 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
MedConclusion: A Benchmark for Biomedical Conclusion Generation from Structured Abstracts
Apr 07, 2026Large language models (LLMs) are widely explored for reasoning-intensive research tasks, yet resources for testing whether they can infer scientific conclusions from structured biomedical evidence remain limited. We introduce $\textbf{MedConclusion}$, a large-scale dataset of $\textbf{5.7M}$ PubMed structured abstracts for biomedical conclusion generation. Each instance pairs the non-conclusion sections of an abstract with the original author-written conclusion, providing naturally occurring supervision for evidence-to-conclusion reasoning. MedConclusion also includes journal-level metadata such as biomedical category and SJR, enabling subgroup analysis across biomedical domains. As an initial study, we evaluate diverse LLMs under conclusion and summary prompting settings and score outputs with both reference-based metrics and LLM-as-a-judge. We find that conclusion writing is behaviorally distinct from summary writing, strong models remain closely clustered under current automatic metrics, and judge identity can substantially shift absolute scores. MedConclusion provides a reusable data resource for studying scientific evidence-to-conclusion reasoning. Our code and data are available at: https://github.com/Harvard-AI-and-Robotics-Lab/MedConclusion.
Story2Proposal: A Scaffold for Structured Scientific Paper Writing
Mar 28, 2026Generating scientific manuscripts requires maintaining alignment between narrative reasoning, experimental evidence, and visual artifacts across the document lifecycle. Existing language-model generation pipelines rely on unconstrained text synthesis with validation applied only after generation, often producing structural drift, missing figures or tables, and cross-section inconsistencies. We introduce Story2Proposal, a contract-governed multi-agent framework that converts a research story into a structured manuscript through coordinated agents operating under a persistent shared visual contract. The system organizes architect, writer, refiner, and renderer agents around a contract state that tracks section structure and registered visual elements, while evaluation agents supply feedback in a generate evaluate adapt loop that updates the contract during generation. Experiments on tasks derived from the Jericho research corpus show that Story2Proposal achieved an expert evaluation score of 6.145 versus 3.963 for DirectChat (+2.182) across GPT, Claude, Gemini, and Qwen backbones. Compared with the structured generation baseline Fars, Story2Proposal obtained an average score of 5.705 versus 5.197, indicating improved structural consistency and visual alignment.
Fair Benchmarking of Emerging One-Step Generative Models Against Multistep Diffusion and Flow Models
Mar 15, 2026State-of-the-art text-to-image models produce high-quality images, but inference remains expensive as generation requires several sequential ODE or denoising steps. Native one-step models aim to reduce this cost by mapping noise to an image in a single step, yet fair comparisons to multi-step systems are difficult because studies use mismatched sampling steps and different classifier-free guidance (CFG) settings, where CFG can shift FID, Inception Score, and CLIP-based alignment in opposing directions. It is also unclear how well one-step models scale to multi-step inference, and there is limited standardized out-of-distribution evaluation for label-ID-conditioned generators beyond ImageNet. To address this, We benchmark eight models spanning one-step flows (MeanFlow, Improved MeanFlow, SoFlow), multi-step baselines (RAE, Scale-RAE), and established systems (SiT, Stable Diffusion 3.5, FLUX.1) under a controlled class-conditional protocol on ImageNet validation, ImageNetV2, and reLAIONet, our new proofread out-of-distribution dataset aligned to ImageNet label IDs. Using FID, Inception Score, CLIP Score, and Pick Score, we show that FID-focused model development and CFG selection can be misleading in few-step regimes, where guidance changes can improve FID while degrading text-image alignment and human preference signals and worsening perceived quality. We further show that leading one-step models benefit from step scaling and become substantially more competitive under multi-step inference, although they still exhibit characteristic local distortions. To capture these tradeoffs, we introduce MinMax Harmonic Mean (MMHM), a composite proxy over all four metrics that stabilizes hyperparameter selection across guidance and step sweeps.
Single-Slice-to-3D Reconstruction in Medical Imaging and Natural Objects: A Comparative Benchmark with SAM 3D
Feb 10, 2026A 3D understanding of anatomy is central to diagnosis and treatment planning, yet volumetric imaging remains costly with long wait times. Image-to-3D foundations models can solve this issue by reconstructing 3D data from 2D modalites. Current foundation models are trained on natural image distributions to reconstruct naturalistic objects from a single image by leveraging geometric priors across pixels. However, it is unclear whether these learned geometric priors transfer to medical data. In this study, we present a controlled zero-shot benchmark of single slice medical image-to-3D reconstruction across five state-of-the-art image-to-3D models: SAM3D, Hunyuan3D-2.1, Direct3D, Hi3DGen, and TripoSG. These are evaluated across six medical datasets spanning anatomical and pathological structures and two natrual datasets, using voxel based metrics and point cloud distance metrics. Across medical datasets, voxel based overlap remains moderate for all models, consistent with a depth reconstruction failure mode when inferring volume from a single slice. In contrast, global distance metrics show more separation between methods: SAM3D achieves the strongest overall topological similarity to ground truth medical 3D data, while alternative models are more prone to over-simplication of reconstruction. Our results quantify the limits of single-slice medical reconstruction and highlight depth ambiguity caused by the planar nature of 2D medical data, motivating multi-view image-to-3D reconstruction to enable reliable medical 3D inference.
Look-Ahead and Look-Back Flows: Training-Free Image Generation with Trajectory Smoothing
Feb 10, 2026Recent advances have reformulated diffusion models as deterministic ordinary differential equations (ODEs) through the framework of flow matching, providing a unified formulation for the noise-to-data generative process. Various training-free flow matching approaches have been developed to improve image generation through flow velocity field adjustment, eliminating the need for costly retraining. However, Modifying the velocity field $v$ introduces errors that propagate through the full generation path, whereas adjustments to the latent trajectory $z$ are naturally corrected by the pretrained velocity network, reducing error accumulation. In this paper, we propose two complementary training-free latent-trajectory adjustment approaches based on future and past velocity $v$ and latent trajectory $z$ information that refine the generative path directly in latent space. We propose two training-free trajectory smoothing schemes: \emph{Look-Ahead}, which averages the current and next-step latents using a curvature-gated weight, and \emph{Look-Back}, which smoothes latents using an exponential moving average with decay. We demonstrate through extensive experiments and comprehensive evaluation metrics that the proposed training-free trajectory smoothing models substantially outperform various state-of-the-art models across multiple datasets including COCO17, CUB-200, and Flickr30K.
ADPretrain: Advancing Industrial Anomaly Detection via Anomaly Representation Pretraining
Nov 07, 2025The current mainstream and state-of-the-art anomaly detection (AD) methods are substantially established on pretrained feature networks yielded by ImageNet pretraining. However, regardless of supervised or self-supervised pretraining, the pretraining process on ImageNet does not match the goal of anomaly detection (i.e., pretraining in natural images doesn't aim to distinguish between normal and abnormal). Moreover, natural images and industrial image data in AD scenarios typically have the distribution shift. The two issues can cause ImageNet-pretrained features to be suboptimal for AD tasks. To further promote the development of the AD field, pretrained representations specially for AD tasks are eager and very valuable. To this end, we propose a novel AD representation learning framework specially designed for learning robust and discriminative pretrained representations for industrial anomaly detection. Specifically, closely surrounding the goal of anomaly detection (i.e., focus on discrepancies between normals and anomalies), we propose angle- and norm-oriented contrastive losses to maximize the angle size and norm difference between normal and abnormal features simultaneously. To avoid the distribution shift from natural images to AD images, our pretraining is performed on a large-scale AD dataset, RealIAD. To further alleviate the potential shift between pretraining data and downstream AD datasets, we learn the pretrained AD representations based on the class-generalizable representation, residual features. For evaluation, based on five embedding-based AD methods, we simply replace their original features with our pretrained representations. Extensive experiments on five AD datasets and five backbones consistently show the superiority of our pretrained features. The code is available at https://github.com/xcyao00/ADPretrain.
CurveFlow: Curvature-Guided Flow Matching for Image Generation
Aug 20, 2025Existing rectified flow models are based on linear trajectories between data and noise distributions. This linearity enforces zero curvature, which can inadvertently force the image generation process through low-probability regions of the data manifold. A key question remains underexplored: how does the curvature of these trajectories correlate with the semantic alignment between generated images and their corresponding captions, i.e., instructional compliance? To address this, we introduce CurveFlow, a novel flow matching framework designed to learn smooth, non-linear trajectories by directly incorporating curvature guidance into the flow path. Our method features a robust curvature regularization technique that penalizes abrupt changes in the trajectory's intrinsic dynamics.Extensive experiments on MS COCO 2014 and 2017 demonstrate that CurveFlow achieves state-of-the-art performance in text-to-image generation, significantly outperforming both standard rectified flow variants and other non-linear baselines like Rectified Diffusion. The improvements are especially evident in semantic consistency metrics such as BLEU, METEOR, ROUGE, and CLAIR. This confirms that our curvature-aware modeling substantially enhances the model's ability to faithfully follow complex instructions while simultaneously maintaining high image quality. The code is made publicly available at https://github.com/Harvard-AI-and-Robotics-Lab/CurveFlow.
DA-Occ: Efficient 3D Voxel Occupancy Prediction via Directional 2D for Geometric Structure Preservation
Jul 31, 2025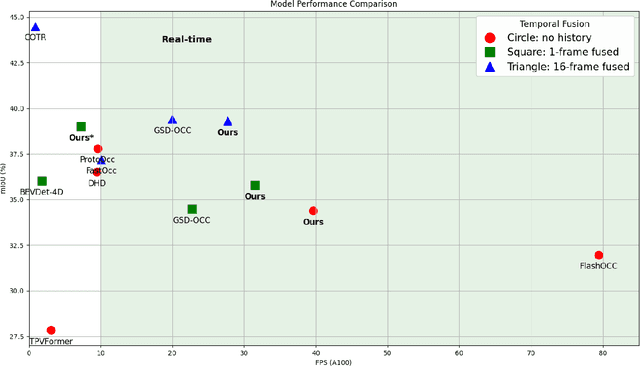
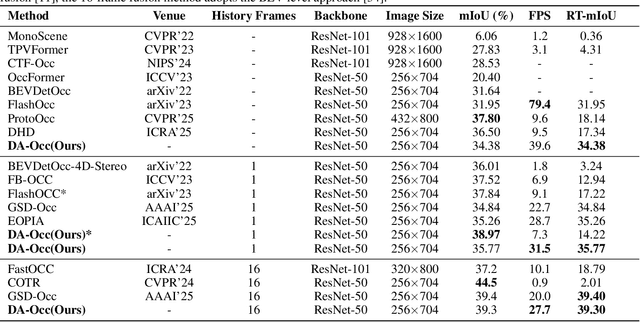
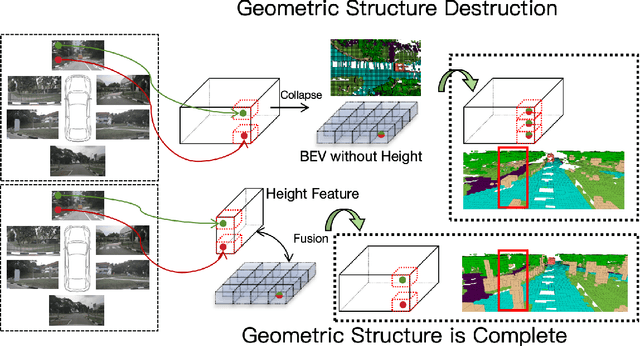
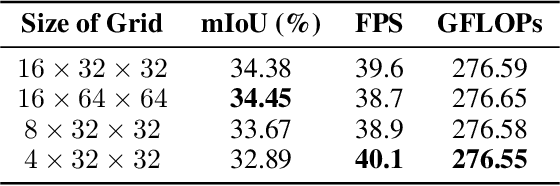
Efficient and high-accuracy 3D occupancy prediction is crucial for ensuring the performance of autonomous driving (AD) systems. However, many current methods focus on high accuracy at the expense of real-time processing needs. To address this challenge of balancing accuracy and inference speed, we propose a directional pure 2D approach. Our method involves slicing 3D voxel features to preserve complete vertical geometric information. This strategy compensates for the loss of height cues in Bird's-Eye View (BEV) representations, thereby maintaining the integrity of the 3D geometric structure. By employing a directional attention mechanism, we efficiently extract geometric features from different orientations, striking a balance between accuracy and computational efficiency. Experimental results highlight the significant advantages of our approach for autonomous driving. On the Occ3D-nuScenes, the proposed method achieves an mIoU of 39.3% and an inference speed of 27.7 FPS, effectively balancing accuracy and efficiency. In simulations on edge devices, the inference speed reaches 14.8 FPS, further demonstrating the method's applicability for real-time deployment in resource-constrained environments.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.