 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Object-Centric World Models and Diffusion Policy: A Hierarchical Framework for Multi-Stage Robotic Tasks
Jun 07, 2026Visual world models have shown great potential in learning complex system dynamics. Recent advancements leverage these models as transition functions within Model Predictive Control (MPC) frameworks to solve various control tasks. When applied to robotics, however, they are limited to single-stage tasks such as reaching or grasping, and struggle with multi-stage ones that demand complex sequential planning. In this work, we introduce WorldDP, a world model framework designed for multi-stage robotic manipulation. Our hierarchical approach utilizes a high-level world model as a transition function to optimize for feasible subgoals during runtime, which are subsequently reached by a low-level Diffusion Policy. To further aid in learning dynamics and planning, we incorporate object-centric representations that decouple environmental entities and enable us to plan sequentially with respect to each. Evaluated across several robotics benchmarks, WorldDP consistently outperforms existing baselines, validating that coupling the world model's physically grounded planning with diffusion policy's efficient execution yields superior multi-stage performance.
Long-Term and Short-Term Transistor Aging in Deep Neural Networks: Impact and Mitigation
Jun 02, 2026Deep neural networks (DNNs) are used in a variety of real-world applications including, for example, image classification and speech recognition. The inference accuracy of DNN implemented on hardware in integrated circuits (ICs) degrades under phenomena such as transistor aging. Aging slows down the switching speed of transistors, resulting in system-level timing violations due to unsustainable clocks. To maintain reliability for the entire projected lifetime, designers add guardbands to prevent timing violations; however, adding large timing guardbands causes losses in performance (speed or throughput). This chapter provides a detailed discussion of the effects of long-term and short-term transistor aging on DNN inference accuracy. Furthermore, to mitigate aging effects on DNN's accuracy and keep them at bay, a methodology for aging-aware retraining is presented in order to generate a resilient DNN even when aggressive (i.e., smaller than required) guardbands are used. This improves the inference accuracy of the DNNs even in the presence of aging-induced degradation. These effects are discussed in this chapter along with mitigation strategies on a hardware implementation of a DNN for image classification on an off-the-shelf image dataset. The application of short-term aging as an excitation mechanism for the detection of hardware Trojans in integrated circuits is also briefly discussed.
RESCORE: LLM-Driven Simulation Recovery in Control Systems Research Papers
Apr 06, 2026Reconstructing numerical simulations from control systems research papers is often hindered by underspecified parameters and ambiguous implementation details. We define the task of Paper to Simulation Recoverability, the ability of an automated system to generate executable code that faithfully reproduces a paper's results. We curate a benchmark of 500 papers from the IEEE Conference on Decision and Control (CDC) and propose RESCORE, a three component LLM agentic framework, Analyzer, Coder, and Verifier. RESCORE uses iterative execution feedback and visual comparison to improve reconstruction fidelity. Our method successfully recovers task coherent simulations for 40.7% of benchmark instances, outperforming single pass generation. Notably, the RESCORE automated pipeline achieves an estimated 10X speedup over manual human replication, drastically cutting the time and effort required to verify published control methodologies. We will release our benchmark and agents to foster community progress in automated research replication.
CyberExplorer: Benchmarking LLM Offensive Security Capabilities in a Real-World Attacking Simulation Environment
Feb 08, 2026Real-world offensive security operations are inherently open-ended: attackers explore unknown attack surfaces, revise hypotheses under uncertainty, and operate without guaranteed success. Existing LLM-based offensive agent evaluations rely on closed-world settings with predefined goals and binary success criteria. To address this gap, we introduce CyberExplorer, an evaluation suite with two core components: (1) an open-environment benchmark built on a virtual machine hosting 40 vulnerable web services derived from real-world CTF challenges, where agents autonomously perform reconnaissance, target selection, and exploitation without prior knowledge of vulnerability locations; and (2) a reactive multi-agent framework supporting dynamic exploration without predefined plans. CyberExplorer enables fine-grained evaluation beyond flag recovery, capturing interaction dynamics, coordination behavior, failure modes, and vulnerability discovery signals-bridging the gap between benchmarks and realistic multi-target attack scenarios.
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
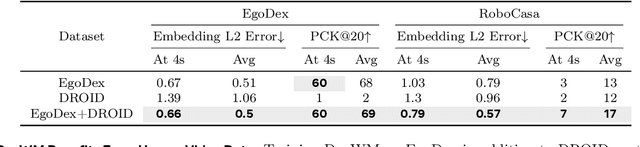
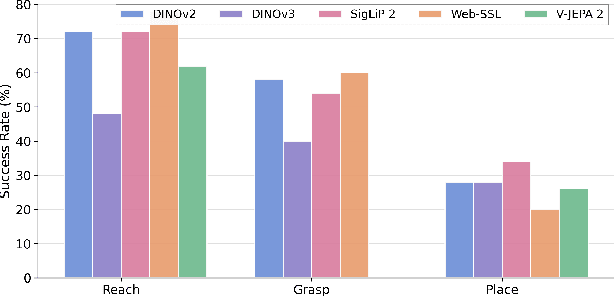
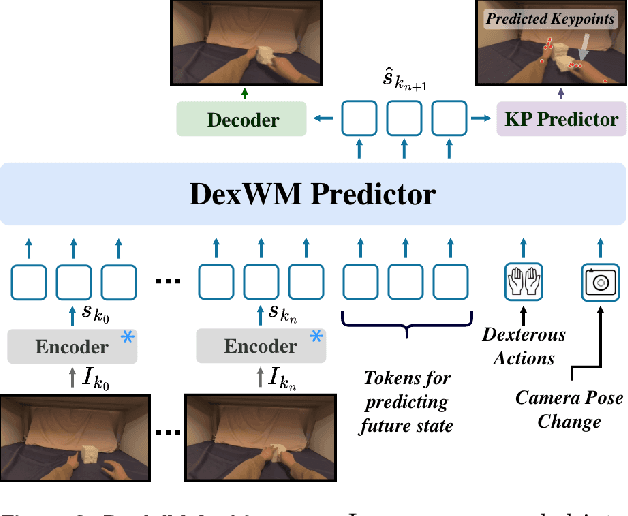
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
MapleGrasp: Mask-guided Feature Pooling for Language-driven Efficient Robotic Grasping
Jun 06, 2025Robotic manipulation of unseen objects via natural language commands remains challenging. Language driven robotic grasping (LDRG) predicts stable grasp poses from natural language queries and RGB-D images. Here we introduce Mask-guided feature pooling, a lightweight enhancement to existing LDRG methods. Our approach employs a two-stage training strategy: first, a vision-language model generates feature maps from CLIP-fused embeddings, which are upsampled and weighted by text embeddings to produce segmentation masks. Next, the decoder generates separate feature maps for grasp prediction, pooling only token features within these masked regions to efficiently predict grasp poses. This targeted pooling approach reduces computational complexity, accelerating both training and inference. Incorporating mask pooling results in a 12% improvement over prior approaches on the OCID-VLG benchmark. Furthermore, we introduce RefGraspNet, an open-source dataset eight times larger than existing alternatives, significantly enhancing model generalization for open-vocabulary grasping. By extending 2D grasp predictions to 3D via depth mapping and inverse kinematics, our modular method achieves performance comparable to recent Vision-Language-Action (VLA) models on the LIBERO simulation benchmark, with improved generalization across different task suites. Real-world experiments on a 7 DoF Franka robotic arm demonstrate a 57% success rate with unseen objects, surpassing competitive baselines by 7%. Code will be released post publication.
OSVI-WM: One-Shot Visual Imitation for Unseen Tasks using World-Model-Guided Trajectory Generation
May 26, 2025Visual imitation learning enables robotic agents to acquire skills by observing expert demonstration videos. In the one-shot setting, the agent generates a policy after observing a single expert demonstration without additional fine-tuning. Existing approaches typically train and evaluate on the same set of tasks, varying only object configurations, and struggle to generalize to unseen tasks with different semantic or structural requirements. While some recent methods attempt to address this, they exhibit low success rates on hard test tasks that, despite being visually similar to some training tasks, differ in context and require distinct responses. Additionally, most existing methods lack an explicit model of environment dynamics, limiting their ability to reason about future states. To address these limitations, we propose a novel framework for one-shot visual imitation learning via world-model-guided trajectory generation. Given an expert demonstration video and the agent's initial observation, our method leverages a learned world model to predict a sequence of latent states and actions. This latent trajectory is then decoded into physical waypoints that guide the agent's execution. Our method is evaluated on two simulated benchmarks and three real-world robotic platforms, where it consistently outperforms prior approaches, with over 30% improvement in some cases.
CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution
May 21, 2025



Large Language Model (LLM) agents can automate cybersecurity tasks and can adapt to the evolving cybersecurity landscape without re-engineering. While LLM agents have demonstrated cybersecurity capabilities on Capture-The-Flag (CTF) competitions, they have two key limitations: accessing latest cybersecurity expertise beyond training data, and integrating new knowledge into complex task planning. Knowledge-based approaches that incorporate technical understanding into the task-solving automation can tackle these limitations. We present CRAKEN, a knowledge-based LLM agent framework that improves cybersecurity capability through three core mechanisms: contextual decomposition of task-critical information, iterative self-reflected knowledge retrieval, and knowledge-hint injection that transforms insights into adaptive attack strategies. Comprehensive evaluations with different configurations show CRAKEN's effectiveness in multi-stage vulnerability detection and exploitation compared to previous approaches. Our extensible architecture establishes new methodologies for embedding new security knowledge into LLM-driven cybersecurity agentic systems. With a knowledge database of CTF writeups, CRAKEN obtained an accuracy of 22% on NYU CTF Bench, outperforming prior works by 3% and achieving state-of-the-art results. On evaluation of MITRE ATT&CK techniques, CRAKEN solves 25-30% more techniques than prior work, demonstrating improved cybersecurity capabilities via knowledge-based execution. We make our framework open source to public https://github.com/NYU-LLM-CTF/nyuctf_agents_craken.
RAZER: Robust Accelerated Zero-Shot 3D Open-Vocabulary Panoptic Reconstruction with Spatio-Temporal Aggregation
May 21, 2025Mapping and understanding complex 3D environments is fundamental to how autonomous systems perceive and interact with the physical world, requiring both precise geometric reconstruction and rich semantic comprehension. While existing 3D semantic mapping systems excel at reconstructing and identifying predefined object instances, they lack the flexibility to efficiently build semantic maps with open-vocabulary during online operation. Although recent vision-language models have enabled open-vocabulary object recognition in 2D images, they haven't yet bridged the gap to 3D spatial understanding. The critical challenge lies in developing a training-free unified system that can simultaneously construct accurate 3D maps while maintaining semantic consistency and supporting natural language interactions in real time. In this paper, we develop a zero-shot framework that seamlessly integrates GPU-accelerated geometric reconstruction with open-vocabulary vision-language models through online instance-level semantic embedding fusion, guided by hierarchical object association with spatial indexing. Our training-free system achieves superior performance through incremental processing and unified geometric-semantic updates, while robustly handling 2D segmentation inconsistencies. The proposed general-purpose 3D scene understanding framework can be used for various tasks including zero-shot 3D instance retrieval, segmentation, and object detection to reason about previously unseen objects and interpret natural language queries. The project page is available at https://razer-3d.github.io.
3D CAVLA: Leveraging Depth and 3D Context to Generalize Vision Language Action Models for Unseen Tasks
May 09, 2025Robotic manipulation in 3D requires learning an $N$ degree-of-freedom joint space trajectory of a robot manipulator. Robots must possess semantic and visual perception abilities to transform real-world mappings of their workspace into the low-level control necessary for object manipulation. Recent work has demonstrated the capabilities of fine-tuning large Vision-Language Models (VLMs) to learn the mapping between RGB images, language instructions, and joint space control. These models typically take as input RGB images of the workspace and language instructions, and are trained on large datasets of teleoperated robot demonstrations. In this work, we explore methods to improve the scene context awareness of a popular recent Vision-Language-Action model by integrating chain-of-thought reasoning, depth perception, and task-oriented region of interest detection. Our experiments in the LIBERO simulation environment show that our proposed model, 3D-CAVLA, improves the success rate across various LIBERO task suites, achieving an average success rate of 98.1$\%$. We also evaluate the zero-shot capabilities of our method, demonstrating that 3D scene awareness leads to robust learning and adaptation for completely unseen tasks. 3D-CAVLA achieves an absolute improvement of 8.8$\%$ on unseen tasks. We will open-source our code and the unseen tasks dataset to promote community-driven research here: https://3d-cavla.github.io