 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes
Apr 07, 2025Detecting deepfakes has been an increasingly important topic, especially given the rapid development of AI generation techniques. In this paper, we ask: How can we build a universal detection framework that is effective for most facial deepfakes? One significant challenge is the wide variety of deepfake generators available, resulting in varying forgery artifacts (e.g., lighting inconsistency, color mismatch, etc). But should we ``teach" the detector to learn all these artifacts separately? It is impossible and impractical to elaborate on them all. So the core idea is to pinpoint the more common and general artifacts across different deepfakes. Accordingly, we categorize deepfake artifacts into two distinct yet complementary types: Face Inconsistency Artifacts (FIA) and Up-Sampling Artifacts (USA). FIA arise from the challenge of generating all intricate details, inevitably causing inconsistencies between the complex facial features and relatively uniform surrounding areas. USA, on the other hand, are the inevitable traces left by the generator's decoder during the up-sampling process. This categorization stems from the observation that all existing deepfakes typically exhibit one or both of these artifacts. To achieve this, we propose a new data-level pseudo-fake creation framework that constructs fake samples with only the FIA and USA, without introducing extra less-general artifacts. Specifically, we employ a super-resolution to simulate the USA, while design a Blender module that uses image-level self-blending on diverse facial regions to create the FIA. We surprisingly found that, with this intuitive design, a standard image classifier trained only with our pseudo-fake data can non-trivially generalize well to unseen deepfakes.
A 106K Multi-Topic Multilingual Conversational User Dataset with Emoticons
Feb 26, 2025Instant messaging has become a predominant form of communication, with texts and emoticons enabling users to express emotions and ideas efficiently. Emoticons, in particular, have gained significant traction as a medium for conveying sentiments and information, leading to the growing importance of emoticon retrieval and recommendation systems. However, one of the key challenges in this area has been the absence of datasets that capture both the temporal dynamics and user-specific interactions with emoticons, limiting the progress of personalized user modeling and recommendation approaches. To address this, we introduce the emoticon dataset, a comprehensive resource that includes time-based data along with anonymous user identifiers across different conversations. As the largest publicly accessible emoticon dataset to date, it comprises 22K unique users, 370K emoticons, and 8.3M messages. The data was collected from a widely-used messaging platform across 67 conversations and 720 hours of crawling. Strict privacy and safety checks were applied to ensure the integrity of both text and image data. Spanning across 10 distinct domains, the emoticon dataset provides rich insights into temporal, multilingual, and cross-domain behaviors, which were previously unavailable in other emoticon-based datasets. Our in-depth experiments, both quantitative and qualitative, demonstrate the dataset's potential in modeling user behavior and personalized recommendation systems, opening up new possibilities for research in personalized retrieval and conversational AI. The dataset is freely accessible.
RDGCN: Reinforced Dependency Graph Convolutional Network for Aspect-based Sentiment Analysis
Nov 08, 2023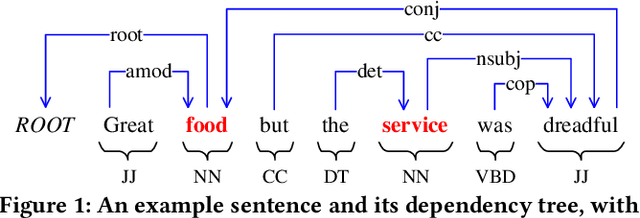
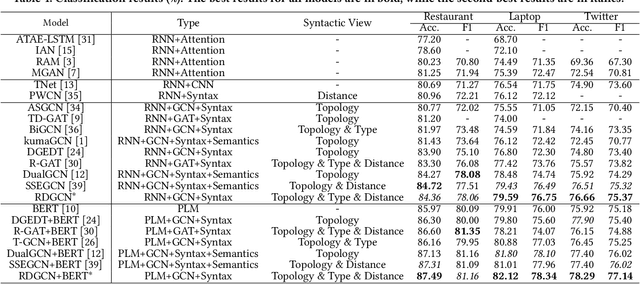
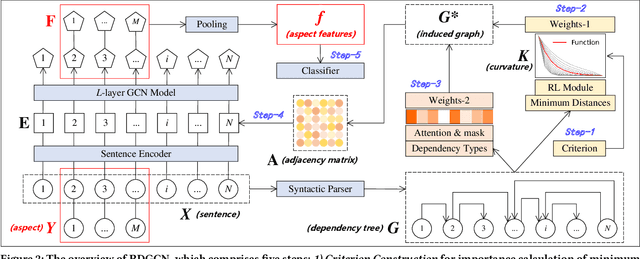
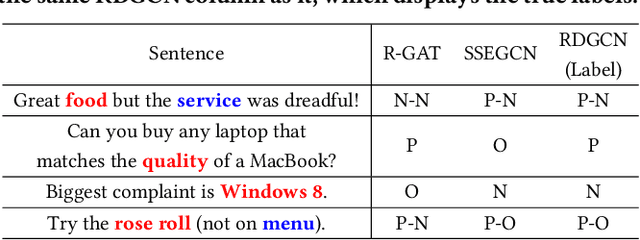
Aspect-based sentiment analysis (ABSA) is dedicated to forecasting the sentiment polarity of aspect terms within sentences. Employing graph neural networks to capture structural patterns from syntactic dependency parsing has been confirmed as an effective approach for boosting ABSA. In most works, the topology of dependency trees or dependency-based attention coefficients is often loosely regarded as edges between aspects and opinions, which can result in insufficient and ambiguous syntactic utilization. To address these problems, we propose a new reinforced dependency graph convolutional network (RDGCN) that improves the importance calculation of dependencies in both distance and type views. Initially, we propose an importance calculation criterion for the minimum distances over dependency trees. Under the criterion, we design a distance-importance function that leverages reinforcement learning for weight distribution search and dissimilarity control. Since dependency types often do not have explicit syntax like tree distances, we use global attention and mask mechanisms to design type-importance functions. Finally, we merge these weights and implement feature aggregation and classification. Comprehensive experiments on three popular datasets demonstrate the effectiveness of the criterion and importance functions. RDGCN outperforms state-of-the-art GNN-based baselines in all validations.
Causality and Independence Enhancement for Biased Node Classification
Oct 14, 2023



Most existing methods that address out-of-distribution (OOD) generalization for node classification on graphs primarily focus on a specific type of data biases, such as label selection bias or structural bias. However, anticipating the type of bias in advance is extremely challenging, and designing models solely for one specific type may not necessarily improve overall generalization performance. Moreover, limited research has focused on the impact of mixed biases, which are more prevalent and demanding in real-world scenarios. To address these limitations, we propose a novel Causality and Independence Enhancement (CIE) framework, applicable to various graph neural networks (GNNs). Our approach estimates causal and spurious features at the node representation level and mitigates the influence of spurious correlations through the backdoor adjustment. Meanwhile, independence constraint is introduced to improve the discriminability and stability of causal and spurious features in complex biased environments. Essentially, CIE eliminates different types of data biases from a unified perspective, without the need to design separate methods for each bias as before. To evaluate the performance under specific types of data biases, mixed biases, and low-resource scenarios, we conducted comprehensive experiments on five publicly available datasets. Experimental results demonstrate that our approach CIE not only significantly enhances the performance of GNNs but outperforms state-of-the-art debiased node classification methods.