 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Progression Masked Autoencoder with Fusion CNN Network for Classifying Evolution Between Two Pairs of 2D OCT Slices
Aug 27, 2025Age-related Macular Degeneration (AMD) is a prevalent eye condition affecting visual acuity. Anti-vascular endothelial growth factor (anti-VEGF) treatments have been effective in slowing the progression of neovascular AMD, with better outcomes achieved through timely diagnosis and consistent monitoring. Tracking the progression of neovascular activity in OCT scans of patients with exudative AMD allows for the development of more personalized and effective treatment plans. This was the focus of the Monitoring Age-related Macular Degeneration Progression in Optical Coherence Tomography (MARIO) challenge, in which we participated. In Task 1, which involved classifying the evolution between two pairs of 2D slices from consecutive OCT acquisitions, we employed a fusion CNN network with model ensembling to further enhance the model's performance. For Task 2, which focused on predicting progression over the next three months based on current exam data, we proposed the Patch Progression Masked Autoencoder that generates an OCT for the next exam and then classifies the evolution between the current OCT and the one generated using our solution from Task 1. The results we achieved allowed us to place in the Top 10 for both tasks. Some team members are part of the same organization as the challenge organizers; therefore, we are not eligible to compete for the prize.
* 10 pages, 5 figures, 3 tables, challenge/conference paper
Continuous Filtered Backprojection by Learnable Interpolation Network
May 03, 2025Accurate reconstruction of computed tomography (CT) images is crucial in medical imaging field. However, there are unavoidable interpolation errors in the backprojection step of the conventional reconstruction methods, i.e., filtered-back-projection based methods, which are detrimental to the accurate reconstruction. In this study, to address this issue, we propose a novel deep learning model, named Leanable-Interpolation-based FBP or LInFBP shortly, to enhance the reconstructed CT image quality, which achieves learnable interpolation in the backprojection step of filtered backprojection (FBP) and alleviates the interpolation errors. Specifically, in the proposed LInFBP, we formulate every local piece of the latent continuous function of discrete sinogram data as a linear combination of selected basis functions, and learn this continuous function by exploiting a deep network to predict the linear combination coefficients. Then, the learned latent continuous function is exploited for interpolation in backprojection step, which first time takes the advantage of deep learning for the interpolation in FBP. Extensive experiments, which encompass diverse CT scenarios, demonstrate the effectiveness of the proposed LInFBP in terms of enhanced reconstructed image quality, plug-and-play ability and generalization capability.
RS-RAG: Bridging Remote Sensing Imagery and Comprehensive Knowledge with a Multi-Modal Dataset and Retrieval-Augmented Generation Model
Apr 07, 2025



Recent progress in VLMs has demonstrated impressive capabilities across a variety of tasks in the natural image domain. Motivated by these advancements, the remote sensing community has begun to adopt VLMs for remote sensing vision-language tasks, including scene understanding, image captioning, and visual question answering. However, existing remote sensing VLMs typically rely on closed-set scene understanding and focus on generic scene descriptions, yet lack the ability to incorporate external knowledge. This limitation hinders their capacity for semantic reasoning over complex or context-dependent queries that involve domain-specific or world knowledge. To address these challenges, we first introduced a multimodal Remote Sensing World Knowledge (RSWK) dataset, which comprises high-resolution satellite imagery and detailed textual descriptions for 14,141 well-known landmarks from 175 countries, integrating both remote sensing domain knowledge and broader world knowledge. Building upon this dataset, we proposed a novel Remote Sensing Retrieval-Augmented Generation (RS-RAG) framework, which consists of two key components. The Multi-Modal Knowledge Vector Database Construction module encodes remote sensing imagery and associated textual knowledge into a unified vector space. The Knowledge Retrieval and Response Generation module retrieves and re-ranks relevant knowledge based on image and/or text queries, and incorporates the retrieved content into a knowledge-augmented prompt to guide the VLM in producing contextually grounded responses. We validated the effectiveness of our approach on three representative vision-language tasks, including image captioning, image classification, and visual question answering, where RS-RAG significantly outperformed state-of-the-art baselines.
From Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes
Apr 07, 2025Detecting deepfakes has been an increasingly important topic, especially given the rapid development of AI generation techniques. In this paper, we ask: How can we build a universal detection framework that is effective for most facial deepfakes? One significant challenge is the wide variety of deepfake generators available, resulting in varying forgery artifacts (e.g., lighting inconsistency, color mismatch, etc). But should we ``teach" the detector to learn all these artifacts separately? It is impossible and impractical to elaborate on them all. So the core idea is to pinpoint the more common and general artifacts across different deepfakes. Accordingly, we categorize deepfake artifacts into two distinct yet complementary types: Face Inconsistency Artifacts (FIA) and Up-Sampling Artifacts (USA). FIA arise from the challenge of generating all intricate details, inevitably causing inconsistencies between the complex facial features and relatively uniform surrounding areas. USA, on the other hand, are the inevitable traces left by the generator's decoder during the up-sampling process. This categorization stems from the observation that all existing deepfakes typically exhibit one or both of these artifacts. To achieve this, we propose a new data-level pseudo-fake creation framework that constructs fake samples with only the FIA and USA, without introducing extra less-general artifacts. Specifically, we employ a super-resolution to simulate the USA, while design a Blender module that uses image-level self-blending on diverse facial regions to create the FIA. We surprisingly found that, with this intuitive design, a standard image classifier trained only with our pseudo-fake data can non-trivially generalize well to unseen deepfakes.
Accelerated Patient-specific Non-Cartesian MRI Reconstruction using Implicit Neural Representations
Mar 07, 2025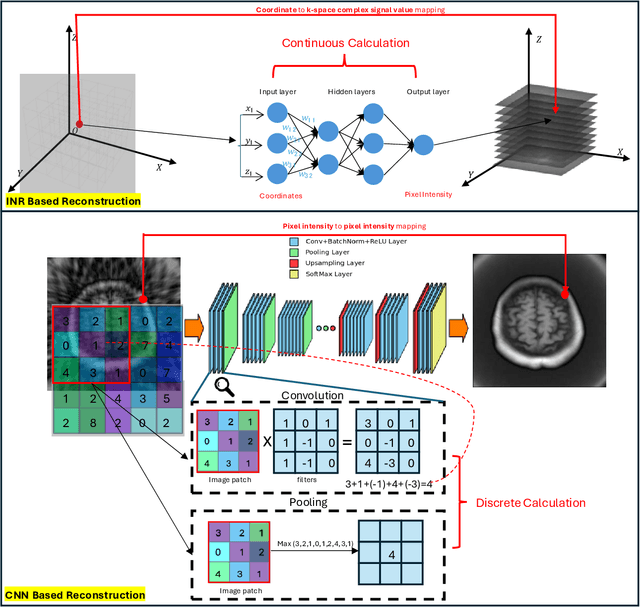
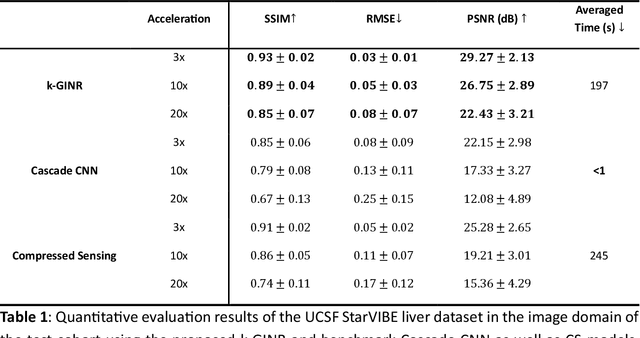
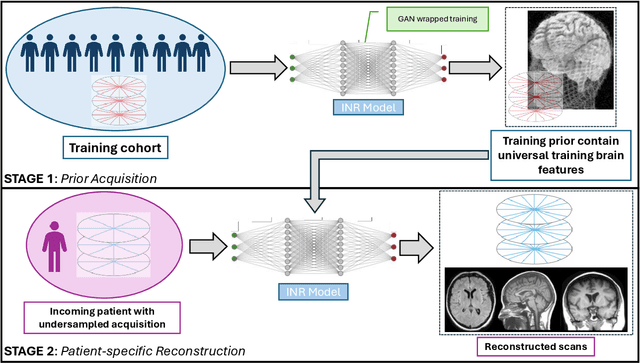
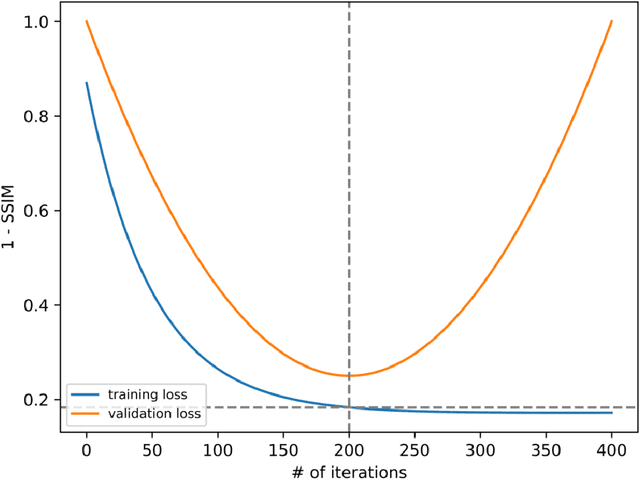
The scanning time for a fully sampled MRI can be undesirably lengthy. Compressed sensing has been developed to minimize image artifacts in accelerated scans, but the required iterative reconstruction is computationally complex and difficult to generalize on new cases. Image-domain-based deep learning methods (e.g., convolutional neural networks) emerged as a faster alternative but face challenges in modeling continuous k-space, a problem amplified with non-Cartesian sampling commonly used in accelerated acquisition. In comparison, implicit neural representations can model continuous signals in the frequency domain and thus are compatible with arbitrary k-space sampling patterns. The current study develops a novel generative-adversarially trained implicit neural representations (k-GINR) for de novo undersampled non-Cartesian k-space reconstruction. k-GINR consists of two stages: 1) supervised training on an existing patient cohort; 2) self-supervised patient-specific optimization. In stage 1, the network is trained with the generative-adversarial network on diverse patients of the same anatomical region supervised by fully sampled acquisition. In stage 2, undersampled k-space data of individual patients is used to tailor the prior-embedded network for patient-specific optimization. The UCSF StarVIBE T1-weighted liver dataset was evaluated on the proposed framework. k-GINR is compared with an image-domain deep learning method, Deep Cascade CNN, and a compressed sensing method. k-GINR consistently outperformed the baselines with a larger performance advantage observed at very high accelerations (e.g., 20 times). k-GINR offers great value for direct non-Cartesian k-space reconstruction for new incoming patients across a wide range of accelerations liver anatomy.
Multi-View Attention Syntactic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis
Jan 27, 2025



Aspect-based Sentiment Analysis (ABSA) is the task aimed at predicting the sentiment polarity of aspect words within sentences. Recently, incorporating graph neural networks (GNNs) to capture additional syntactic structure information in the dependency tree derived from syntactic dependency parsing has been proven to be an effective paradigm for boosting ABSA. Despite GNNs enhancing model capability by fusing more types of information, most works only utilize a single topology view of the dependency tree or simply conflate different perspectives of information without distinction, which limits the model performance. To address these challenges, in this paper, we propose a new multi-view attention syntactic enhanced graph convolutional network (MASGCN) that weighs different syntactic information of views using attention mechanisms. Specifically, we first construct distance mask matrices from the dependency tree to obtain multiple subgraph views for GNNs. To aggregate features from different views, we propose a multi-view attention mechanism to calculate the attention weights of views. Furthermore, to incorporate more syntactic information, we fuse the dependency type information matrix into the adjacency matrices and present a structural entropy loss to learn the dependency type adjacency matrix. Comprehensive experiments on four benchmark datasets demonstrate that our model outperforms state-of-the-art methods. The codes and datasets are available at https://github.com/SELGroup/MASGCN.
FedRSClip: Federated Learning for Remote Sensing Scene Classification Using Vision-Language Models
Jan 05, 2025



Remote sensing data is often distributed across multiple institutions, and due to privacy concerns and data-sharing restrictions, leveraging large-scale datasets in a centralized training framework is challenging. Federated learning offers a promising solution by enabling collaborative model training across distributed data sources without requiring data centralization. However, current Vision-Language Models (VLMs), which typically contain billions of parameters, pose significant communication challenges for traditional federated learning approaches based on model parameter updates, as they would incur substantial communication costs. In this paper, we propose FedRSCLIP, the first federated learning framework designed for remote sensing image classification based on a VLM, specifically CLIP. FedRSCLIP addresses the challenges of data heterogeneity and large-scale model transmission in federated environments by introducing Prompt Learning, which optimizes only a small set of tunable parameters. The framework introduces a dual-prompt mechanism, comprising Shared Prompts for global knowledge sharing and Private Prompts for client-specific adaptation. To maintain semantic coherence between shared and private prompts, we propose the Dual Prompt Alignment Constraint to balance global consistency and local adaptability across diverse client distributions. Additionally, to enhance cross-modal representation learning, we introduce the Cross-Modal Feature Alignment Constraint to align multimodal features between text and image prompts. To validate the effectiveness of our proposed model, we construct a Fed-RSIC dataset based on three existing remote sensing image classification datasets, specifically designed to simulate various federated learning configurations. Experimental results demonstrate the effectiveness and superiority of FedRSCLIP in remote sensing image classification.
Generalization-Enhanced Few-Shot Object Detection in Remote Sensing
Jan 05, 2025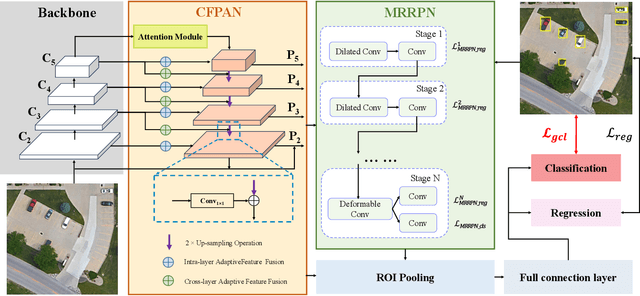
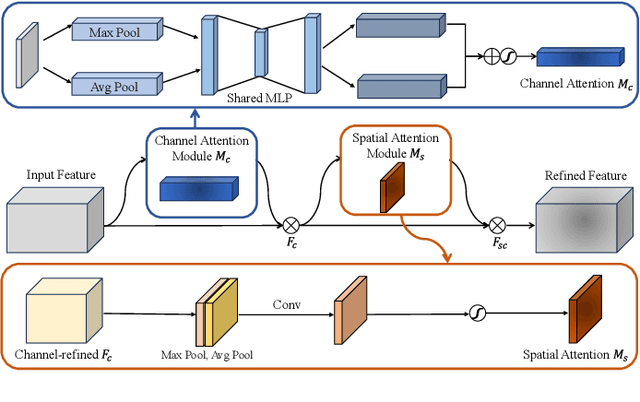
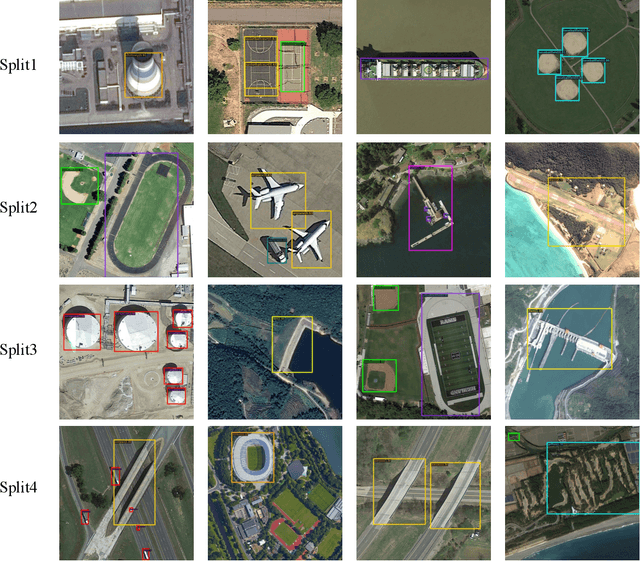

Remote sensing object detection is particularly challenging due to the high resolution, multi-scale features, and diverse ground object characteristics inherent in satellite and UAV imagery. These challenges necessitate more advanced approaches for effective object detection in such environments. While deep learning methods have achieved remarkable success in remote sensing object detection, they typically rely on large amounts of labeled data. Acquiring sufficient labeled data, particularly for novel or rare objects, is both challenging and time-consuming in remote sensing scenarios, limiting the generalization capabilities of existing models. To address these challenges, few-shot learning (FSL) has emerged as a promising approach, aiming to enable models to learn new classes from limited labeled examples. Building on this concept, few-shot object detection (FSOD) specifically targets object detection challenges in data-limited conditions. However, the generalization capability of FSOD models, particularly in remote sensing, is often constrained by the complex and diverse characteristics of the objects present in such environments. In this paper, we propose the Generalization-Enhanced Few-Shot Object Detection (GE-FSOD) model to improve the generalization capability in remote sensing FSOD tasks. Our model introduces three key innovations: the Cross-Level Fusion Pyramid Attention Network (CFPAN) for enhanced multi-scale feature representation, the Multi-Stage Refinement Region Proposal Network (MRRPN) for more accurate region proposals, and the Generalized Classification Loss (GCL) for improved classification performance in few-shot scenarios. Extensive experiments on the DIOR and NWPU VHR-10 datasets show that our model achieves state-of-the-art performance for few-shot object detection in remote sensing.
Rapid Reconstruction of Extremely Accelerated Liver 4D MRI via Chained Iterative Refinement
Dec 14, 2024



Abstract Purpose: High-quality 4D MRI requires an impractically long scanning time for dense k-space signal acquisition covering all respiratory phases. Accelerated sparse sampling followed by reconstruction enhancement is desired but often results in degraded image quality and long reconstruction time. We hereby propose the chained iterative reconstruction network (CIRNet) for efficient sparse-sampling reconstruction while maintaining clinically deployable quality. Methods: CIRNet adopts the denoising diffusion probabilistic framework to condition the image reconstruction through a stochastic iterative denoising process. During training, a forward Markovian diffusion process is designed to gradually add Gaussian noise to the densely sampled ground truth (GT), while CIRNet is optimized to iteratively reverse the Markovian process from the forward outputs. At the inference stage, CIRNet performs the reverse process solely to recover signals from noise, conditioned upon the undersampled input. CIRNet processed the 4D data (3D+t) as temporal slices (2D+t). The proposed framework is evaluated on a data cohort consisting of 48 patients (12332 temporal slices) who underwent free-breathing liver 4D MRI. 3-, 6-, 10-, 20- and 30-times acceleration were examined with a retrospective random undersampling scheme. Compressed sensing (CS) reconstruction with a spatiotemporal constraint and a recently proposed deep network, Re-Con-GAN, are selected as baselines. Results: CIRNet consistently achieved superior performance compared to CS and Re-Con-GAN. The inference time of CIRNet, CS, and Re-Con-GAN are 11s, 120s, and 0.15s. Conclusion: A novel framework, CIRNet, is presented. CIRNet maintains useable image quality for acceleration up to 30 times, significantly reducing the burden of 4DMRI.
Structural Entropy Guided Probabilistic Coding
Dec 12, 2024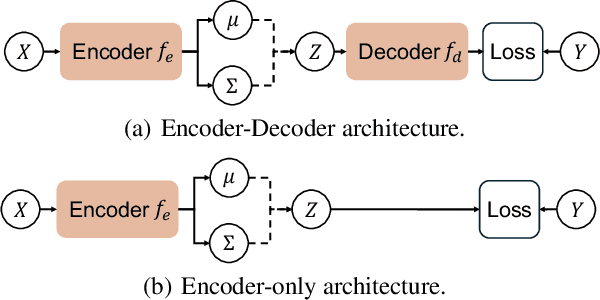



Probabilistic embeddings have several advantages over deterministic embeddings as they map each data point to a distribution, which better describes the uncertainty and complexity of data. Many works focus on adjusting the distribution constraint under the Information Bottleneck (IB) principle to enhance representation learning. However, these proposed regularization terms only consider the constraint of each latent variable, omitting the structural information between latent variables. In this paper, we propose a novel structural entropy-guided probabilistic coding model, named SEPC. Specifically, we incorporate the relationship between latent variables into the optimization by proposing a structural entropy regularization loss. Besides, as traditional structural information theory is not well-suited for regression tasks, we propose a probabilistic encoding tree, transferring regression tasks to classification tasks while diminishing the influence of the transformation. Experimental results across 12 natural language understanding tasks, including both classification and regression tasks, demonstrate the superior performance of SEPC compared to other state-of-the-art models in terms of effectiveness, generalization capability, and robustness to label noise. The codes and datasets are available at https://github.com/SELGroup/SEPC.