 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVO: Agentic Variation Operators for Autonomous Evolutionary Search
Mar 25, 2026Agentic Variation Operators (AVO) are a new family of evolutionary variation operators that replace the fixed mutation, crossover, and hand-designed heuristics of classical evolutionary search with autonomous coding agents. Rather than confining a language model to candidate generation within a prescribed pipeline, AVO instantiates variation as a self-directed agent loop that can consult the current lineage, a domain-specific knowledge base, and execution feedback to propose, repair, critique, and verify implementation edits. We evaluate AVO on attention, among the most aggressively optimized kernel targets in AI, on NVIDIA Blackwell (B200) GPUs. Over 7 days of continuous autonomous evolution on multi-head attention, AVO discovers kernels that outperform cuDNN by up to 3.5% and FlashAttention-4 by up to 10.5% across the evaluated configurations. The discovered optimizations transfer readily to grouped-query attention, requiring only 30 minutes of additional autonomous adaptation and yielding gains of up to 7.0% over cuDNN and 9.3% over FlashAttention-4. Together, these results show that agentic variation operators move beyond prior LLM-in-the-loop evolutionary pipelines by elevating the agent from candidate generator to variation operator, and can discover performance-critical micro-architectural optimizations that produce kernels surpassing state-of-the-art expert-engineered attention implementations on today's most advanced GPU hardware.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
Faster Neighborhood Attention: Reducing the O(n^2) Cost of Self Attention at the Threadblock Level
Mar 07, 2024



Neighborhood attention reduces the cost of self attention by restricting each token's attention span to its nearest neighbors. This restriction, parameterized by a window size and dilation factor, draws a spectrum of possible attention patterns between linear projection and self attention. Neighborhood attention, and more generally sliding window attention patterns, have long been bounded by infrastructure, particularly in higher-rank spaces (2-D and 3-D), calling for the development of custom kernels, which have been limited in either functionality, or performance, if not both. In this work, we first show that neighborhood attention can be represented as a batched GEMM problem, similar to standard attention, and implement it for 1-D and 2-D neighborhood attention. These kernels on average provide 895% and 272% improvement in full precision latency compared to existing naive kernels for 1-D and 2-D neighborhood attention respectively. We find certain inherent inefficiencies in all unfused neighborhood attention kernels that bound their performance and lower-precision scalability. We also developed fused neighborhood attention; an adaptation of fused dot-product attention kernels that allow fine-grained control over attention across different spatial axes. Known for reducing the quadratic time complexity of self attention to a linear complexity, neighborhood attention can now enjoy a reduced and constant memory footprint, and record-breaking half precision latency. We observe that our fused kernels successfully circumvent some of the unavoidable inefficiencies in unfused implementations. While our unfused GEMM-based kernels only improve half precision performance compared to naive kernels by an average of 496% and 113% in 1-D and 2-D problems respectively, our fused kernels improve naive kernels by an average of 1607% and 581% in 1-D and 2-D problems respectively.
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
OneFormer: One Transformer to Rule Universal Image Segmentation
Nov 10, 2022



Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible. To support further research, we open-source our code and models at https://github.com/SHI-Labs/OneFormer
StyleNAT: Giving Each Head a New Perspective
Nov 10, 2022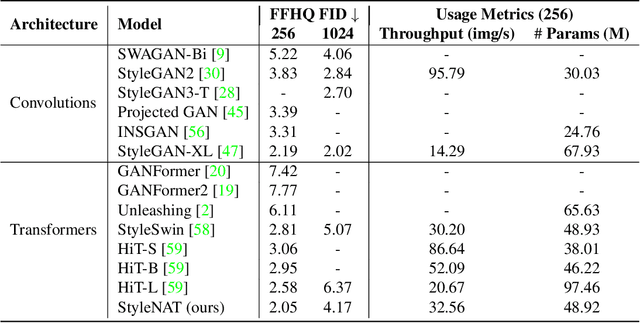
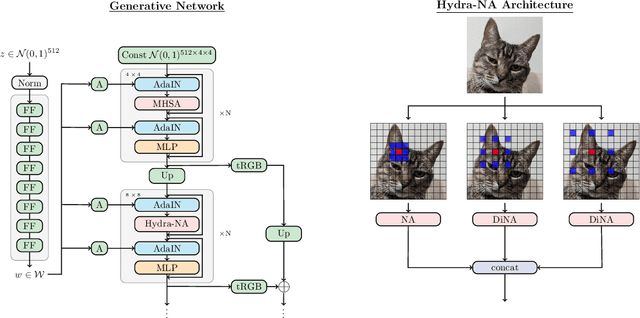
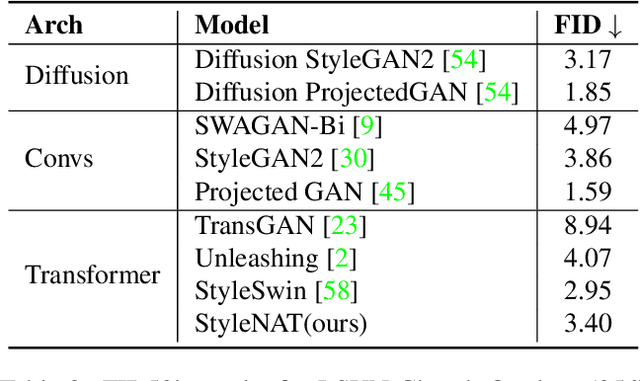
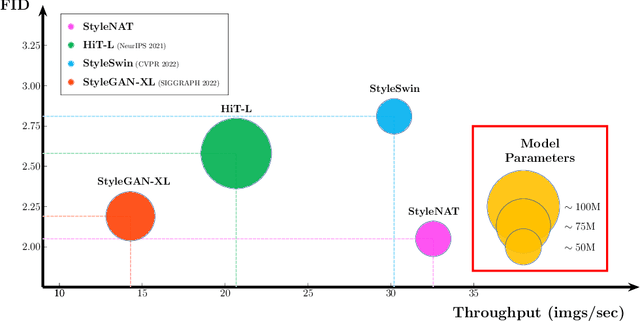
Image generation has been a long sought-after but challenging task, and performing the generation task in an efficient manner is similarly difficult. Often researchers attempt to create a "one size fits all" generator, where there are few differences in the parameter space for drastically different datasets. Herein, we present a new transformer-based framework, dubbed StyleNAT, targeting high-quality image generation with superior efficiency and flexibility. At the core of our model, is a carefully designed framework that partitions attention heads to capture local and global information, which is achieved through using Neighborhood Attention (NA). With different heads able to pay attention to varying receptive fields, the model is able to better combine this information, and adapt, in a highly flexible manner, to the data at hand. StyleNAT attains a new SOTA FID score on FFHQ-256 with 2.046, beating prior arts with convolutional models such as StyleGAN-XL and transformers such as HIT and StyleSwin, and a new transformer SOTA on FFHQ-1024 with an FID score of 4.174. These results show a 6.4% improvement on FFHQ-256 scores when compared to StyleGAN-XL with a 28% reduction in the number of parameters and 56% improvement in sampling throughput. Code and models will be open-sourced at https://github.com/SHI-Labs/StyleNAT .
Dilated Neighborhood Attention Transformer
Sep 29, 2022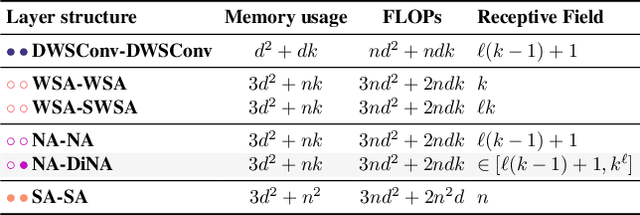
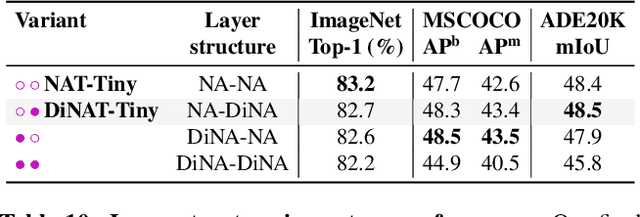
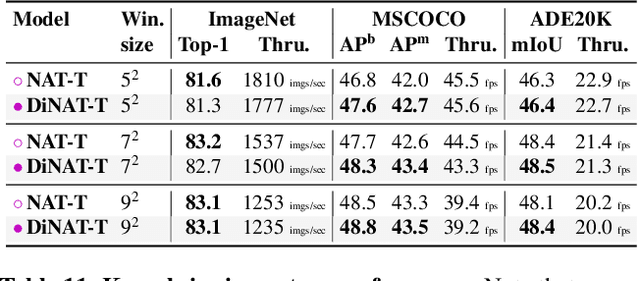
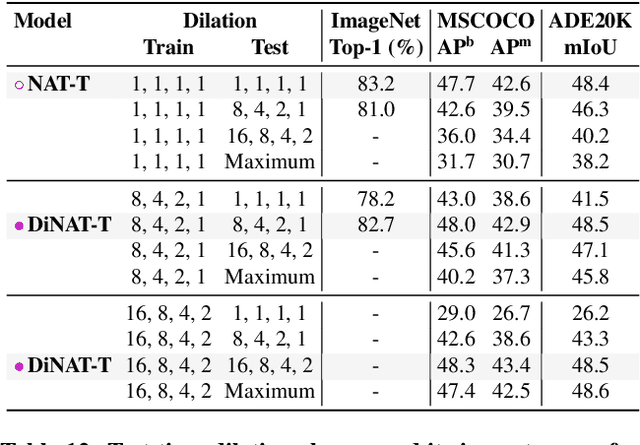
Transformers are quickly becoming one of the most heavily applied deep learning architectures across modalities, domains, and tasks. In vision, on top of ongoing efforts into plain transformers, hierarchical transformers have also gained significant attention, thanks to their performance and easy integration into existing frameworks. These models typically employ localized attention mechanisms, such as the sliding-window Neighborhood Attention (NA) or Swin Transformer's Shifted Window Self Attention. While effective at reducing self attention's quadratic complexity, local attention weakens two of the most desirable properties of self attention: long range inter-dependency modeling, and global receptive field. In this paper, we introduce Dilated Neighborhood Attention (DiNA), a natural, flexible and efficient extension to NA that can capture more global context and expand receptive fields exponentially at no additional cost. NA's local attention and DiNA's sparse global attention complement each other, and therefore we introduce Dilated Neighborhood Attention Transformer (DiNAT), a new hierarchical vision transformer built upon both. DiNAT variants enjoy significant improvements over attention-based baselines such as NAT and Swin, as well as modern convolutional baseline ConvNeXt. Our Large model is ahead of its Swin counterpart by 1.5% box AP in COCO object detection, 1.3% mask AP in COCO instance segmentation, and 1.1% mIoU in ADE20K semantic segmentation, and faster in throughput. We believe combinations of NA and DiNA have the potential to empower various tasks beyond those presented in this paper. To support and encourage research in this direction, in vision and beyond, we open-source our project at: https://github.com/SHI-Labs/Neighborhood-Attention-Transformer.
AdaFocusV3: On Unified Spatial-temporal Dynamic Video Recognition
Sep 27, 2022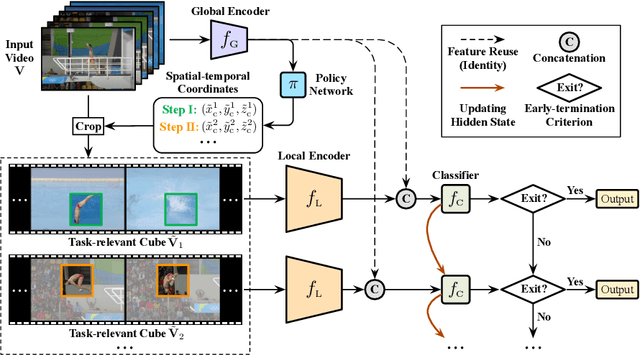
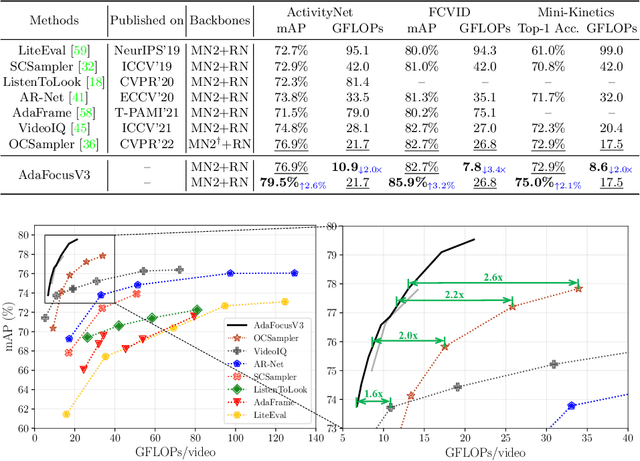
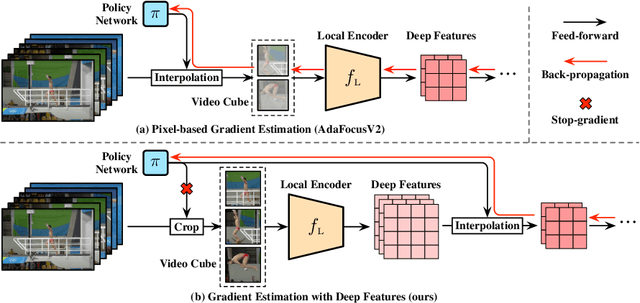
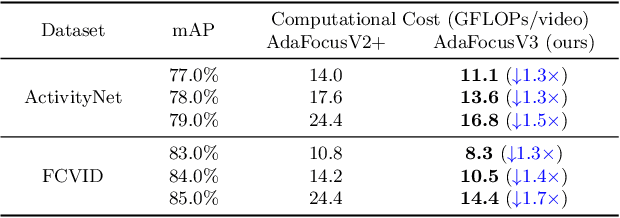
Recent research has revealed that reducing the temporal and spatial redundancy are both effective approaches towards efficient video recognition, e.g., allocating the majority of computation to a task-relevant subset of frames or the most valuable image regions of each frame. However, in most existing works, either type of redundancy is typically modeled with another absent. This paper explores the unified formulation of spatial-temporal dynamic computation on top of the recently proposed AdaFocusV2 algorithm, contributing to an improved AdaFocusV3 framework. Our method reduces the computational cost by activating the expensive high-capacity network only on some small but informative 3D video cubes. These cubes are cropped from the space formed by frame height, width, and video duration, while their locations are adaptively determined with a light-weighted policy network on a per-sample basis. At test time, the number of the cubes corresponding to each video is dynamically configured, i.e., video cubes are processed sequentially until a sufficiently reliable prediction is produced. Notably, AdaFocusV3 can be effectively trained by approximating the non-differentiable cropping operation with the interpolation of deep features. Extensive empirical results on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2 and Diving48) demonstrate that our model is considerably more efficient than competitive baselines.
Distilling Facial Knowledge With Teacher-Tasks: Semantic-Segmentation-Features For Pose-Invariant Face-Recognition
Sep 02, 2022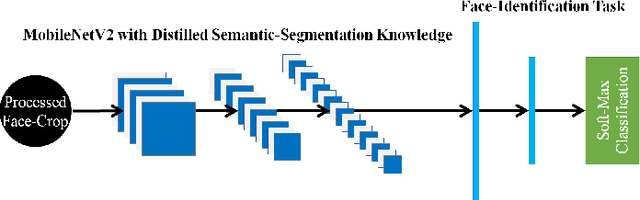
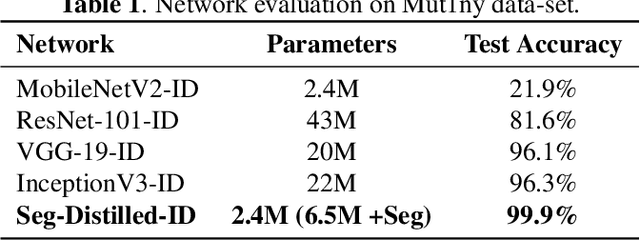
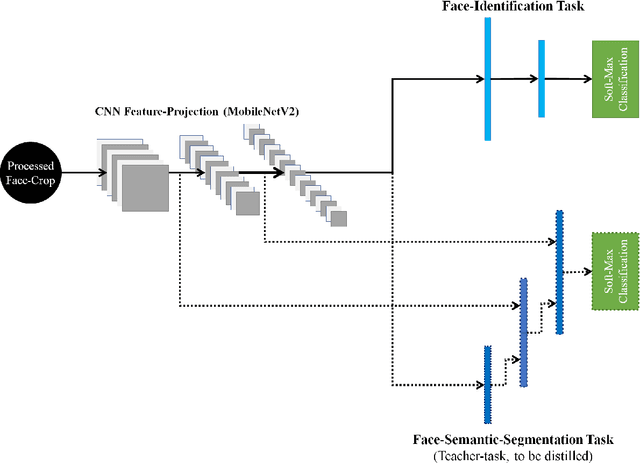

This paper demonstrates a novel approach to improve face-recognition pose-invariance using semantic-segmentation features. The proposed Seg-Distilled-ID network jointly learns identification and semantic-segmentation tasks, where the segmentation task is then "distilled" (MobileNet encoder). Performance is benchmarked against three state-of-the-art encoders on a publicly available data-set emphasizing head-pose variations. Experimental evaluations show the Seg-Distilled-ID network shows notable robustness benefits, achieving 99.9% test-accuracy in comparison to 81.6% on ResNet-101, 96.1% on VGG-19 and 96.3% on InceptionV3. This is achieved using approximately one-tenth of the top encoder's inference parameters. These results demonstrate distilling semantic-segmentation features can efficiently address face-recognition pose-invariance.