 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAikyam: A Video Conferencing Utility for Deaf and Dumb
Dec 10, 2023With the advent of the pandemic, the use of video conferencing platforms as a means of communication has greatly increased and with it, so have the remote opportunities. The deaf and dumb have traditionally faced several issues in communication, but now the effect is felt more severely. This paper proposes an all-encompassing video conferencing utility that can be used with existing video conferencing platforms to address these issues. Appropriate semantically correct sentences are generated from the signer's gestures which would be interpreted by the system. Along with an audio to emit this sentence, the user's feed is also used to annotate the sentence. This can be viewed by all participants, thus aiding smooth communication with all parties involved. This utility utilizes a simple LSTM model for classification of gestures. The sentences are constructed by a t5 based model. In order to achieve the required data flow, a virtual camera is used.
Study and Survey on Gesture Recognition Systems
Dec 01, 2023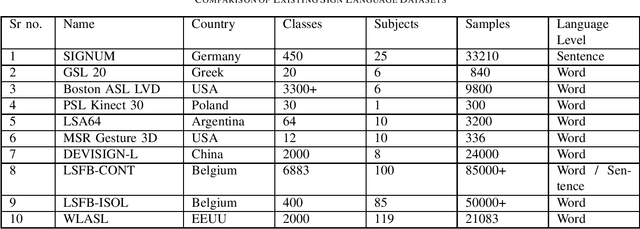

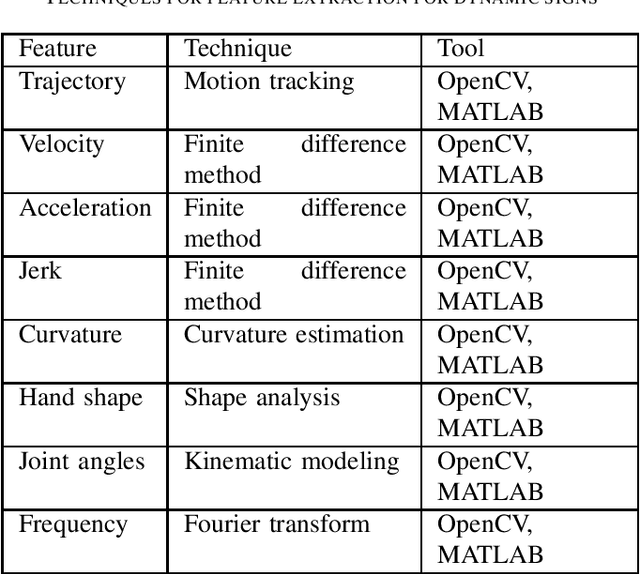
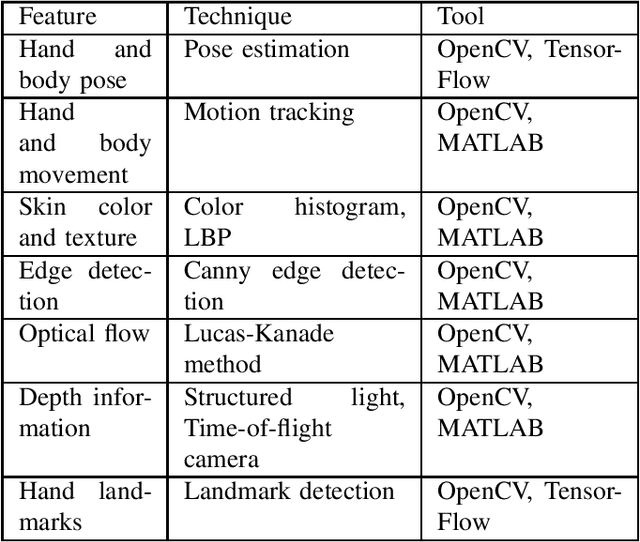
In recent years, there has been a considerable amount of research in the Gesture Recognition domain, mainly owing to the technological advancements in Computer Vision. Various new applications have been conceptualised and developed in this field. This paper discusses the implementation of gesture recognition systems in multiple sectors such as gaming, healthcare, home appliances, industrial robots, and virtual reality. Different methodologies for capturing gestures are compared and contrasted throughout this survey. Various data sources and data acquisition techniques have been discussed. The role of gestures in sign language has been studied and existing approaches have been reviewed. Common challenges faced while building gesture recognition systems have also been explored.
Task Arithmetic with LoRA for Continual Learning
Nov 04, 2023Continual learning refers to the problem where the training data is available in sequential chunks, termed "tasks". The majority of progress in continual learning has been stunted by the problem of catastrophic forgetting, which is caused by sequential training of the model on streams of data. Moreover, it becomes computationally expensive to sequentially train large models multiple times. To mitigate both of these problems at once, we propose a novel method to continually train transformer-based vision models using low-rank adaptation and task arithmetic. Our method completely bypasses the problem of catastrophic forgetting, as well as reducing the computational requirement for training models on each task. When aided with a small memory of 10 samples per class, our method achieves performance close to full-set finetuning. We present rigorous ablations to support the prowess of our method.
Suggesting Relevant Questions for a Query Using Statistical Natural Language Processing Technique
Apr 26, 2022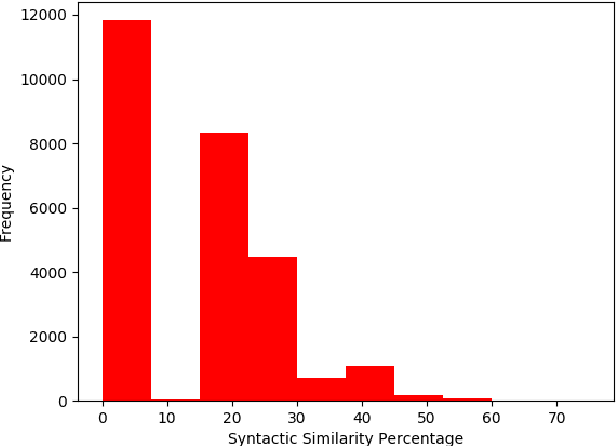
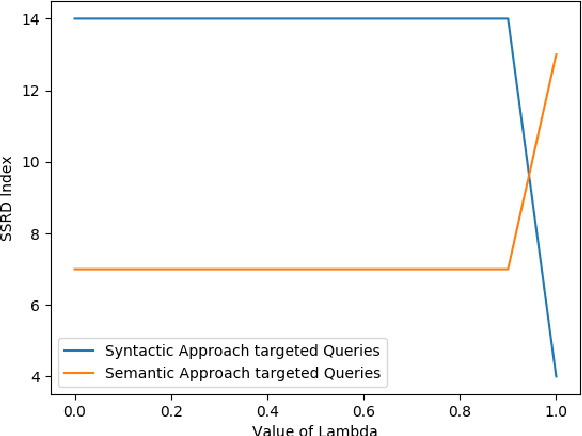
Suggesting similar questions for a user query has many applications ranging from reducing search time of users on e-commerce websites, training of employees in companies to holistic learning for students. The use of Natural Language Processing techniques for suggesting similar questions is prevalent over the existing architecture. Mainly two approaches are studied for finding text similarity namely syntactic and semantic, however each has its draw-backs and fail to provide the desired outcome. In this article, a self-learning combined approach is proposed for determining textual similarity that introduces a robust weighted syntactic and semantic similarity index for determining similar questions from a predetermined database, this approach learns the optimal combination of the mentioned approaches for a database under consideration. Comprehensive analysis has been carried out to justify the efficiency and efficacy of the proposed approach over the existing literature.
Animation of 3D Human Model Using Markerless Motion Capture Applied To Sports
Feb 11, 2014



Markerless motion capture is an active research in 3D virtualization. In proposed work we presented a system for markerless motion capture for 3D human character animation, paper presents a survey on motion and skeleton tracking techniques which are developed or are under development. The paper proposed a method to transform the motion of a performer to a 3D human character (model), the 3D human character performs similar movements as that of a performer in real time. In the proposed work, human model data will be captured by Kinect camera, processed data will be applied on 3D human model for animation. 3D human model is created using open source software (MakeHuman). Anticipated dataset for sport activity is considered as input which can be applied to any HCI application.