 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighborhood Attention Transformer
Paper and Code

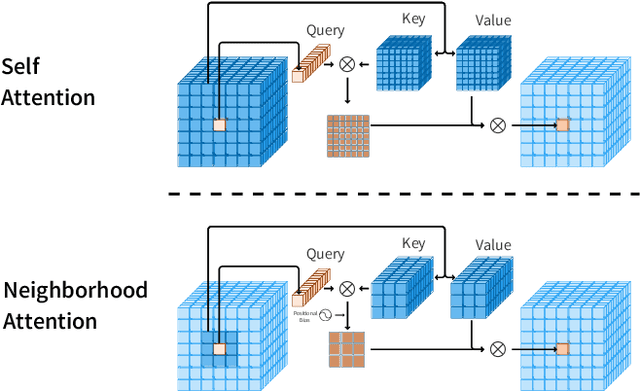
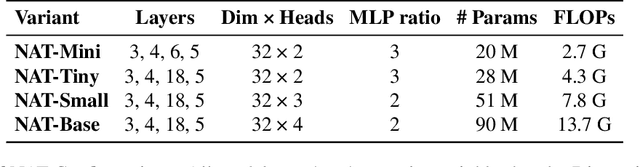
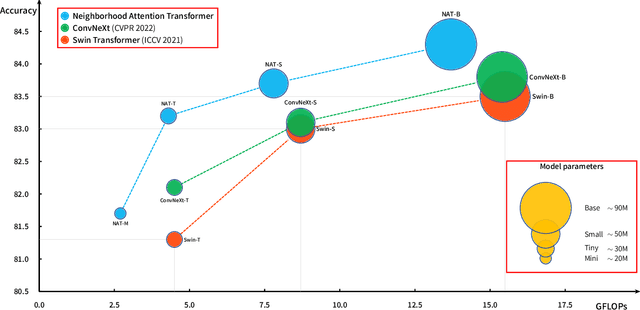
We present Neighborhood Attention Transformer (NAT), an efficient, accurate and scalable hierarchical transformer that works well on both image classification and downstream vision tasks. It is built upon Neighborhood Attention (NA), a simple and flexible attention mechanism that localizes the receptive field for each query to its nearest neighboring pixels. NA is a localization of self-attention, and approaches it as the receptive field size increases. It is also equivalent in FLOPs and memory usage to Swin Transformer's shifted window attention given the same receptive field size, while being less constrained. Furthermore, NA includes local inductive biases, which eliminate the need for extra operations such as pixel shifts. Experimental results on NAT are competitive; NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet with only 4.3 GFLOPs and 28M parameters, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20k. We will open-source our checkpoints, training script, configurations, and our CUDA kernel at: https://github.com/SHI-Labs/Neighborhood-Attention-Transformer .