 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Normalizing Flows
Jun 26, 2025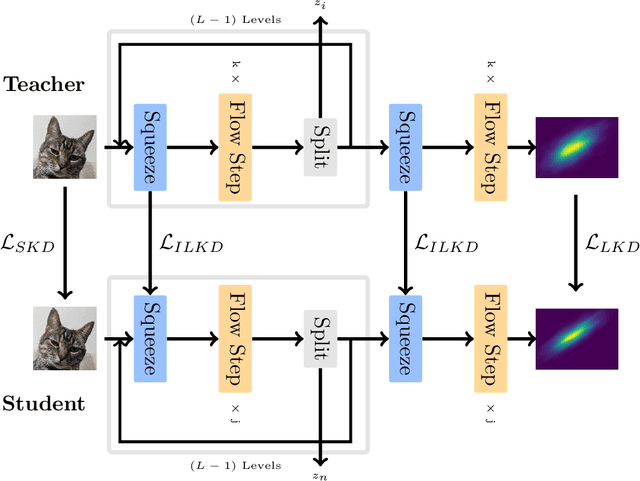
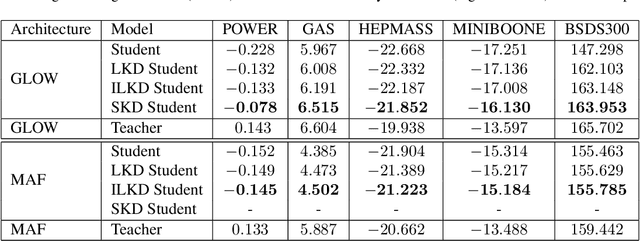
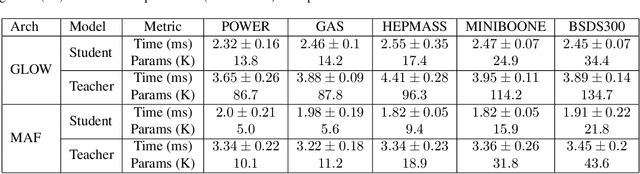

Explicit density learners are becoming an increasingly popular technique for generative models because of their ability to better model probability distributions. They have advantages over Generative Adversarial Networks due to their ability to perform density estimation and having exact latent-variable inference. This has many advantages, including: being able to simply interpolate, calculate sample likelihood, and analyze the probability distribution. The downside of these models is that they are often more difficult to train and have lower sampling quality. Normalizing flows are explicit density models, that use composable bijective functions to turn an intractable probability function into a tractable one. In this work, we present novel knowledge distillation techniques to increase sampling quality and density estimation of smaller student normalizing flows. We seek to study the capacity of knowledge distillation in Compositional Normalizing Flows to understand the benefits and weaknesses provided by these architectures. Normalizing flows have unique properties that allow for a non-traditional forms of knowledge transfer, where we can transfer that knowledge within intermediate layers. We find that through this distillation, we can make students significantly smaller while making substantial performance gains over a non-distilled student. With smaller models there is a proportionally increased throughput as this is dependent upon the number of bijectors, and thus parameters, in the network.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
StyleNAT: Giving Each Head a New Perspective
Nov 10, 2022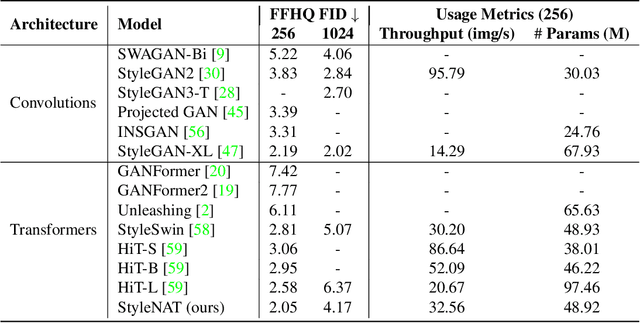
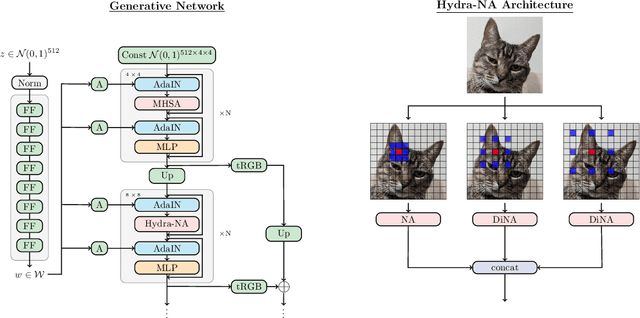
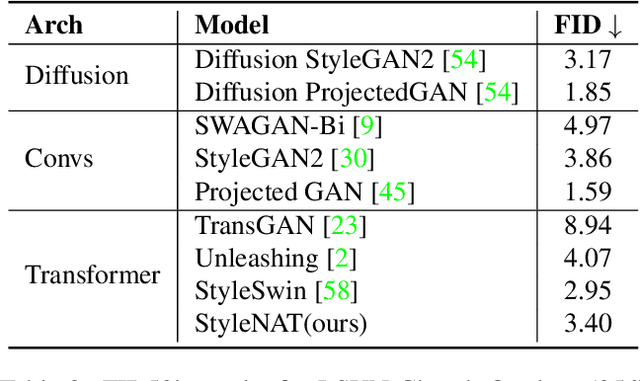
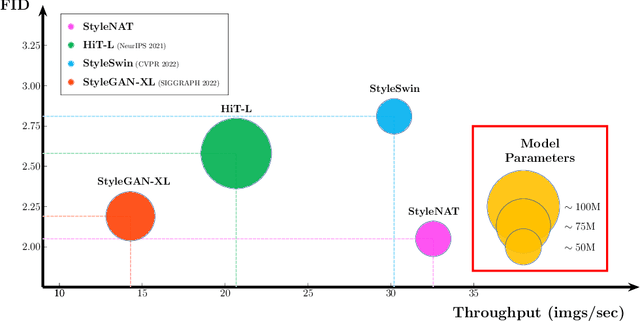
Image generation has been a long sought-after but challenging task, and performing the generation task in an efficient manner is similarly difficult. Often researchers attempt to create a "one size fits all" generator, where there are few differences in the parameter space for drastically different datasets. Herein, we present a new transformer-based framework, dubbed StyleNAT, targeting high-quality image generation with superior efficiency and flexibility. At the core of our model, is a carefully designed framework that partitions attention heads to capture local and global information, which is achieved through using Neighborhood Attention (NA). With different heads able to pay attention to varying receptive fields, the model is able to better combine this information, and adapt, in a highly flexible manner, to the data at hand. StyleNAT attains a new SOTA FID score on FFHQ-256 with 2.046, beating prior arts with convolutional models such as StyleGAN-XL and transformers such as HIT and StyleSwin, and a new transformer SOTA on FFHQ-1024 with an FID score of 4.174. These results show a 6.4% improvement on FFHQ-256 scores when compared to StyleGAN-XL with a 28% reduction in the number of parameters and 56% improvement in sampling throughput. Code and models will be open-sourced at https://github.com/SHI-Labs/StyleNAT .
Design Amortization for Bayesian Optimal Experimental Design
Oct 07, 2022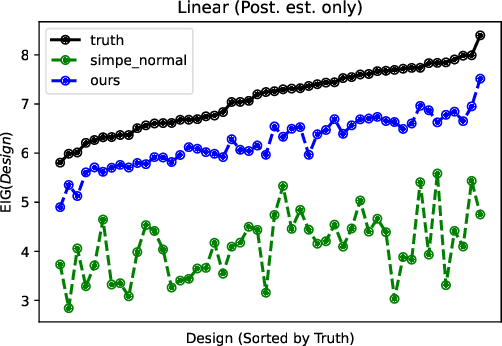
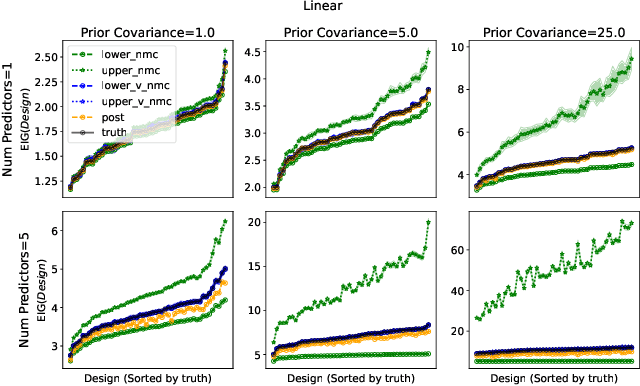
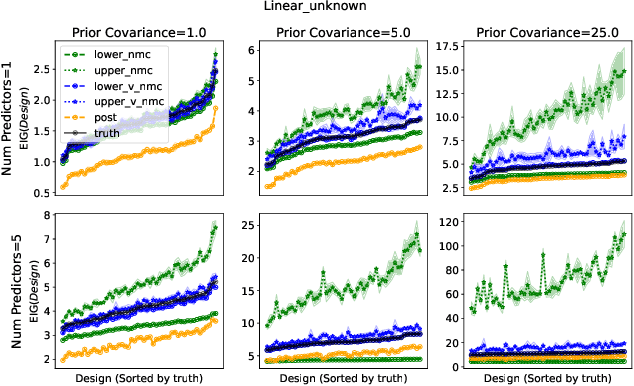
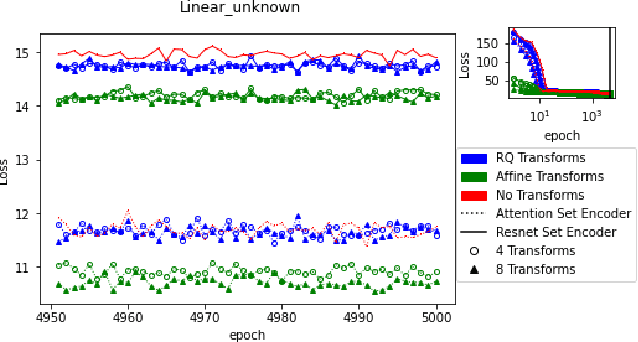
Bayesian optimal experimental design is a sub-field of statistics focused on developing methods to make efficient use of experimental resources. Any potential design is evaluated in terms of a utility function, such as the (theoretically well-justified) expected information gain (EIG); unfortunately however, under most circumstances the EIG is intractable to evaluate. In this work we build off of successful variational approaches, which optimize a parameterized variational model with respect to bounds on the EIG. Past work focused on learning a new variational model from scratch for each new design considered. Here we present a novel neural architecture that allows experimenters to optimize a single variational model that can estimate the EIG for potentially infinitely many designs. To further improve computational efficiency, we also propose to train the variational model on a significantly cheaper-to-evaluate lower bound, and show empirically that the resulting model provides an excellent guide for more accurate, but expensive to evaluate bounds on the EIG. We demonstrate the effectiveness of our technique on generalized linear models, a class of statistical models that is widely used in the analysis of controlled experiments. Experiments show that our method is able to greatly improve accuracy over existing approximation strategies, and achieve these results with far better sample efficiency.
Neighborhood Attention Transformer
Apr 14, 2022
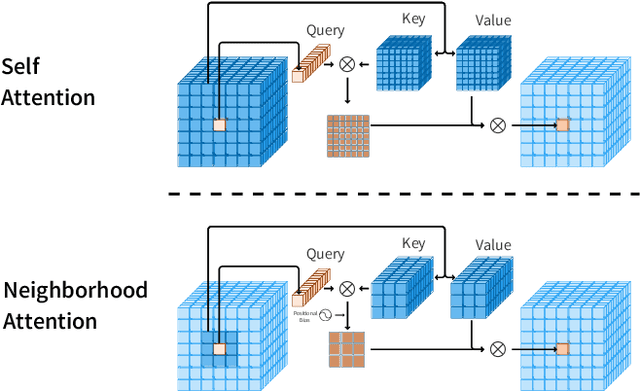
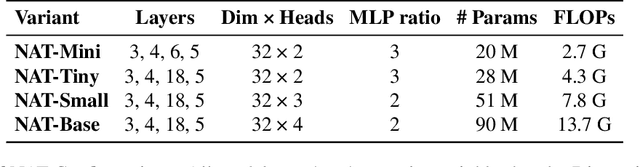
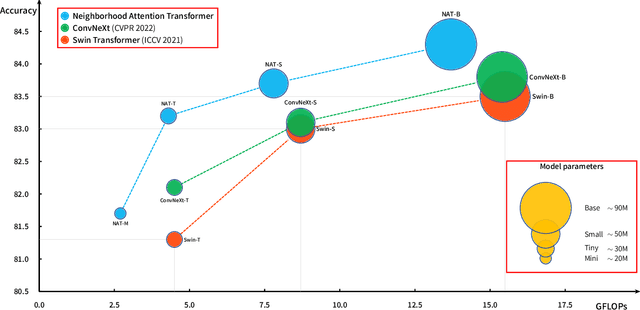
We present Neighborhood Attention Transformer (NAT), an efficient, accurate and scalable hierarchical transformer that works well on both image classification and downstream vision tasks. It is built upon Neighborhood Attention (NA), a simple and flexible attention mechanism that localizes the receptive field for each query to its nearest neighboring pixels. NA is a localization of self-attention, and approaches it as the receptive field size increases. It is also equivalent in FLOPs and memory usage to Swin Transformer's shifted window attention given the same receptive field size, while being less constrained. Furthermore, NA includes local inductive biases, which eliminate the need for extra operations such as pixel shifts. Experimental results on NAT are competitive; NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet with only 4.3 GFLOPs and 28M parameters, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20k. We will open-source our checkpoints, training script, configurations, and our CUDA kernel at: https://github.com/SHI-Labs/Neighborhood-Attention-Transformer .
SeMask: Semantically Masked Transformers for Semantic Segmentation
Dec 23, 2021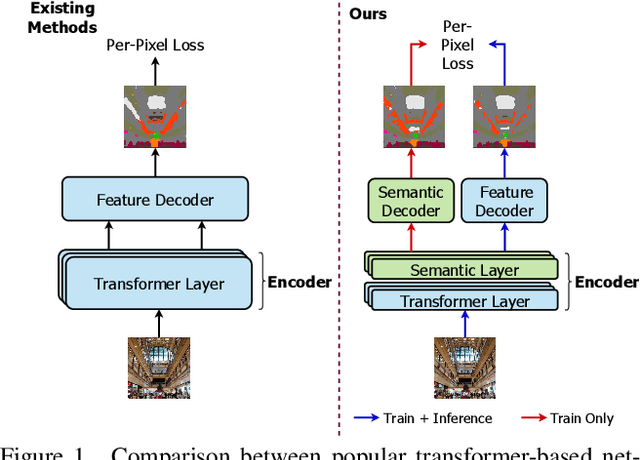
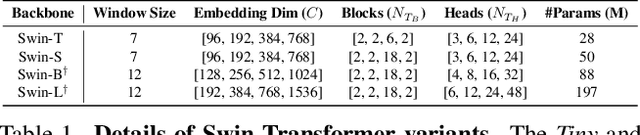
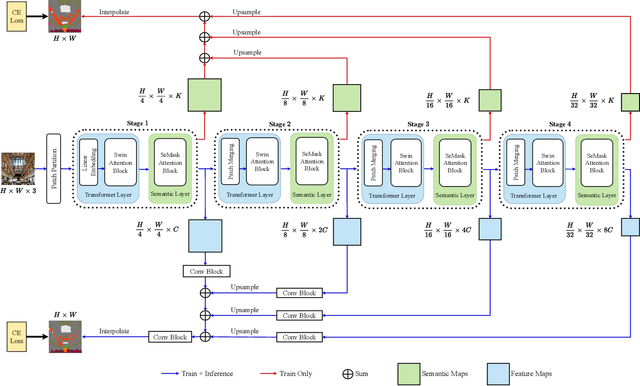
Finetuning a pretrained backbone in the encoder part of an image transformer network has been the traditional approach for the semantic segmentation task. However, such an approach leaves out the semantic context that an image provides during the encoding stage. This paper argues that incorporating semantic information of the image into pretrained hierarchical transformer-based backbones while finetuning improves the performance considerably. To achieve this, we propose SeMask, a simple and effective framework that incorporates semantic information into the encoder with the help of a semantic attention operation. In addition, we use a lightweight semantic decoder during training to provide supervision to the intermediate semantic prior maps at every stage. Our experiments demonstrate that incorporating semantic priors enhances the performance of the established hierarchical encoders with a slight increase in the number of FLOPs. We provide empirical proof by integrating SeMask into each variant of the Swin-Transformer as our encoder paired with different decoders. Our framework achieves a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. The code and checkpoints are publicly available at https://github.com/Picsart-AI-Research/SeMask-Segmentation .
ConvMLP: Hierarchical Convolutional MLPs for Vision
Sep 18, 2021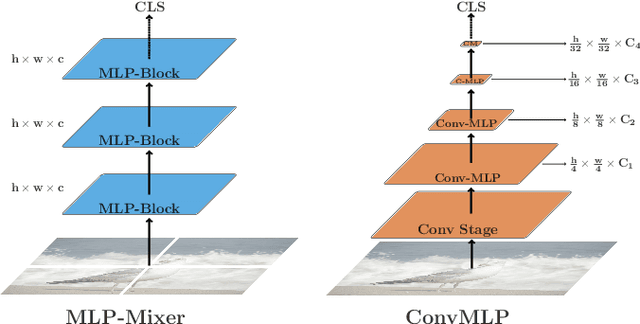



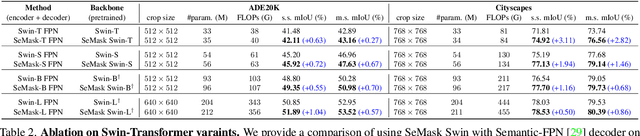
MLP-based architectures, which consist of a sequence of consecutive multi-layer perceptron blocks, have recently been found to reach comparable results to convolutional and transformer-based methods. However, most adopt spatial MLPs which take fixed dimension inputs, therefore making it difficult to apply them to downstream tasks, such as object detection and semantic segmentation. Moreover, single-stage designs further limit performance in other computer vision tasks and fully connected layers bear heavy computation. To tackle these problems, we propose ConvMLP: a hierarchical Convolutional MLP for visual recognition, which is a light-weight, stage-wise, co-design of convolution layers, and MLPs. In particular, ConvMLP-S achieves 76.8% top-1 accuracy on ImageNet-1k with 9M parameters and 2.4G MACs (15% and 19% of MLP-Mixer-B/16, respectively). Experiments on object detection and semantic segmentation further show that visual representation learned by ConvMLP can be seamlessly transferred and achieve competitive results with fewer parameters. Our code and pre-trained models are publicly available at https://github.com/SHI-Labs/Convolutional-MLPs.
Escaping the Big Data Paradigm with Compact Transformers
Apr 12, 2021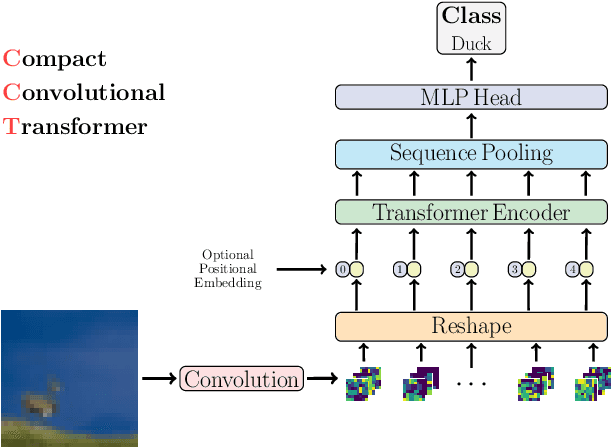

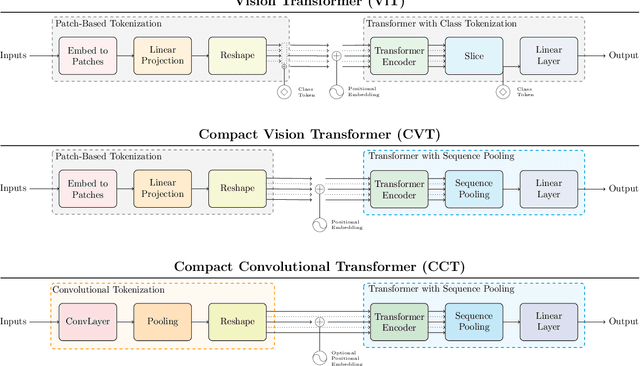
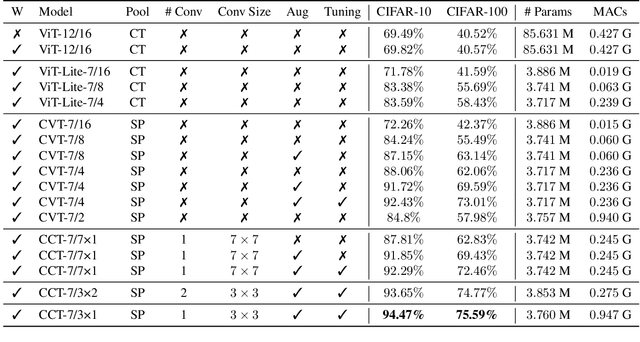
With the rise of Transformers as the standard for language processing, and their advancements in computer vision, along with their unprecedented size and amounts of training data, many have come to believe that they are not suitable for small sets of data. This trend leads to great concerns, including but not limited to: limited availability of data in certain scientific domains and the exclusion of those with limited resource from research in the field. In this paper, we dispel the myth that transformers are "data hungry" and therefore can only be applied to large sets of data. We show for the first time that with the right size and tokenization, transformers can perform head-to-head with state-of-the-art CNNs on small datasets. Our model eliminates the requirement for class token and positional embeddings through a novel sequence pooling strategy and the use of convolutions. We show that compared to CNNs, our compact transformers have fewer parameters and MACs, while obtaining similar accuracies. Our method is flexible in terms of model size, and can have as little as 0.28M parameters and achieve reasonable results. It can reach an accuracy of 94.72% when training from scratch on CIFAR-10, which is comparable with modern CNN based approaches, and a significant improvement over previous Transformer based models. Our simple and compact design democratizes transformers by making them accessible to those equipped with basic computing resources and/or dealing with important small datasets. Our code and pre-trained models will be made publicly available at https://github.com/SHI-Labs/Compact-Transformers.