 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAR: AI-Powered Speed-of-Light Performance Analysis
Jun 24, 2026How fast could a deep-learning model run on target hardware, and how far is today's implementation from that limit? These questions are central to software, hardware, and algorithm optimizations. Speed-of-Light (SOL) analysis answers them by computing a workload's theoretical minimum execution time on a given architecture. Yet deriving SOL bounds remains manual, error-prone, and disconnected from rapid model development. To close this gap, we introduce SOLAR, a framework that automatically derives validated SOL bounds from PyTorch and JAX source code. SOLAR leverages both generative and deterministic components in its flow: an LLM frontend translates any source programs into an executable Affine Loop IR, validated by output comparison; a deterministic flow lifts the IR into an einsum graph; and an analytical backend computes unfused, fused, and cache-aware SOL bounds. SOLAR provides comprehensive operator and language coverage, produces validated bounds with zero observed SOL violations, and offers multi-fidelity analysis that tightens bounds and surfaces optimization insights. We evaluate SOLAR across KernelBench, JAX/Flax models, and robotics workloads. These experiments demonstrate four use cases: headroom analysis at multiple fidelity levels, identifying optimization opportunities, cross-platform exploration, and inverse-roofline hardware provisioning.
AVO: Agentic Variation Operators for Autonomous Evolutionary Search
Mar 25, 2026Agentic Variation Operators (AVO) are a new family of evolutionary variation operators that replace the fixed mutation, crossover, and hand-designed heuristics of classical evolutionary search with autonomous coding agents. Rather than confining a language model to candidate generation within a prescribed pipeline, AVO instantiates variation as a self-directed agent loop that can consult the current lineage, a domain-specific knowledge base, and execution feedback to propose, repair, critique, and verify implementation edits. We evaluate AVO on attention, among the most aggressively optimized kernel targets in AI, on NVIDIA Blackwell (B200) GPUs. Over 7 days of continuous autonomous evolution on multi-head attention, AVO discovers kernels that outperform cuDNN by up to 3.5% and FlashAttention-4 by up to 10.5% across the evaluated configurations. The discovered optimizations transfer readily to grouped-query attention, requiring only 30 minutes of additional autonomous adaptation and yielding gains of up to 7.0% over cuDNN and 9.3% over FlashAttention-4. Together, these results show that agentic variation operators move beyond prior LLM-in-the-loop evolutionary pipelines by elevating the agent from candidate generator to variation operator, and can discover performance-critical micro-architectural optimizations that produce kernels surpassing state-of-the-art expert-engineered attention implementations on today's most advanced GPU hardware.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
Le-DETR: Revisiting Real-Time Detection Transformer with Efficient Encoder Design
Feb 24, 2026Real-time object detection is crucial for real-world applications as it requires high accuracy with low latency. While Detection Transformers (DETR) have demonstrated significant performance improvements, current real-time DETR models are challenging to reproduce from scratch due to excessive pre-training overheads on the backbone, constraining research advancements by hindering the exploration of novel backbone architectures. In this paper, we want to show that by using general good design, it is possible to have \textbf{high performance} with \textbf{low pre-training cost}. After a thorough study of the backbone architecture, we propose EfficientNAT at various scales, which incorporates modern efficient convolution and local attention mechanisms. Moreover, we re-design the hybrid encoder with local attention, significantly enhancing both performance and inference speed. Based on these advancements, we present Le-DETR (\textbf{L}ow-cost and \textbf{E}fficient \textbf{DE}tection \textbf{TR}ansformer), which achieves a new \textbf{SOTA} in real-time detection using only ImageNet1K and COCO2017 training datasets, saving about 80\% images in pre-training stage compared with previous methods. We demonstrate that with well-designed, real-time DETR models can achieve strong performance without the need for complex and computationally expensive pretraining. Extensive experiments show that Le-DETR-M/L/X achieves \textbf{52.9/54.3/55.1 mAP} on COCO Val2017 with \textbf{4.45/5.01/6.68 ms} on an RTX4090. It surpasses YOLOv12-L/X by \textbf{+0.6/-0.1 mAP} while achieving similar speed and \textbf{+20\%} speedup. Compared with DEIM-D-FINE, Le-DETR-M achieves \textbf{+0.2 mAP} with slightly faster inference, and surpasses DEIM-D-FINE-L by \textbf{+0.4 mAP} with only \textbf{0.4 ms} additional latency. Code and weights will be open-sourced.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025



We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
SenTest: Evaluating Robustness of Sentence Encoders
Nov 29, 2023
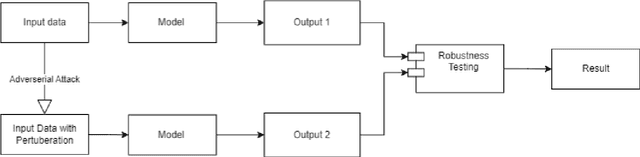


Contrastive learning has proven to be an effective method for pre-training models using weakly labeled data in the vision domain. Sentence transformers are the NLP counterparts to this architecture, and have been growing in popularity due to their rich and effective sentence representations. Having effective sentence representations is paramount in multiple tasks, such as information retrieval, retrieval augmented generation (RAG), and sentence comparison. Keeping in mind the deployability factor of transformers, evaluating the robustness of sentence transformers is of utmost importance. This work focuses on evaluating the robustness of the sentence encoders. We employ several adversarial attacks to evaluate its robustness. This system uses character-level attacks in the form of random character substitution, word-level attacks in the form of synonym replacement, and sentence-level attacks in the form of intra-sentence word order shuffling. The results of the experiments strongly undermine the robustness of sentence encoders. The models produce significantly different predictions as well as embeddings on perturbed datasets. The accuracy of the models can fall up to 15 percent on perturbed datasets as compared to unperturbed datasets. Furthermore, the experiments demonstrate that these embeddings does capture the semantic and syntactic structure (sentence order) of sentences. However, existing supervised classification strategies fail to leverage this information, and merely function as n-gram detectors.
Task Arithmetic with LoRA for Continual Learning
Nov 04, 2023Continual learning refers to the problem where the training data is available in sequential chunks, termed "tasks". The majority of progress in continual learning has been stunted by the problem of catastrophic forgetting, which is caused by sequential training of the model on streams of data. Moreover, it becomes computationally expensive to sequentially train large models multiple times. To mitigate both of these problems at once, we propose a novel method to continually train transformer-based vision models using low-rank adaptation and task arithmetic. Our method completely bypasses the problem of catastrophic forgetting, as well as reducing the computational requirement for training models on each task. When aided with a small memory of 10 samples per class, our method achieves performance close to full-set finetuning. We present rigorous ablations to support the prowess of our method.
My Boli: Code-mixed Marathi-English Corpora, Pretrained Language Models and Evaluation Benchmarks
Jun 24, 2023



The research on code-mixed data is limited due to the unavailability of dedicated code-mixed datasets and pre-trained language models. In this work, we focus on the low-resource Indian language Marathi which lacks any prior work in code-mixing. We present L3Cube-MeCorpus, a large code-mixed Marathi-English (Mr-En) corpus with 5 million tweets for pretraining. We also release L3Cube-MeBERT and MeRoBERTa, code-mixed BERT-based transformer models pre-trained on MeCorpus. Furthermore, for benchmarking, we present three supervised datasets MeHate, MeSent, and MeLID for downstream tasks like code-mixed Mr-En hate speech detection, sentiment analysis, and language identification respectively. These evaluation datasets individually consist of manually annotated \url{~}12,000 Marathi-English code-mixed tweets. Ablations show that the models trained on this novel corpus significantly outperform the existing state-of-the-art BERT models. This is the first work that presents artifacts for code-mixed Marathi research. All datasets and models are publicly released at https://github.com/l3cube-pune/MarathiNLP .
Two-stage Pipeline for Multilingual Dialect Detection
Mar 06, 2023Dialect Identification is a crucial task for localizing various Large Language Models. This paper outlines our approach to the VarDial 2023 shared task. Here we have to identify three or two dialects from three languages each which results in a 9-way classification for Track-1 and 6-way classification for Track-2 respectively. Our proposed approach consists of a two-stage system and outperforms other participants' systems and previous works in this domain. We achieve a score of 58.54% for Track-1 and 85.61% for Track-2. Our codebase is available publicly (https://github.com/ankit-vaidya19/EACL_VarDial2023).