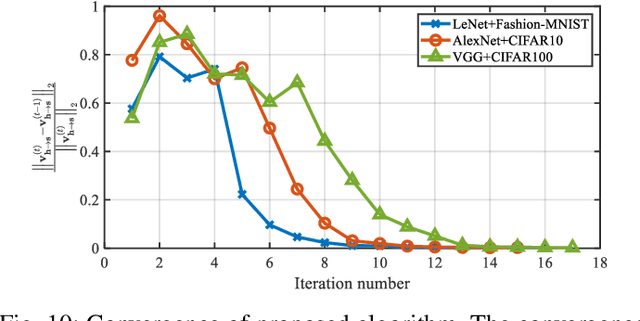
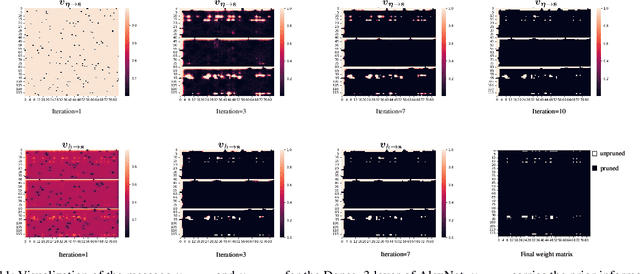
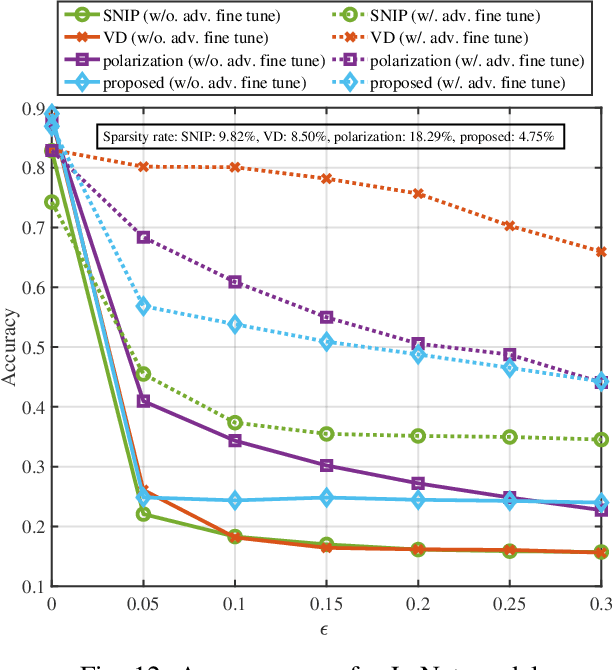
With the growth of neural network size, model compression has attracted increasing interest in recent research. As one of the most common techniques, pruning has been studied for a long time. By exploiting the structured sparsity of the neural network, existing methods can prune neurons instead of individual weights. However, in most existing pruning methods, surviving neurons are randomly connected in the neural network without any structure, and the non-zero weights within each neuron are also randomly distributed. Such irregular sparse structure can cause very high control overhead and irregular memory access for the hardware and even increase the neural network computational complexity. In this paper, we propose a three-layer hierarchical prior to promote a more regular sparse structure during pruning. The proposed three-layer hierarchical prior can achieve per-neuron weight-level structured sparsity and neuron-level structured sparsity. We derive an efficient Turbo-variational Bayesian inferencing (Turbo-VBI) algorithm to solve the resulting model compression problem with the proposed prior. The proposed Turbo-VBI algorithm has low complexity and can support more general priors than existing model compression algorithms. Simulation results show that our proposed algorithm can promote a more regular structure in the pruned neural networks while achieving even better performance in terms of compression rate and inferencing accuracy compared with the baselines.
Bi-directional Digital Twin and Edge Computing in the Metaverse
Nov 16, 2022The Metaverse has emerged to extend our lifestyle beyond physical limitations. As essential components in the Metaverse, digital twins (DTs) are the digital replicas of physical items. End users access the Metaverse using a variety of devices (e.g., head-mounted devices (HMDs)), mostly lightweight. Multi-access edge computing (MEC) and edge networks provide responsive services to the end users, leading to an immersive Metaverse experience. With the anticipation to represent physical objects, end users, and edge computing systems as DTs in the Metaverse, the construction of these DTs and the interplay between them have not been investigated. In this paper, we discuss the bidirectional reliance between the DT and the MEC system and investigate the creation of DTs of objects and users on the MEC servers and DT-assisted edge computing (DTEC). We also study the interplay between the DTs and DTECs to allocate the resources fairly and adequately and provide an immersive experience in the Metaverse. Owing to the dynamic network states (e.g., channel states) and mobility of the users, we discuss the interplay between local DTECs (on local MEC servers) and the global DTEC (on cloud server) to cope with the handover among MEC servers and avoid intermittent Metaverse services.