 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairDiffusion: Enhancing Equity in Latent Diffusion Models via Fair Bayesian Perturbation
Dec 29, 2024



Recent progress in generative AI, especially diffusion models, has demonstrated significant utility in text-to-image synthesis. Particularly in healthcare, these models offer immense potential in generating synthetic datasets and training medical students. However, despite these strong performances, it remains uncertain if the image generation quality is consistent across different demographic subgroups. To address this critical concern, we present the first comprehensive study on the fairness of medical text-to-image diffusion models. Our extensive evaluations of the popular Stable Diffusion model reveal significant disparities across gender, race, and ethnicity. To mitigate these biases, we introduce FairDiffusion, an equity-aware latent diffusion model that enhances fairness in both image generation quality as well as the semantic correlation of clinical features. In addition, we also design and curate FairGenMed, the first dataset for studying the fairness of medical generative models. Complementing this effort, we further evaluate FairDiffusion on two widely-used external medical datasets: HAM10000 (dermatoscopic images) and CheXpert (chest X-rays) to demonstrate FairDiffusion's effectiveness in addressing fairness concerns across diverse medical imaging modalities. Together, FairDiffusion and FairGenMed significantly advance research in fair generative learning, promoting equitable benefits of generative AI in healthcare.
FairDomain: Achieving Fairness in Cross-Domain Medical Image Segmentation and Classification
Jul 11, 2024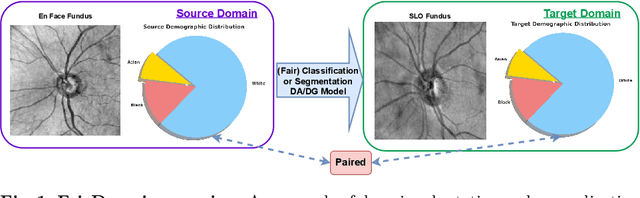
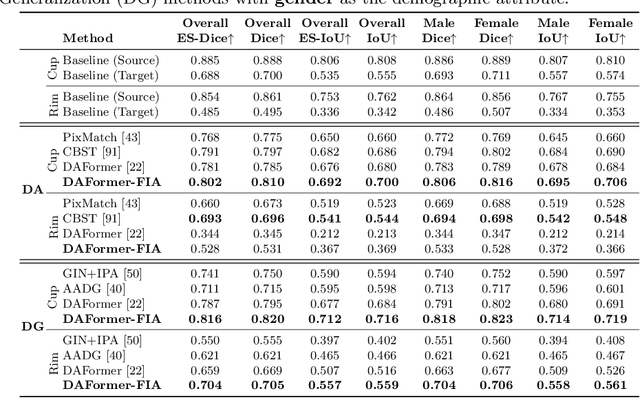
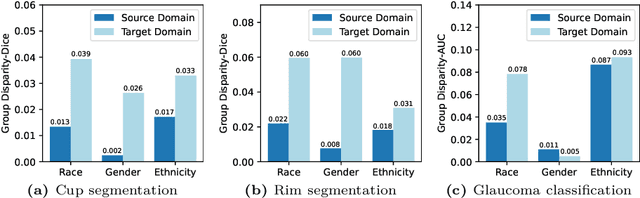
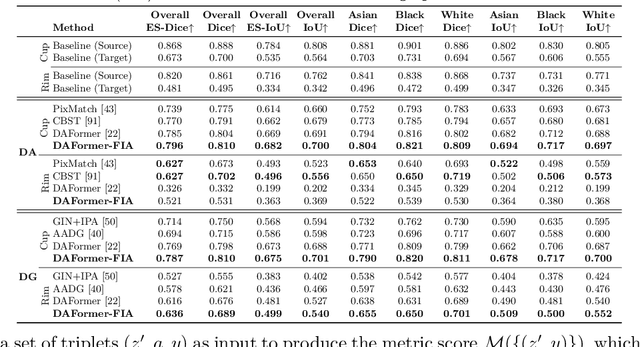
Addressing fairness in artificial intelligence (AI), particularly in medical AI, is crucial for ensuring equitable healthcare outcomes. Recent efforts to enhance fairness have introduced new methodologies and datasets in medical AI. However, the fairness issue under the setting of domain transfer is almost unexplored, while it is common that clinics rely on different imaging technologies (e.g., different retinal imaging modalities) for patient diagnosis. This paper presents FairDomain, a pioneering systemic study into algorithmic fairness under domain shifts, employing state-of-the-art domain adaptation (DA) and generalization (DG) algorithms for both medical segmentation and classification tasks to understand how biases are transferred between different domains. We also introduce a novel plug-and-play fair identity attention (FIA) module that adapts to various DA and DG algorithms to improve fairness by using self-attention to adjust feature importance based on demographic attributes. Additionally, we curate the first fairness-focused dataset with two paired imaging modalities for the same patient cohort on medical segmentation and classification tasks, to rigorously assess fairness in domain-shift scenarios. Excluding the confounding impact of demographic distribution variation between source and target domains will allow clearer quantification of the performance of domain transfer models. Our extensive evaluations reveal that the proposed FIA significantly enhances both model performance accounted for fairness across all domain shift settings (i.e., DA and DG) with respect to different demographics, which outperforms existing methods on both segmentation and classification. The code and data can be accessed at https://ophai.hms.harvard.edu/datasets/harvard-fairdomain20k.
FairCLIP: Harnessing Fairness in Vision-Language Learning
Apr 05, 2024



Fairness is a critical concern in deep learning, especially in healthcare, where these models influence diagnoses and treatment decisions. Although fairness has been investigated in the vision-only domain, the fairness of medical vision-language (VL) models remains unexplored due to the scarcity of medical VL datasets for studying fairness. To bridge this research gap, we introduce the first fair vision-language medical dataset Harvard-FairVLMed that provides detailed demographic attributes, ground-truth labels, and clinical notes to facilitate an in-depth examination of fairness within VL foundation models. Using Harvard-FairVLMed, we conduct a comprehensive fairness analysis of two widely-used VL models (CLIP and BLIP2), pre-trained on both natural and medical domains, across four different protected attributes. Our results highlight significant biases in all VL models, with Asian, Male, Non-Hispanic, and Spanish being the preferred subgroups across the protected attributes of race, gender, ethnicity, and language, respectively. In order to alleviate these biases, we propose FairCLIP, an optimal-transport-based approach that achieves a favorable trade-off between performance and fairness by reducing the Sinkhorn distance between the overall sample distribution and the distributions corresponding to each demographic group. As the first VL dataset of its kind, Harvard-FairVLMed holds the potential to catalyze advancements in the development of machine learning models that are both ethically aware and clinically effective. Our dataset and code are available at https://ophai.hms.harvard.edu/datasets/harvard-fairvlmed10k.