 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-Efficient and Stable Reinforcement Learning for LLM-based Recommendation
Jan 31, 2026While Long Chain-of-Thought (Long CoT) reasoning has shown promise in Large Language Models (LLMs), its adoption for enhancing recommendation quality is growing rapidly. In this work, we critically examine this trend and argue that Long CoT is inherently ill-suited for the sequential recommendation domain. We attribute this misalignment to two primary factors: excessive inference latency and the lack of explicit cognitive reasoning patterns in user behavioral data. Driven by these observations, we propose pivoting away from the CoT structure to directly leverage its underlying mechanism: Reinforcement Learning (RL), to explore the item space. However, applying RL directly faces significant obstacles, notably low sample efficiency-where most actions fail to provide learning signals-and training instability. To overcome these limitations, we propose RISER, a novel Reinforced Item Space Exploration framework for Recommendation. RISER is designed to transform non-learnable trajectories into effective pairwise preference data for optimization. Furthermore, it incorporates specific strategies to ensure stability, including the prevention of redundant rollouts and the constraint of token-level update magnitudes. Extensive experiments on three real-world datasets show that RISER significantly outperforms competitive baselines, establishing a robust paradigm for RL-enhanced LLM recommendation. Our code will be available at https://anonymous.4open.science/r/RISER/.
Searth Transformer: A Transformer Architecture Incorporating Earth's Geospheric Physical Priors for Global Mid-Range Weather Forecasting
Jan 14, 2026Accurate global medium-range weather forecasting is fundamental to Earth system science. Most existing Transformer-based forecasting models adopt vision-centric architectures that neglect the Earth's spherical geometry and zonal periodicity. In addition, conventional autoregressive training is computationally expensive and limits forecast horizons due to error accumulation. To address these challenges, we propose the Shifted Earth Transformer (Searth Transformer), a physics-informed architecture that incorporates zonal periodicity and meridional boundaries into window-based self-attention for physically consistent global information exchange. We further introduce a Relay Autoregressive (RAR) fine-tuning strategy that enables learning long-range atmospheric evolution under constrained memory and computational budgets. Based on these methods, we develop YanTian, a global medium-range weather forecasting model. YanTian achieves higher accuracy than the high-resolution forecast of the European Centre for Medium-Range Weather Forecasts and performs competitively with state-of-the-art AI models at one-degree resolution, while requiring roughly 200 times lower computational cost than standard autoregressive fine-tuning. Furthermore, YanTian attains a longer skillful forecast lead time for Z500 (10.3 days) than HRES (9 days). Beyond weather forecasting, this work establishes a robust algorithmic foundation for predictive modeling of complex global-scale geophysical circulation systems, offering new pathways for Earth system science.
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering
Jan 07, 2026Large Reasoning Models (LRMs) exhibit human-like cognitive reasoning strategies (e.g. backtracking, cross-verification) during reasoning process, which improves their performance on complex tasks. Currently, reasoning strategies are autonomously selected by LRMs themselves. However, such autonomous selection often produces inefficient or even erroneous reasoning paths. To make reasoning more reliable and flexible, it is important to develop methods for controlling reasoning strategies. Existing methods struggle to control fine-grained reasoning strategies due to conceptual entanglement in LRMs' hidden states. To address this, we leverage Sparse Autoencoders (SAEs) to decompose strategy-entangled hidden states into a disentangled feature space. To identify the few strategy-specific features from the vast pool of SAE features, we propose SAE-Steering, an efficient two-stage feature identification pipeline. SAE-Steering first recalls features that amplify the logits of strategy-specific keywords, filtering out over 99\% of features, and then ranks the remaining features by their control effectiveness. Using the identified strategy-specific features as control vectors, SAE-Steering outperforms existing methods by over 15\% in control effectiveness. Furthermore, controlling reasoning strategies can redirect LRMs from erroneous paths to correct ones, achieving a 7\% absolute accuracy improvement.
Submodular Evaluation Subset Selection in Automatic Prompt Optimization
Jan 07, 2026Automatic prompt optimization reduces manual prompt engineering, but relies on task performance measured on a small, often randomly sampled evaluation subset as its main source of feedback signal. Despite this, how to select that evaluation subset is usually treated as an implementation detail. We study evaluation subset selection for prompt optimization from a principled perspective and propose SESS, a submodular evaluation subset selection method. We frame selection as maximizing an objective set function and show that, under mild conditions, it is monotone and submodular, enabling greedy selection with theoretical guarantees. Across GSM8K, MATH, and GPQA-Diamond, submodularly selected evaluation subsets can yield better optimized prompts than random or heuristic baselines.
Phys-Liquid: A Physics-Informed Dataset for Estimating 3D Geometry and Volume of Transparent Deformable Liquids
Nov 14, 2025
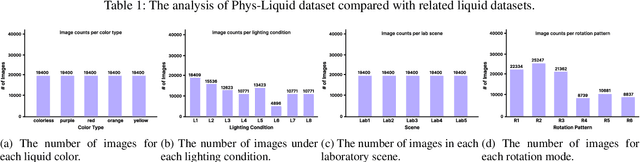
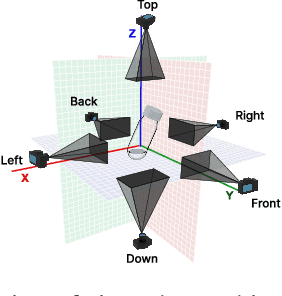

Estimating the geometric and volumetric properties of transparent deformable liquids is challenging due to optical complexities and dynamic surface deformations induced by container movements. Autonomous robots performing precise liquid manipulation tasks, such as dispensing, aspiration, and mixing, must handle containers in ways that inevitably induce these deformations, complicating accurate liquid state assessment. Current datasets lack comprehensive physics-informed simulation data representing realistic liquid behaviors under diverse dynamic scenarios. To bridge this gap, we introduce Phys-Liquid, a physics-informed dataset comprising 97,200 simulation images and corresponding 3D meshes, capturing liquid dynamics across multiple laboratory scenes, lighting conditions, liquid colors, and container rotations. To validate the realism and effectiveness of Phys-Liquid, we propose a four-stage reconstruction and estimation pipeline involving liquid segmentation, multi-view mask generation, 3D mesh reconstruction, and real-world scaling. Experimental results demonstrate improved accuracy and consistency in reconstructing liquid geometry and volume, outperforming existing benchmarks. The dataset and associated validation methods facilitate future advancements in transparent liquid perception tasks. The dataset and code are available at https://dualtransparency.github.io/Phys-Liquid/.
A Structured Review of Underwater Object Detection Challenges and Solutions: From Traditional to Large Vision Language Models
Sep 10, 2025Underwater object detection (UOD) is vital to diverse marine applications, including oceanographic research, underwater robotics, and marine conservation. However, UOD faces numerous challenges that compromise its performance. Over the years, various methods have been proposed to address these issues, but they often fail to fully capture the complexities of underwater environments. This review systematically categorizes UOD challenges into five key areas: Image quality degradation, target-related issues, data-related challenges, computational and processing constraints, and limitations in detection methodologies. To address these challenges, we analyze the progression from traditional image processing and object detection techniques to modern approaches. Additionally, we explore the potential of large vision-language models (LVLMs) in UOD, leveraging their multi-modal capabilities demonstrated in other domains. We also present case studies, including synthetic dataset generation using DALL-E 3 and fine-tuning Florence-2 LVLM for UOD. This review identifies three key insights: (i) Current UOD methods are insufficient to fully address challenges like image degradation and small object detection in dynamic underwater environments. (ii) Synthetic data generation using LVLMs shows potential for augmenting datasets but requires further refinement to ensure realism and applicability. (iii) LVLMs hold significant promise for UOD, but their real-time application remains under-explored, requiring further research on optimization techniques.
CurveFlow: Curvature-Guided Flow Matching for Image Generation
Aug 20, 2025Existing rectified flow models are based on linear trajectories between data and noise distributions. This linearity enforces zero curvature, which can inadvertently force the image generation process through low-probability regions of the data manifold. A key question remains underexplored: how does the curvature of these trajectories correlate with the semantic alignment between generated images and their corresponding captions, i.e., instructional compliance? To address this, we introduce CurveFlow, a novel flow matching framework designed to learn smooth, non-linear trajectories by directly incorporating curvature guidance into the flow path. Our method features a robust curvature regularization technique that penalizes abrupt changes in the trajectory's intrinsic dynamics.Extensive experiments on MS COCO 2014 and 2017 demonstrate that CurveFlow achieves state-of-the-art performance in text-to-image generation, significantly outperforming both standard rectified flow variants and other non-linear baselines like Rectified Diffusion. The improvements are especially evident in semantic consistency metrics such as BLEU, METEOR, ROUGE, and CLAIR. This confirms that our curvature-aware modeling substantially enhances the model's ability to faithfully follow complex instructions while simultaneously maintaining high image quality. The code is made publicly available at https://github.com/Harvard-AI-and-Robotics-Lab/CurveFlow.
Efficiency-Effectiveness Reranking FLOPs for LLM-based Rerankers
Jul 08, 2025Large Language Models (LLMs) have recently been applied to reranking tasks in information retrieval, achieving strong performance. However, their high computational demands often hinder practical deployment. Existing studies evaluate the efficiency of LLM-based rerankers using proxy metrics such as latency, the number of forward passes, input tokens, and output tokens. However, these metrics depend on hardware and running-time choices (\eg parallel or not, batch size, etc), and often fail to account for model size, making it difficult to interpret and obscuring the evaluation of the efficiency-effectiveness tradeoff. To address this issue, we propose E\textsuperscript{2}R-FLOPs, for LLM-based rerankers: ranking metrics per PetaFLOP (RPP) for relevance per compute and queries per PetaFLOP (QPP) for hardware-agnostic throughput. Companied with the new metrics, an interpretable FLOPs estimator is built to estimate the FLOPs of an LLM-based reranker even without running any experiments. Based on the proposed metrics, we conduct comprehensive experiments to evaluate a wide range of LLM-based rerankers with different architecture, studying the efficiency-effectiveness trade-off and bringing this issue to the attention of the research community.
Hierarchical Scoring with 3D Gaussian Splatting for Instance Image-Goal Navigation
Jun 09, 2025Instance Image-Goal Navigation (IIN) requires autonomous agents to identify and navigate to a target object or location depicted in a reference image captured from any viewpoint. While recent methods leverage powerful novel view synthesis (NVS) techniques, such as three-dimensional Gaussian splatting (3DGS), they typically rely on randomly sampling multiple viewpoints or trajectories to ensure comprehensive coverage of discriminative visual cues. This approach, however, creates significant redundancy through overlapping image samples and lacks principled view selection, substantially increasing both rendering and comparison overhead. In this paper, we introduce a novel IIN framework with a hierarchical scoring paradigm that estimates optimal viewpoints for target matching. Our approach integrates cross-level semantic scoring, utilizing CLIP-derived relevancy fields to identify regions with high semantic similarity to the target object class, with fine-grained local geometric scoring that performs precise pose estimation within promising regions. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on simulated IIN benchmarks and real-world applicability.
MapBERT: Bitwise Masked Modeling for Real-Time Semantic Mapping Generation
Jun 09, 2025Spatial awareness is a critical capability for embodied agents, as it enables them to anticipate and reason about unobserved regions. The primary challenge arises from learning the distribution of indoor semantics, complicated by sparse, imbalanced object categories and diverse spatial scales. Existing methods struggle to robustly generate unobserved areas in real time and do not generalize well to new environments. To this end, we propose \textbf{MapBERT}, a novel framework designed to effectively model the distribution of unseen spaces. Motivated by the observation that the one-hot encoding of semantic maps aligns naturally with the binary structure of bit encoding, we, for the first time, leverage a lookup-free BitVAE to encode semantic maps into compact bitwise tokens. Building on this, a masked transformer is employed to infer missing regions and generate complete semantic maps from limited observations. To enhance object-centric reasoning, we propose an object-aware masking strategy that masks entire object categories concurrently and pairs them with learnable embeddings, capturing implicit relationships between object embeddings and spatial tokens. By learning these relationships, the model more effectively captures indoor semantic distributions crucial for practical robotic tasks. Experiments on Gibson benchmarks show that MapBERT achieves state-of-the-art semantic map generation, balancing computational efficiency with accurate reconstruction of unobserved regions.