 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Scoring with 3D Gaussian Splatting for Instance Image-Goal Navigation
Jun 09, 2025Instance Image-Goal Navigation (IIN) requires autonomous agents to identify and navigate to a target object or location depicted in a reference image captured from any viewpoint. While recent methods leverage powerful novel view synthesis (NVS) techniques, such as three-dimensional Gaussian splatting (3DGS), they typically rely on randomly sampling multiple viewpoints or trajectories to ensure comprehensive coverage of discriminative visual cues. This approach, however, creates significant redundancy through overlapping image samples and lacks principled view selection, substantially increasing both rendering and comparison overhead. In this paper, we introduce a novel IIN framework with a hierarchical scoring paradigm that estimates optimal viewpoints for target matching. Our approach integrates cross-level semantic scoring, utilizing CLIP-derived relevancy fields to identify regions with high semantic similarity to the target object class, with fine-grained local geometric scoring that performs precise pose estimation within promising regions. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on simulated IIN benchmarks and real-world applicability.
MapBERT: Bitwise Masked Modeling for Real-Time Semantic Mapping Generation
Jun 09, 2025Spatial awareness is a critical capability for embodied agents, as it enables them to anticipate and reason about unobserved regions. The primary challenge arises from learning the distribution of indoor semantics, complicated by sparse, imbalanced object categories and diverse spatial scales. Existing methods struggle to robustly generate unobserved areas in real time and do not generalize well to new environments. To this end, we propose \textbf{MapBERT}, a novel framework designed to effectively model the distribution of unseen spaces. Motivated by the observation that the one-hot encoding of semantic maps aligns naturally with the binary structure of bit encoding, we, for the first time, leverage a lookup-free BitVAE to encode semantic maps into compact bitwise tokens. Building on this, a masked transformer is employed to infer missing regions and generate complete semantic maps from limited observations. To enhance object-centric reasoning, we propose an object-aware masking strategy that masks entire object categories concurrently and pairs them with learnable embeddings, capturing implicit relationships between object embeddings and spatial tokens. By learning these relationships, the model more effectively captures indoor semantic distributions crucial for practical robotic tasks. Experiments on Gibson benchmarks show that MapBERT achieves state-of-the-art semantic map generation, balancing computational efficiency with accurate reconstruction of unobserved regions.
H2-COMPACT: Human-Humanoid Co-Manipulation via Adaptive Contact Trajectory Policies
May 23, 2025We present a hierarchical policy-learning framework that enables a legged humanoid to cooperatively carry extended loads with a human partner using only haptic cues for intent inference. At the upper tier, a lightweight behavior-cloning network consumes six-axis force/torque streams from dual wrist-mounted sensors and outputs whole-body planar velocity commands that capture the leader's applied forces. At the lower tier, a deep-reinforcement-learning policy, trained under randomized payloads (0-3 kg) and friction conditions in Isaac Gym and validated in MuJoCo and on a real Unitree G1, maps these high-level twists to stable, under-load joint trajectories. By decoupling intent interpretation (force -> velocity) from legged locomotion (velocity -> joints), our method combines intuitive responsiveness to human inputs with robust, load-adaptive walking. We collect training data without motion-capture or markers, only synchronized RGB video and F/T readings, employing SAM2 and WHAM to extract 3D human pose and velocity. In real-world trials, our humanoid achieves cooperative carry-and-move performance (completion time, trajectory deviation, velocity synchrony, and follower-force) on par with a blindfolded human-follower baseline. This work is the first to demonstrate learned haptic guidance fused with full-body legged control for fluid human-humanoid co-manipulation. Code and videos are available on the H2-COMPACT website.
Embodied Chain of Action Reasoning with Multi-Modal Foundation Model for Humanoid Loco-manipulation
Apr 13, 2025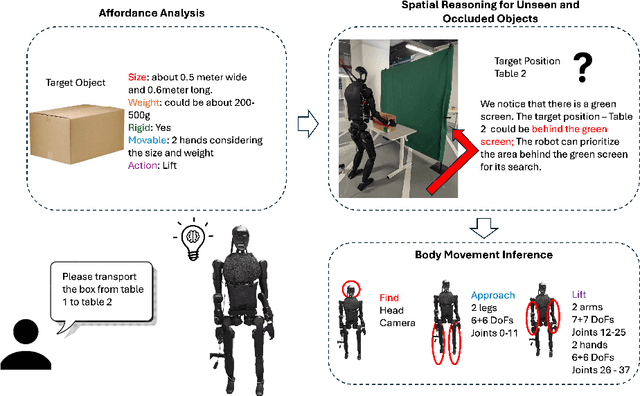
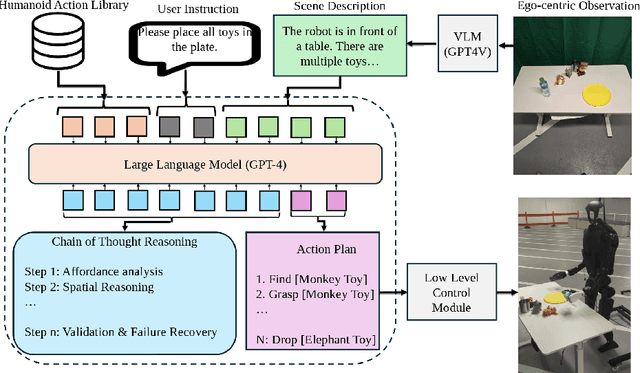
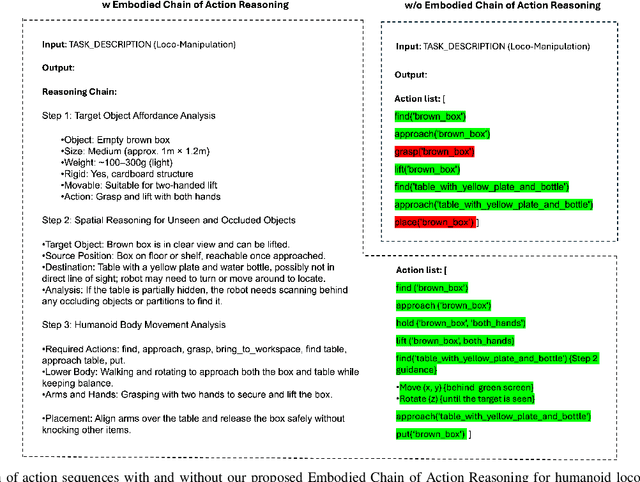

Enabling humanoid robots to autonomously perform loco-manipulation tasks in complex, unstructured environments poses significant challenges. This entails equipping robots with the capability to plan actions over extended horizons while leveraging multi-modality to bridge gaps between high-level planning and actual task execution. Recent advancements in multi-modal foundation models have showcased substantial potential in enhancing planning and reasoning abilities, particularly in the comprehension and processing of semantic information for robotic control tasks. In this paper, we introduce a novel framework based on foundation models that applies the embodied chain of action reasoning methodology to autonomously plan actions from textual instructions for humanoid loco-manipulation. Our method integrates humanoid-specific chain of thought methodology, including detailed affordance and body movement analysis, which provides a breakdown of the task into a sequence of locomotion and manipulation actions. Moreover, we incorporate spatial reasoning based on the observation and target object properties to effectively navigate where target position may be unseen or occluded. Through rigorous experimental setups on object rearrangement, manipulations and loco-manipulation tasks on a real-world environment, we evaluate our method's efficacy on the decoupled upper and lower body control and demonstrate the effectiveness of the chain of robotic action reasoning strategies in comprehending human instructions.
A Chain-of-Thought Subspace Meta-Learning for Few-shot Image Captioning with Large Vision and Language Models
Feb 19, 2025A large-scale vision and language model that has been pretrained on massive data encodes visual and linguistic prior, which makes it easier to generate images and language that are more natural and realistic. Despite this, there is still a significant domain gap between the modalities of vision and language, especially when training data is scarce in few-shot settings, where only very limited data are available for training. In order to mitigate this issue, a multi-modal meta-learning framework has been proposed to bridge the gap between two frozen pretrained large vision and language models by introducing a tunable prompt connecting these two large models. For few-shot image captioning, the existing multi-model meta-learning framework utilizes a one-step prompting scheme to accumulate the visual features of input images to guide the language model, which struggles to generate accurate image descriptions with only a few training samples. Instead, we propose a chain-of-thought (CoT) meta-learning scheme as a multi-step image captioning procedure to better imitate how humans describe images. In addition, we further propose to learn different meta-parameters of the model corresponding to each CoT step in distinct subspaces to avoid interference. We evaluated our method on three commonly used image captioning datasets, i.e., MSCOCO, Flickr8k, and Flickr30k, under few-shot settings. The results of our experiments indicate that our chain-of-thought subspace meta-learning strategy is superior to the baselines in terms of performance across different datasets measured by different metrics.
GAMap: Zero-Shot Object Goal Navigation with Multi-Scale Geometric-Affordance Guidance
Oct 31, 2024



Zero-Shot Object Goal Navigation (ZS-OGN) enables robots or agents to navigate toward objects of unseen categories without object-specific training. Traditional approaches often leverage categorical semantic information for navigation guidance, which struggles when only objects are partially observed or detailed and functional representations of the environment are lacking. To resolve the above two issues, we propose \textit{Geometric-part and Affordance Maps} (GAMap), a novel method that integrates object parts and affordance attributes as navigation guidance. Our method includes a multi-scale scoring approach to capture geometric-part and affordance attributes of objects at different scales. Comprehensive experiments conducted on HM3D and Gibson benchmark datasets demonstrate improvements in Success Rate and Success weighted by Path Length, underscoring the efficacy of our geometric-part and affordance-guided navigation approach in enhancing robot autonomy and versatility, without any additional object-specific training or fine-tuning with the semantics of unseen objects and/or the locomotions of the robot.
Reliable Semantic Understanding for Real World Zero-shot Object Goal Navigation
Oct 29, 2024



We introduce an innovative approach to advancing semantic understanding in zero-shot object goal navigation (ZS-OGN), enhancing the autonomy of robots in unfamiliar environments. Traditional reliance on labeled data has been a limitation for robotic adaptability, which we address by employing a dual-component framework that integrates a GLIP Vision Language Model for initial detection and an InstructionBLIP model for validation. This combination not only refines object and environmental recognition but also fortifies the semantic interpretation, pivotal for navigational decision-making. Our method, rigorously tested in both simulated and real-world settings, exhibits marked improvements in navigation precision and reliability.
Exploring the Reliability of Foundation Model-Based Frontier Selection in Zero-Shot Object Goal Navigation
Oct 28, 2024In this paper, we present a novel method for reliable frontier selection in Zero-Shot Object Goal Navigation (ZS-OGN), enhancing robotic navigation systems with foundation models to improve commonsense reasoning in indoor environments. Our approach introduces a multi-expert decision framework to address the nonsensical or irrelevant reasoning often seen in foundation model-based systems. The method comprises two key components: Diversified Expert Frontier Analysis (DEFA) and Consensus Decision Making (CDM). DEFA utilizes three expert models: furniture arrangement, room type analysis, and visual scene reasoning, while CDM aggregates their outputs, prioritizing unanimous or majority consensus for more reliable decisions. Demonstrating state-of-the-art performance on the RoboTHOR and HM3D datasets, our method excels at navigating towards untrained objects or goals and outperforms various baselines, showcasing its adaptability to dynamic real-world conditions and superior generalization capabilities.
Zero-shot Object Navigation with Vision-Language Models Reasoning
Oct 24, 2024



Object navigation is crucial for robots, but traditional methods require substantial training data and cannot be generalized to unknown environments. Zero-shot object navigation (ZSON) aims to address this challenge, allowing robots to interact with unknown objects without specific training data. Language-driven zero-shot object navigation (L-ZSON) is an extension of ZSON that incorporates natural language instructions to guide robot navigation and interaction with objects. In this paper, we propose a novel Vision Language model with a Tree-of-thought Network (VLTNet) for L-ZSON. VLTNet comprises four main modules: vision language model understanding, semantic mapping, tree-of-thought reasoning and exploration, and goal identification. Among these modules, Tree-of-Thought (ToT) reasoning and exploration module serves as a core component, innovatively using the ToT reasoning framework for navigation frontier selection during robot exploration. Compared to conventional frontier selection without reasoning, navigation using ToT reasoning involves multi-path reasoning processes and backtracking when necessary, enabling globally informed decision-making with higher accuracy. Experimental results on PASTURE and RoboTHOR benchmarks demonstrate the outstanding performance of our model in LZSON, particularly in scenarios involving complex natural language as target instructions.
MultiTalk: Introspective and Extrospective Dialogue for Human-Environment-LLM Alignment
Sep 24, 2024



LLMs have shown promising results in task planning due to their strong natural language understanding and reasoning capabilities. However, issues such as hallucinations, ambiguities in human instructions, environmental constraints, and limitations in the executing agent's capabilities often lead to flawed or incomplete plans. This paper proposes MultiTalk, an LLM-based task planning methodology that addresses these issues through a framework of introspective and extrospective dialogue loops. This approach helps ground generated plans in the context of the environment and the agent's capabilities, while also resolving uncertainties and ambiguities in the given task. These loops are enabled by specialized systems designed to extract and predict task-specific states, and flag mismatches or misalignments among the human user, the LLM agent, and the environment. Effective feedback pathways between these systems and the LLM planner foster meaningful dialogue. The efficacy of this methodology is demonstrated through its application to robotic manipulation tasks. Experiments and ablations highlight the robustness and reliability of our method, and comparisons with baselines further illustrate the superiority of MultiTalk in task planning for embodied agents.