 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution
May 21, 2025



Large Language Model (LLM) agents can automate cybersecurity tasks and can adapt to the evolving cybersecurity landscape without re-engineering. While LLM agents have demonstrated cybersecurity capabilities on Capture-The-Flag (CTF) competitions, they have two key limitations: accessing latest cybersecurity expertise beyond training data, and integrating new knowledge into complex task planning. Knowledge-based approaches that incorporate technical understanding into the task-solving automation can tackle these limitations. We present CRAKEN, a knowledge-based LLM agent framework that improves cybersecurity capability through three core mechanisms: contextual decomposition of task-critical information, iterative self-reflected knowledge retrieval, and knowledge-hint injection that transforms insights into adaptive attack strategies. Comprehensive evaluations with different configurations show CRAKEN's effectiveness in multi-stage vulnerability detection and exploitation compared to previous approaches. Our extensible architecture establishes new methodologies for embedding new security knowledge into LLM-driven cybersecurity agentic systems. With a knowledge database of CTF writeups, CRAKEN obtained an accuracy of 22% on NYU CTF Bench, outperforming prior works by 3% and achieving state-of-the-art results. On evaluation of MITRE ATT&CK techniques, CRAKEN solves 25-30% more techniques than prior work, demonstrating improved cybersecurity capabilities via knowledge-based execution. We make our framework open source to public https://github.com/NYU-LLM-CTF/nyuctf_agents_craken.
EnIGMA: Enhanced Interactive Generative Model Agent for CTF Challenges
Sep 24, 2024



Although language model (LM) agents are demonstrating growing potential in many domains, their success in cybersecurity has been limited due to simplistic design and the lack of fundamental features for this domain. We present EnIGMA, an LM agent for autonomously solving Capture The Flag (CTF) challenges. EnIGMA introduces new Agent-Computer Interfaces (ACIs) to improve the success rate on CTF challenges. We establish the novel Interactive Agent Tool concept, which enables LM agents to run interactive command-line utilities essential for these challenges. Empirical analysis of EnIGMA on over 350 CTF challenges from three different benchmarks indicates that providing a robust set of new tools with demonstration of their usage helps the LM solve complex problems and achieves state-of-the-art results on the NYU CTF and Intercode-CTF benchmarks. Finally, we discuss insights on ACI design and agent behavior on cybersecurity tasks that highlight the need to adapt real-world tools for LM agents.
ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software
Aug 04, 2024



High-quality datasets of real-world vulnerabilities are enormously valuable for downstream research in software security, but existing datasets are typically small, require extensive manual effort to update, and are missing crucial features that such research needs. In this paper, we introduce ARVO: an Atlas of Reproducible Vulnerabilities in Open-source software. By sourcing vulnerabilities from C/C++ projects that Google's OSS-Fuzz discovered and implementing a reliable re-compilation system, we successfully reproduce more than 5,000 memory vulnerabilities across over 250 projects, each with a triggering input, the canonical developer-written patch for fixing the vulnerability, and the ability to automatically rebuild the project from source and run it at its vulnerable and patched revisions. Moreover, our dataset can be automatically updated as OSS-Fuzz finds new vulnerabilities, allowing it to grow over time. We provide a thorough characterization of the ARVO dataset, show that it can locate fixes more accurately than Google's own OSV reproduction effort, and demonstrate its value for future research through two case studies: firstly evaluating real-world LLM-based vulnerability repair, and secondly identifying over 300 falsely patched (still-active) zero-day vulnerabilities from projects improperly labeled by OSS-Fuzz.
NYU CTF Dataset: A Scalable Open-Source Benchmark Dataset for Evaluating LLMs in Offensive Security
Jun 08, 2024



Large Language Models (LLMs) are being deployed across various domains today. However, their capacity to solve Capture the Flag (CTF) challenges in cybersecurity has not been thoroughly evaluated. To address this, we develop a novel method to assess LLMs in solving CTF challenges by creating a scalable, open-source benchmark database specifically designed for these applications. This database includes metadata for LLM testing and adaptive learning, compiling a diverse range of CTF challenges from popular competitions. Utilizing the advanced function calling capabilities of LLMs, we build a fully automated system with an enhanced workflow and support for external tool calls. Our benchmark dataset and automated framework allow us to evaluate the performance of five LLMs, encompassing both black-box and open-source models. This work lays the foundation for future research into improving the efficiency of LLMs in interactive cybersecurity tasks and automated task planning. By providing a specialized dataset, our project offers an ideal platform for developing, testing, and refining LLM-based approaches to vulnerability detection and resolution. Evaluating LLMs on these challenges and comparing with human performance yields insights into their potential for AI-driven cybersecurity solutions to perform real-world threat management. We make our dataset open source to public https://github.com/NYU-LLM-CTF/LLM_CTF_Database along with our playground automated framework https://github.com/NYU-LLM-CTF/llm_ctf_automation.
Increasing a microscope's effective field of view via overlapped imaging and machine learning
Oct 10, 2021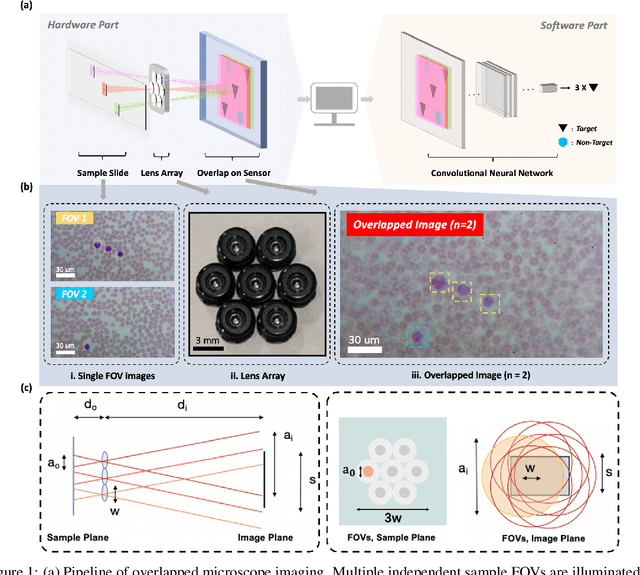
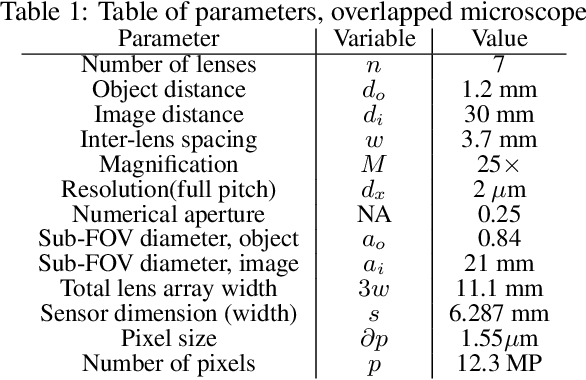
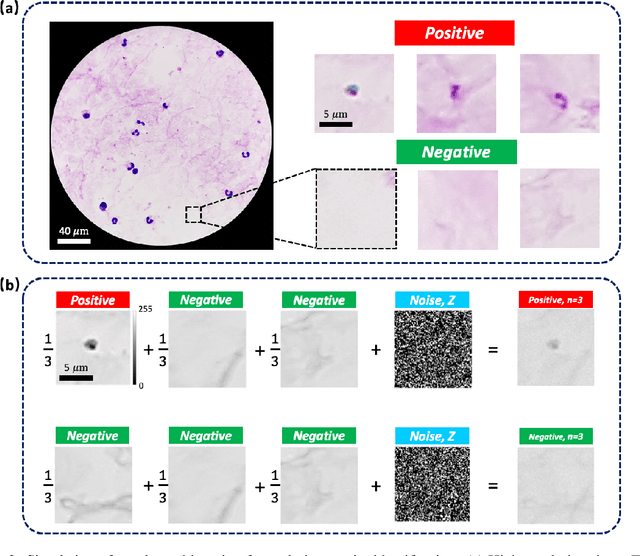
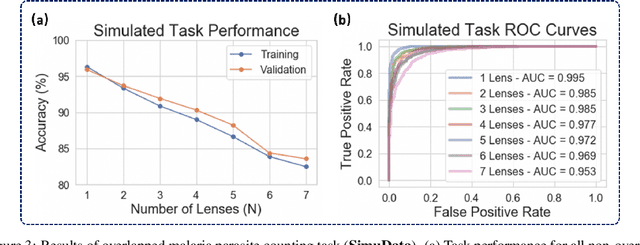
This work demonstrates a multi-lens microscopic imaging system that overlaps multiple independent fields of view on a single sensor for high-efficiency automated specimen analysis. Automatic detection, classification and counting of various morphological features of interest is now a crucial component of both biomedical research and disease diagnosis. While convolutional neural networks (CNNs) have dramatically improved the accuracy of counting cells and sub-cellular features from acquired digital image data, the overall throughput is still typically hindered by the limited space-bandwidth product (SBP) of conventional microscopes. Here, we show both in simulation and experiment that overlapped imaging and co-designed analysis software can achieve accurate detection of diagnostically-relevant features for several applications, including counting of white blood cells and the malaria parasite, leading to multi-fold increase in detection and processing throughput with minimal reduction in accuracy.