 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pontryagin Method of Model-based Reinforcement Learning via Hamiltonian Actor-Critic
Mar 30, 2026Model-based reinforcement learning (MBRL) improves sample efficiency by leveraging learned dynamics models for policy optimization. However, the effectiveness of methods such as actor-critic is often limited by compounding model errors, which degrade long-horizon value estimation. Existing approaches, such as Model-Based Value Expansion (MVE), partially mitigate this issue through multi-step rollouts, but remain sensitive to rollout horizon selection and residual model bias. Motivated by the Pontryagin Maximum Principle (PMP), we propose Hamiltonian Actor-Critic (HAC), a model-based approach that eliminates explicit value function learning by directly optimizing a Hamiltonian defined over the learned dynamics and reward for deterministic systems. By avoiding value approximation, HAC reduces sensitivity to model errors while admitting convergence guarantees. Extensive experiments on continuous control benchmarks, in both online and offline RL settings, demonstrate that HAC outperforms model-free and MVE-based baselines in control performance, convergence speed, and robustness to distributional shift, including out-of-distribution (OOD) scenarios. In offline settings with limited data, HAC matches or exceeds state-of-the-art methods, highlighting its strong sample efficiency.
STO-RL: Offline RL under Sparse Rewards via LLM-Guided Subgoal Temporal Order
Jan 13, 2026Offline reinforcement learning (RL) enables policy learning from pre-collected datasets, avoiding costly and risky online interactions, but it often struggles with long-horizon tasks involving sparse rewards. Existing goal-conditioned and hierarchical offline RL methods decompose such tasks and generate intermediate rewards to mitigate limitations of traditional offline RL, but usually overlook temporal dependencies among subgoals and rely on imprecise reward shaping, leading to suboptimal policies. To address these issues, we propose STO-RL (Offline RL using LLM-Guided Subgoal Temporal Order), an offline RL framework that leverages large language models (LLMs) to generate temporally ordered subgoal sequences and corresponding state-to-subgoal-stage mappings. Using this temporal structure, STO-RL applies potential-based reward shaping to transform sparse terminal rewards into dense, temporally consistent signals, promoting subgoal progress while avoiding suboptimal solutions. The resulting augmented dataset with shaped rewards enables efficient offline training of high-performing policies. Evaluations on four discrete and continuous sparse-reward benchmarks demonstrate that STO-RL consistently outperforms state-of-the-art offline goal-conditioned and hierarchical RL baselines, achieving faster convergence, higher success rates, and shorter trajectories. Ablation studies further confirm STO-RL's robustness to imperfect or noisy LLM-generated subgoal sequences, demonstrating that LLM-guided subgoal temporal structures combined with theoretically grounded reward shaping provide a practical and scalable solution for long-horizon offline RL.
Scaling Laws of Machine Learning for Optimal Power Flow
Jan 06, 2026Optimal power flow (OPF) is one of the fundamental tasks for power system operations. While machine learning (ML) approaches such as deep neural networks (DNNs) have been widely studied to enhance OPF solution speed and performance, their practical deployment faces two critical scaling questions: What is the minimum training data volume required for reliable results? How should ML models' complexity balance accuracy with real-time computational limits? Existing studies evaluate discrete scenarios without quantifying these scaling relationships, leading to trial-and-error-based ML development in real-world applications. This work presents the first systematic scaling study for ML-based OPF across two dimensions: data scale (0.1K-40K training samples) and compute scale (multiple NN architectures with varying FLOPs). Our results reveal consistent power-law relationships on both DNNs and physics-informed NNs (PINNs) between each resource dimension and three core performance metrics: prediction error (MAE), constraint violations and speed. We find that for ACOPF, the accuracy metric scales with dataset size and training compute. These scaling laws enable predictable and principled ML pipeline design for OPF. We further identify the divergence between prediction accuracy and constraint feasibility and characterize the compute-optimal frontier. This work provides quantitative guidance for ML-OPF design and deployments.
DeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025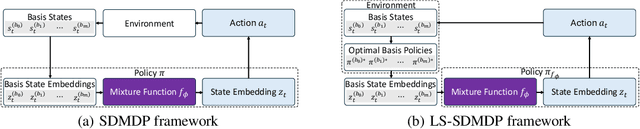
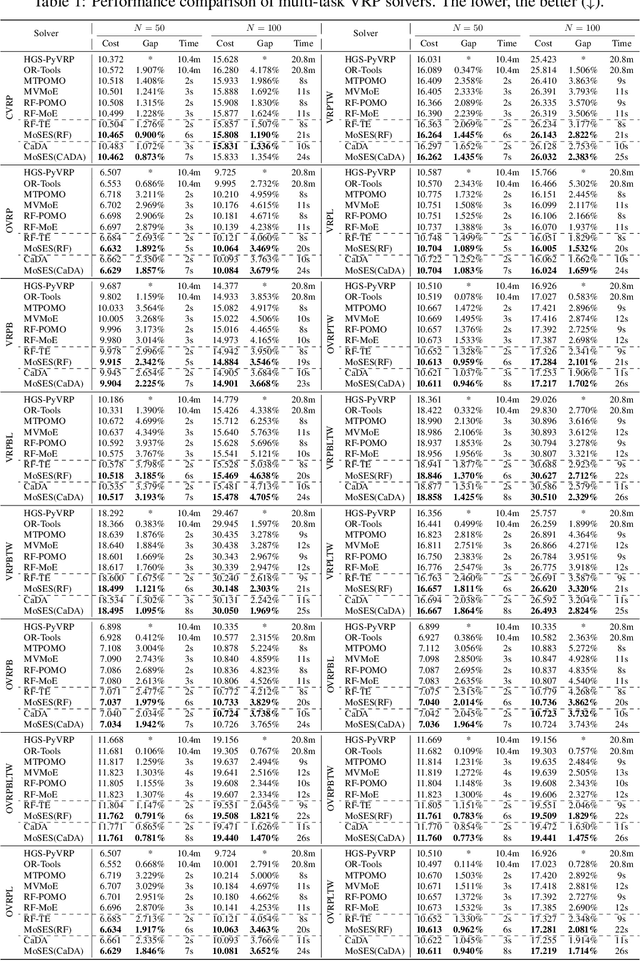
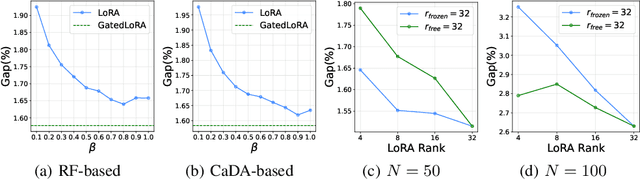
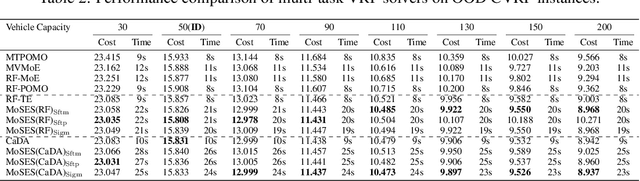
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.
BEAVER: Building Environments with Assessable Variation for Evaluating Multi-Objective Reinforcement Learning
Jul 10, 2025Recent years have seen significant advancements in designing reinforcement learning (RL)-based agents for building energy management. While individual success is observed in simulated or controlled environments, the scalability of RL approaches in terms of efficiency and generalization across building dynamics and operational scenarios remains an open question. In this work, we formally characterize the generalization space for the cross-environment, multi-objective building energy management task, and formulate the multi-objective contextual RL problem. Such a formulation helps understand the challenges of transferring learned policies across varied operational contexts such as climate and heat convection dynamics under multiple control objectives such as comfort level and energy consumption. We provide a principled way to parameterize such contextual information in realistic building RL environments, and construct a novel benchmark to facilitate the evaluation of generalizable RL algorithms in practical building control tasks. Our results show that existing multi-objective RL methods are capable of achieving reasonable trade-offs between conflicting objectives. However, their performance degrades under certain environment variations, underscoring the importance of incorporating dynamics-dependent contextual information into the policy learning process.
Open Datasets for Grid Modeling and Visualization: An Alberta Power Network Case
Apr 10, 2025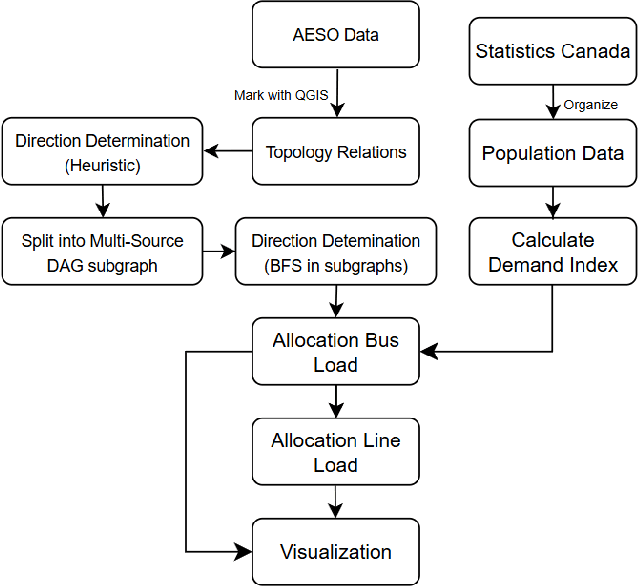

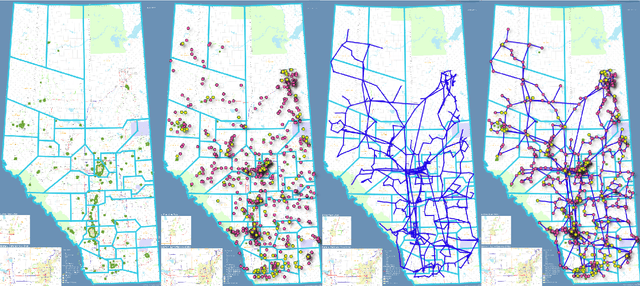

In the power and energy industry, multiple entities in grid operational logs are frequently recorded and updated. Thanks to recent advances in IT facilities and smart metering services, a variety of datasets such as system load, generation mix, and grid connection are often publicly available. While these resources are valuable in evaluating power grid's operational conditions and system resilience, the lack of fine-grained, accurate locational information constrain the usage of current data, which further hinders the development of smart grid and renewables integration. For instance, electricity end users are not aware of nodal generation mix or carbon emissions, while the general public have limited understanding about the effect of demand response or renewables integration if only the whole system's demands and generations are available. In this work, we focus on recovering power grid topology and line flow directions from open public dataset. Taking the Alberta grid as a working example, we start from mapping multi-modal power system datasets to the grid topology integrated with geographical information. By designing a novel optimization-based scheme to recover line flow directions, we are able to analyze and visualize the interactions between generations and demand vectors in an efficient manner. Proposed research is fully open-sourced and highly generalizable, which can help model and visualize grid information, create synthetic dataset, and facilitate analytics and decision-making framework for clean energy transition.
From Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes
Apr 07, 2025Detecting deepfakes has been an increasingly important topic, especially given the rapid development of AI generation techniques. In this paper, we ask: How can we build a universal detection framework that is effective for most facial deepfakes? One significant challenge is the wide variety of deepfake generators available, resulting in varying forgery artifacts (e.g., lighting inconsistency, color mismatch, etc). But should we ``teach" the detector to learn all these artifacts separately? It is impossible and impractical to elaborate on them all. So the core idea is to pinpoint the more common and general artifacts across different deepfakes. Accordingly, we categorize deepfake artifacts into two distinct yet complementary types: Face Inconsistency Artifacts (FIA) and Up-Sampling Artifacts (USA). FIA arise from the challenge of generating all intricate details, inevitably causing inconsistencies between the complex facial features and relatively uniform surrounding areas. USA, on the other hand, are the inevitable traces left by the generator's decoder during the up-sampling process. This categorization stems from the observation that all existing deepfakes typically exhibit one or both of these artifacts. To achieve this, we propose a new data-level pseudo-fake creation framework that constructs fake samples with only the FIA and USA, without introducing extra less-general artifacts. Specifically, we employ a super-resolution to simulate the USA, while design a Blender module that uses image-level self-blending on diverse facial regions to create the FIA. We surprisingly found that, with this intuitive design, a standard image classifier trained only with our pseudo-fake data can non-trivially generalize well to unseen deepfakes.
Spot the Fake: Large Multimodal Model-Based Synthetic Image Detection with Artifact Explanation
Mar 19, 2025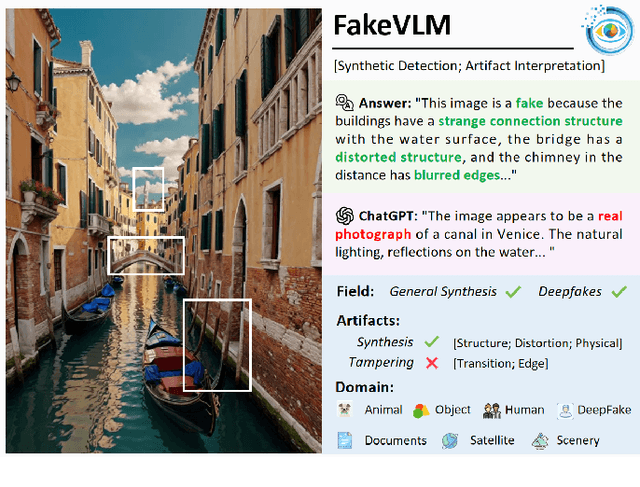
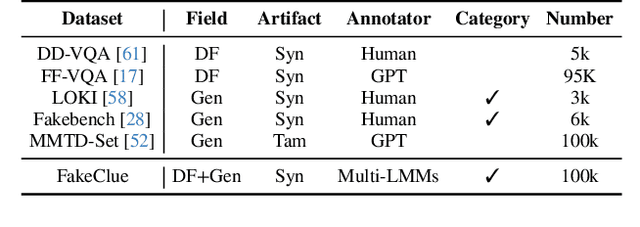

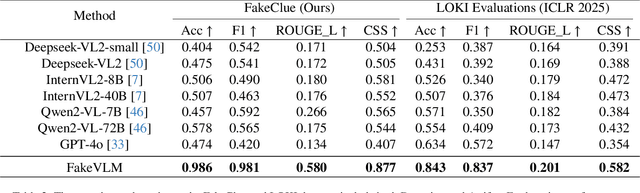
With the rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, synthetic images have become increasingly prevalent in everyday life, posing new challenges for authenticity assessment and detection. Despite the effectiveness of existing methods in evaluating image authenticity and locating forgeries, these approaches often lack human interpretability and do not fully address the growing complexity of synthetic data. To tackle these challenges, we introduce FakeVLM, a specialized large multimodal model designed for both general synthetic image and DeepFake detection tasks. FakeVLM not only excels in distinguishing real from fake images but also provides clear, natural language explanations for image artifacts, enhancing interpretability. Additionally, we present FakeClue, a comprehensive dataset containing over 100,000 images across seven categories, annotated with fine-grained artifact clues in natural language. FakeVLM demonstrates performance comparable to expert models while eliminating the need for additional classifiers, making it a robust solution for synthetic data detection. Extensive evaluations across multiple datasets confirm the superiority of FakeVLM in both authenticity classification and artifact explanation tasks, setting a new benchmark for synthetic image detection. The dataset and code will be released in: https://github.com/opendatalab/FakeVLM.
Short-Term Load Forecasting for AI-Data Center
Mar 10, 2025



Recent research shows large-scale AI-centric data centers could experience rapid fluctuations in power demand due to varying computation loads, such as sudden spikes from inference or interruption of training large language models (LLMs). As a consequence, such huge and fluctuating power demand pose significant challenges to both data center and power utility operation. Accurate short-term power forecasting allows data centers and utilities to dynamically allocate resources and power large computing clusters as required. However, due to the complex data center power usage patterns and the black-box nature of the underlying AI algorithms running in data centers, explicit modeling of AI-data center is quite challenging. Alternatively, to deal with this emerging load forecasting problem, we propose a data-driven workflow to model and predict the short-term electricity load in an AI-data center, and such workflow is compatible with learning-based algorithms such as LSTM, GRU, 1D-CNN. We validate our framework, which achieves decent accuracy on data center GPU short-term power consumption. This provides opportunity for improved power management and sustainable data center operations.