 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
Spiking Heterogeneous Graph Attention Networks
Dec 31, 2025Real-world graphs or networks are usually heterogeneous, involving multiple types of nodes and relationships. Heterogeneous graph neural networks (HGNNs) can effectively handle these diverse nodes and edges, capturing heterogeneous information within the graph, thus exhibiting outstanding performance. However, most methods of HGNNs usually involve complex structural designs, leading to problems such as high memory usage, long inference time, and extensive consumption of computing resources. These limitations pose certain challenges for the practical application of HGNNs, especially for resource-constrained devices. To mitigate this issue, we propose the Spiking Heterogeneous Graph Attention Networks (SpikingHAN), which incorporates the brain-inspired and energy-saving properties of Spiking Neural Networks (SNNs) into heterogeneous graph learning to reduce the computing cost without compromising the performance. Specifically, SpikingHAN aggregates metapath-based neighbor information using a single-layer graph convolution with shared parameters. It then employs a semantic-level attention mechanism to capture the importance of different meta-paths and performs semantic aggregation. Finally, it encodes the heterogeneous information into a spike sequence through SNNs, simulating bioinformatic processing to derive a binarized 1-bit representation of the heterogeneous graph. Comprehensive experimental results from three real-world heterogeneous graph datasets show that SpikingHAN delivers competitive node classification performance. It achieves this with fewer parameters, quicker inference, reduced memory usage, and lower energy consumption. Code is available at https://github.com/QianPeng369/SpikingHAN.
T2I-Copilot: A Training-Free Multi-Agent Text-to-Image System for Enhanced Prompt Interpretation and Interactive Generation
Jul 28, 2025



Text-to-Image (T2I) generative models have revolutionized content creation but remain highly sensitive to prompt phrasing, often requiring users to repeatedly refine prompts multiple times without clear feedback. While techniques such as automatic prompt engineering, controlled text embeddings, denoising, and multi-turn generation mitigate these issues, they offer limited controllability, or often necessitate additional training, restricting the generalization abilities. Thus, we introduce T2I-Copilot, a training-free multi-agent system that leverages collaboration between (Multimodal) Large Language Models to automate prompt phrasing, model selection, and iterative refinement. This approach significantly simplifies prompt engineering while enhancing generation quality and text-image alignment compared to direct generation. Specifically, T2I-Copilot consists of three agents: (1) Input Interpreter, which parses the input prompt, resolves ambiguities, and generates a standardized report; (2) Generation Engine, which selects the appropriate model from different types of T2I models and organizes visual and textual prompts to initiate generation; and (3) Quality Evaluator, which assesses aesthetic quality and text-image alignment, providing scores and feedback for potential regeneration. T2I-Copilot can operate fully autonomously while also supporting human-in-the-loop intervention for fine-grained control. On GenAI-Bench, using open-source generation models, T2I-Copilot achieves a VQA score comparable to commercial models RecraftV3 and Imagen 3, surpasses FLUX1.1-pro by 6.17% at only 16.59% of its cost, and outperforms FLUX.1-dev and SD 3.5 Large by 9.11% and 6.36%. Code will be released at: https://github.com/SHI-Labs/T2I-Copilot.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Apr 06, 2025
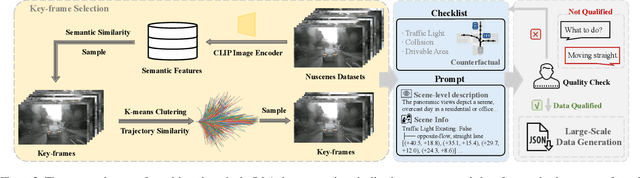
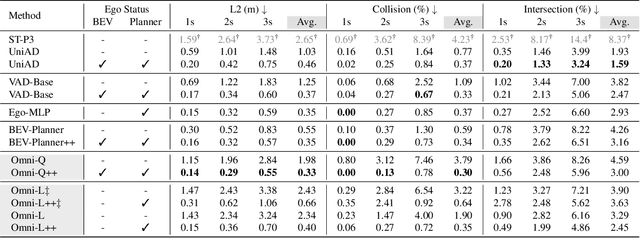
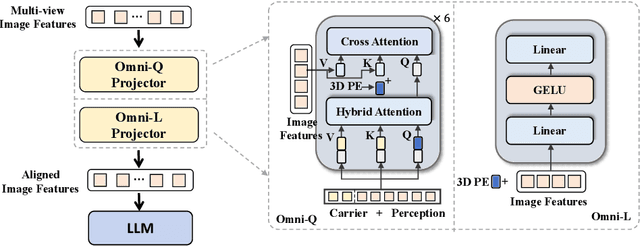
The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q\&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.
FairDiffusion: Enhancing Equity in Latent Diffusion Models via Fair Bayesian Perturbation
Dec 29, 2024



Recent progress in generative AI, especially diffusion models, has demonstrated significant utility in text-to-image synthesis. Particularly in healthcare, these models offer immense potential in generating synthetic datasets and training medical students. However, despite these strong performances, it remains uncertain if the image generation quality is consistent across different demographic subgroups. To address this critical concern, we present the first comprehensive study on the fairness of medical text-to-image diffusion models. Our extensive evaluations of the popular Stable Diffusion model reveal significant disparities across gender, race, and ethnicity. To mitigate these biases, we introduce FairDiffusion, an equity-aware latent diffusion model that enhances fairness in both image generation quality as well as the semantic correlation of clinical features. In addition, we also design and curate FairGenMed, the first dataset for studying the fairness of medical generative models. Complementing this effort, we further evaluate FairDiffusion on two widely-used external medical datasets: HAM10000 (dermatoscopic images) and CheXpert (chest X-rays) to demonstrate FairDiffusion's effectiveness in addressing fairness concerns across diverse medical imaging modalities. Together, FairDiffusion and FairGenMed significantly advance research in fair generative learning, promoting equitable benefits of generative AI in healthcare.
Impact of Data Distribution on Fairness Guarantees in Equitable Deep Learning
Dec 29, 2024



We present a comprehensive theoretical framework analyzing the relationship between data distributions and fairness guarantees in equitable deep learning. Our work establishes novel theoretical bounds that explicitly account for data distribution heterogeneity across demographic groups, while introducing a formal analysis framework that minimizes expected loss differences across these groups. We derive comprehensive theoretical bounds for fairness errors and convergence rates, and characterize how distributional differences between groups affect the fundamental trade-off between fairness and accuracy. Through extensive experiments on diverse datasets, including FairVision (ophthalmology), CheXpert (chest X-rays), HAM10000 (dermatology), and FairFace (facial recognition), we validate our theoretical findings and demonstrate that differences in feature distributions across demographic groups significantly impact model fairness, with performance disparities particularly pronounced in racial categories. The theoretical bounds we derive crroborate these empirical observations, providing insights into the fundamental limits of achieving fairness in deep learning models when faced with heterogeneous data distributions. This work advances our understanding of fairness in AI-based diagnosis systems and provides a theoretical foundation for developing more equitable algorithms. The code for analysis is publicly available via \url{https://github.com/Harvard-Ophthalmology-AI-Lab/fairness_guarantees}.
TransFair: Transferring Fairness from Ocular Disease Classification to Progression Prediction
Dec 03, 2024



The use of artificial intelligence (AI) in automated disease classification significantly reduces healthcare costs and improves the accessibility of services. However, this transformation has given rise to concerns about the fairness of AI, which disproportionately affects certain groups, particularly patients from underprivileged populations. Recently, a number of methods and large-scale datasets have been proposed to address group performance disparities. Although these methods have shown effectiveness in disease classification tasks, they may fall short in ensuring fair prediction of disease progression, mainly because of limited longitudinal data with diverse demographics available for training a robust and equitable prediction model. In this paper, we introduce TransFair to enhance demographic fairness in progression prediction for ocular diseases. TransFair aims to transfer a fairness-enhanced disease classification model to the task of progression prediction with fairness preserved. Specifically, we train a fair EfficientNet, termed FairEN, equipped with a fairness-aware attention mechanism using extensive data for ocular disease classification. Subsequently, this fair classification model is adapted to a fair progression prediction model through knowledge distillation, which aims to minimize the latent feature distances between the classification and progression prediction models. We evaluate FairEN and TransFair for fairness-enhanced ocular disease classification and progression prediction using both two-dimensional (2D) and 3D retinal images. Extensive experiments and comparisons with models with and without considering fairness learning show that TransFair effectively enhances demographic equity in predicting ocular disease progression.
Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
Aug 28, 2024



The ability to accurately interpret complex visual information is a crucial topic of multimodal large language models (MLLMs). Recent work indicates that enhanced visual perception significantly reduces hallucinations and improves performance on resolution-sensitive tasks, such as optical character recognition and document analysis. A number of recent MLLMs achieve this goal using a mixture of vision encoders. Despite their success, there is a lack of systematic comparisons and detailed ablation studies addressing critical aspects, such as expert selection and the integration of multiple vision experts. This study provides an extensive exploration of the design space for MLLMs using a mixture of vision encoders and resolutions. Our findings reveal several underlying principles common to various existing strategies, leading to a streamlined yet effective design approach. We discover that simply concatenating visual tokens from a set of complementary vision encoders is as effective as more complex mixing architectures or strategies. We additionally introduce Pre-Alignment to bridge the gap between vision-focused encoders and language tokens, enhancing model coherence. The resulting family of MLLMs, Eagle, surpasses other leading open-source models on major MLLM benchmarks. Models and code: https://github.com/NVlabs/Eagle