 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
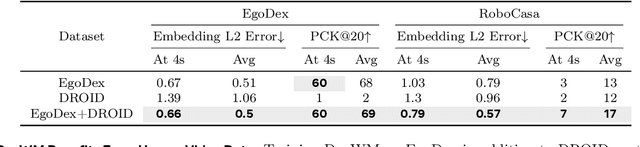
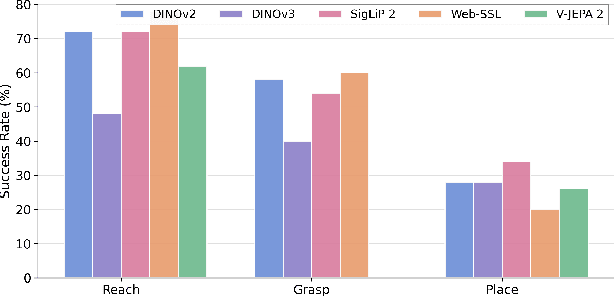
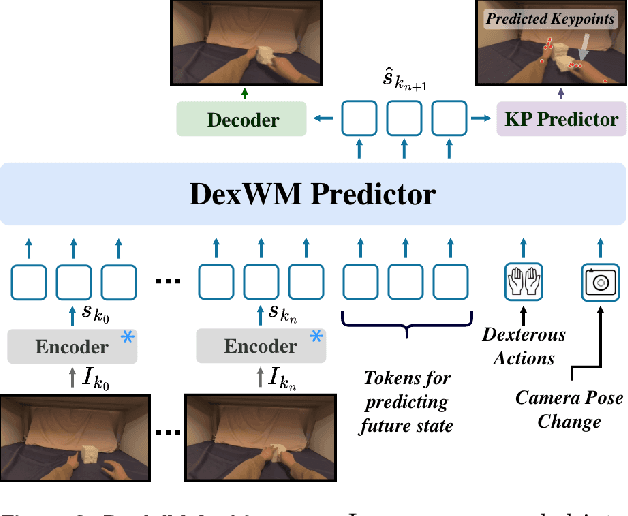
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
A Differentiable Distance Metric for Robotics Through Generalized Alternating Projection
Jul 01, 2025In many robotics applications, it is necessary to compute not only the distance between the robot and the environment, but also its derivative - for example, when using control barrier functions. However, since the traditional Euclidean distance is not differentiable, there is a need for alternative distance metrics that possess this property. Recently, a metric with guaranteed differentiability was proposed [1]. This approach has some important drawbacks, which we address in this paper. We provide much simpler and practical expressions for the smooth projection for general convex polytopes. Additionally, as opposed to [1], we ensure that the distance vanishes as the objects overlap. We show the efficacy of the approach in experimental results. Our proposed distance metric is publicly available through the Python-based simulation package UAIBot.
MapleGrasp: Mask-guided Feature Pooling for Language-driven Efficient Robotic Grasping
Jun 06, 2025Robotic manipulation of unseen objects via natural language commands remains challenging. Language driven robotic grasping (LDRG) predicts stable grasp poses from natural language queries and RGB-D images. Here we introduce Mask-guided feature pooling, a lightweight enhancement to existing LDRG methods. Our approach employs a two-stage training strategy: first, a vision-language model generates feature maps from CLIP-fused embeddings, which are upsampled and weighted by text embeddings to produce segmentation masks. Next, the decoder generates separate feature maps for grasp prediction, pooling only token features within these masked regions to efficiently predict grasp poses. This targeted pooling approach reduces computational complexity, accelerating both training and inference. Incorporating mask pooling results in a 12% improvement over prior approaches on the OCID-VLG benchmark. Furthermore, we introduce RefGraspNet, an open-source dataset eight times larger than existing alternatives, significantly enhancing model generalization for open-vocabulary grasping. By extending 2D grasp predictions to 3D via depth mapping and inverse kinematics, our modular method achieves performance comparable to recent Vision-Language-Action (VLA) models on the LIBERO simulation benchmark, with improved generalization across different task suites. Real-world experiments on a 7 DoF Franka robotic arm demonstrate a 57% success rate with unseen objects, surpassing competitive baselines by 7%. Code will be released post publication.
OSVI-WM: One-Shot Visual Imitation for Unseen Tasks using World-Model-Guided Trajectory Generation
May 26, 2025Visual imitation learning enables robotic agents to acquire skills by observing expert demonstration videos. In the one-shot setting, the agent generates a policy after observing a single expert demonstration without additional fine-tuning. Existing approaches typically train and evaluate on the same set of tasks, varying only object configurations, and struggle to generalize to unseen tasks with different semantic or structural requirements. While some recent methods attempt to address this, they exhibit low success rates on hard test tasks that, despite being visually similar to some training tasks, differ in context and require distinct responses. Additionally, most existing methods lack an explicit model of environment dynamics, limiting their ability to reason about future states. To address these limitations, we propose a novel framework for one-shot visual imitation learning via world-model-guided trajectory generation. Given an expert demonstration video and the agent's initial observation, our method leverages a learned world model to predict a sequence of latent states and actions. This latent trajectory is then decoded into physical waypoints that guide the agent's execution. Our method is evaluated on two simulated benchmarks and three real-world robotic platforms, where it consistently outperforms prior approaches, with over 30% improvement in some cases.
RAZER: Robust Accelerated Zero-Shot 3D Open-Vocabulary Panoptic Reconstruction with Spatio-Temporal Aggregation
May 21, 2025Mapping and understanding complex 3D environments is fundamental to how autonomous systems perceive and interact with the physical world, requiring both precise geometric reconstruction and rich semantic comprehension. While existing 3D semantic mapping systems excel at reconstructing and identifying predefined object instances, they lack the flexibility to efficiently build semantic maps with open-vocabulary during online operation. Although recent vision-language models have enabled open-vocabulary object recognition in 2D images, they haven't yet bridged the gap to 3D spatial understanding. The critical challenge lies in developing a training-free unified system that can simultaneously construct accurate 3D maps while maintaining semantic consistency and supporting natural language interactions in real time. In this paper, we develop a zero-shot framework that seamlessly integrates GPU-accelerated geometric reconstruction with open-vocabulary vision-language models through online instance-level semantic embedding fusion, guided by hierarchical object association with spatial indexing. Our training-free system achieves superior performance through incremental processing and unified geometric-semantic updates, while robustly handling 2D segmentation inconsistencies. The proposed general-purpose 3D scene understanding framework can be used for various tasks including zero-shot 3D instance retrieval, segmentation, and object detection to reason about previously unseen objects and interpret natural language queries. The project page is available at https://razer-3d.github.io.
CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution
May 21, 2025



Large Language Model (LLM) agents can automate cybersecurity tasks and can adapt to the evolving cybersecurity landscape without re-engineering. While LLM agents have demonstrated cybersecurity capabilities on Capture-The-Flag (CTF) competitions, they have two key limitations: accessing latest cybersecurity expertise beyond training data, and integrating new knowledge into complex task planning. Knowledge-based approaches that incorporate technical understanding into the task-solving automation can tackle these limitations. We present CRAKEN, a knowledge-based LLM agent framework that improves cybersecurity capability through three core mechanisms: contextual decomposition of task-critical information, iterative self-reflected knowledge retrieval, and knowledge-hint injection that transforms insights into adaptive attack strategies. Comprehensive evaluations with different configurations show CRAKEN's effectiveness in multi-stage vulnerability detection and exploitation compared to previous approaches. Our extensible architecture establishes new methodologies for embedding new security knowledge into LLM-driven cybersecurity agentic systems. With a knowledge database of CTF writeups, CRAKEN obtained an accuracy of 22% on NYU CTF Bench, outperforming prior works by 3% and achieving state-of-the-art results. On evaluation of MITRE ATT&CK techniques, CRAKEN solves 25-30% more techniques than prior work, demonstrating improved cybersecurity capabilities via knowledge-based execution. We make our framework open source to public https://github.com/NYU-LLM-CTF/nyuctf_agents_craken.
3D CAVLA: Leveraging Depth and 3D Context to Generalize Vision Language Action Models for Unseen Tasks
May 09, 2025Robotic manipulation in 3D requires learning an $N$ degree-of-freedom joint space trajectory of a robot manipulator. Robots must possess semantic and visual perception abilities to transform real-world mappings of their workspace into the low-level control necessary for object manipulation. Recent work has demonstrated the capabilities of fine-tuning large Vision-Language Models (VLMs) to learn the mapping between RGB images, language instructions, and joint space control. These models typically take as input RGB images of the workspace and language instructions, and are trained on large datasets of teleoperated robot demonstrations. In this work, we explore methods to improve the scene context awareness of a popular recent Vision-Language-Action model by integrating chain-of-thought reasoning, depth perception, and task-oriented region of interest detection. Our experiments in the LIBERO simulation environment show that our proposed model, 3D-CAVLA, improves the success rate across various LIBERO task suites, achieving an average success rate of 98.1$\%$. We also evaluate the zero-shot capabilities of our method, demonstrating that 3D scene awareness leads to robust learning and adaptation for completely unseen tasks. 3D-CAVLA achieves an absolute improvement of 8.8$\%$ on unseen tasks. We will open-source our code and the unseen tasks dataset to promote community-driven research here: https://3d-cavla.github.io
Safe Multi-Robotic Arm Interaction via 3D Convex Shapes
Mar 14, 2025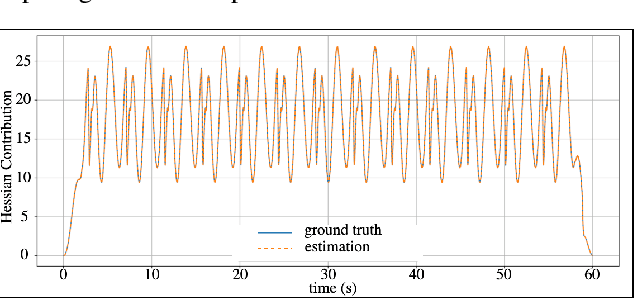
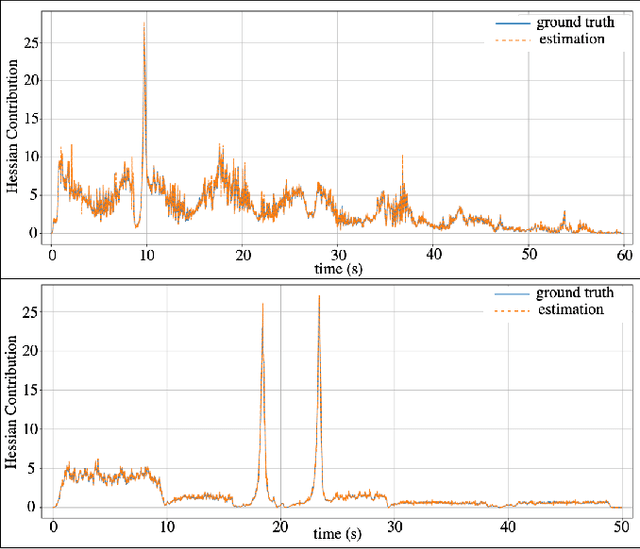


Inter-robot collisions pose a significant safety risk when multiple robotic arms operate in close proximity. We present an online collision avoidance methodology leveraging 3D convex shape-based High-Order Control Barrier Functions (HOCBFs) to address this issue. While prior works focused on using Control Barrier Functions (CBFs) for human-robotic arm and single-arm collision avoidance, we explore the problem of collision avoidance between multiple robotic arms operating in a shared space. In our methodology, we utilize the proposed HOCBFs as centralized and decentralized safety filters. These safety filters are compatible with any nominal controller and ensure safety without significantly restricting the robots' workspace. A key challenge in implementing these filters is the computational overhead caused by the large number of safety constraints and the computation of a Hessian matrix per constraint. We address this challenge by employing numerical differentiation methods to approximate computationally intensive terms. The effectiveness of our method is demonstrated through extensive simulation studies and real-world experiments with Franka Research 3 robotic arms.
Compliant Control of Quadruped Robots for Assistive Load Carrying
Mar 13, 2025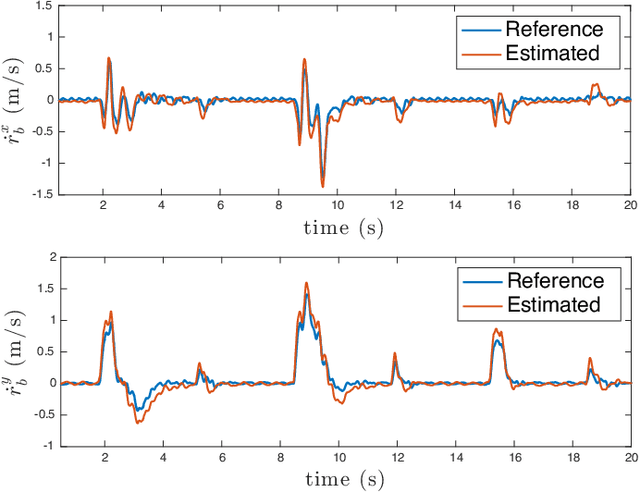
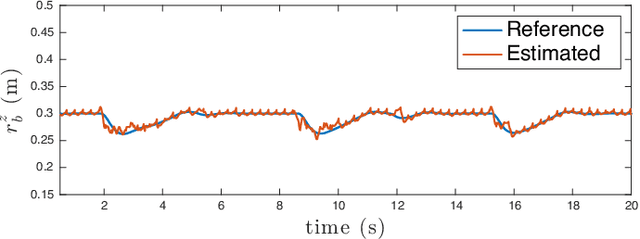
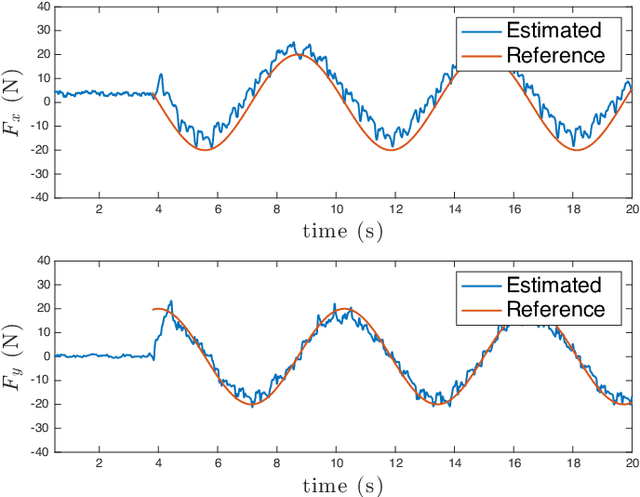
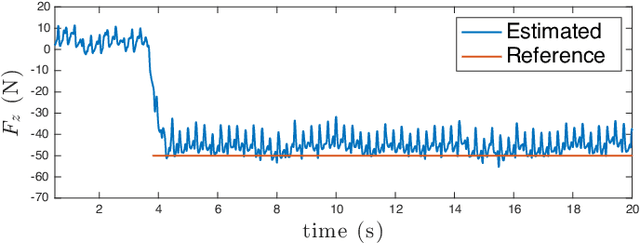
This paper presents a novel method for assistive load carrying using quadruped robots. The controller uses proprioceptive sensor data to estimate external base wrench, that is used for precise control of the robot's acceleration during payload transport. The acceleration is controlled using a combination of admittance control and Control Barrier Function (CBF) based quadratic program (QP). The proposed controller rejects disturbances and maintains consistent performance under varying load conditions. Additionally, the built-in CBF guarantees collision avoidance with the collaborative agent in front of the robot. The efficacy of the overall controller is shown by its implementation on the physical hardware as well as numerical simulations. The proposed control framework aims to enhance the quadruped robot's ability to perform assistive tasks in various scenarios, from industrial applications to search and rescue operations.
Distributed Inverse Dynamics Control for Quadruped Robots using Geometric Optimization
Dec 13, 2024

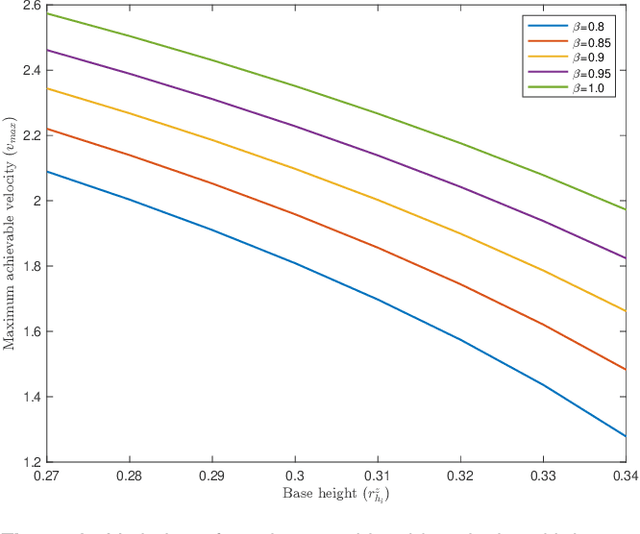
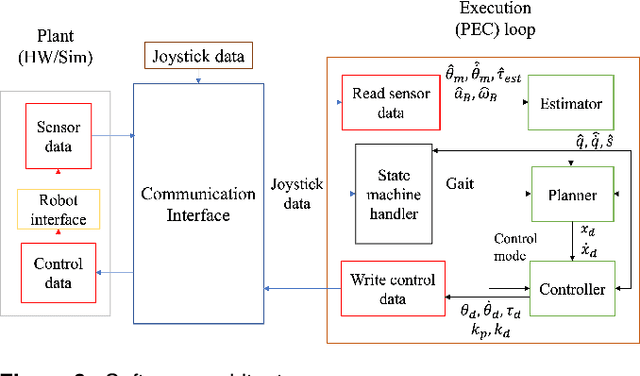
This paper presents a distributed inverse dynamics controller (DIDC) for quadruped robots that addresses the limitations of existing reactive controllers: simplified dynamical models, the inability to handle exact friction cone constraints, and the high computational requirements of whole-body controllers. Current methods either ignore friction constraints entirely or use linear approximations, leading to potential slip and instability, while comprehensive whole-body controllers demand significant computational resources. Our approach uses full rigid-body dynamics and enforces exact friction cone constraints through a novel geometric optimization-based solver. DIDC combines the required generalized forces corresponding to the actuated and unactuated spaces by projecting them onto the actuated space while satisfying the physical constraints and maintaining orthogonality between the base and joint tracking objectives. Experimental validation shows that our approach reduces foot slippage, improves orientation tracking, and converges at least two times faster than existing reactive controllers with generic QP-based implementations. The controller enables stable omnidirectional trotting at various speeds and consumes less power than comparable methods while running efficiently on embedded processors.