 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuggesting Relevant Questions for a Query Using Statistical Natural Language Processing Technique
Paper and Code
Apr 26, 2022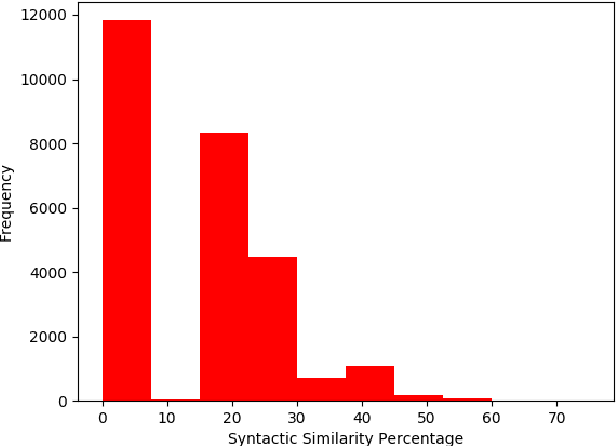
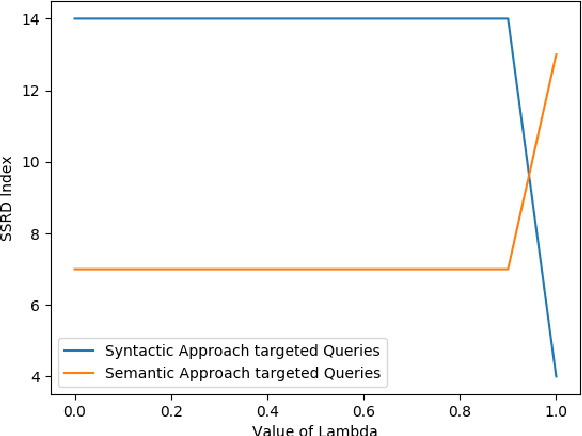
Suggesting similar questions for a user query has many applications ranging from reducing search time of users on e-commerce websites, training of employees in companies to holistic learning for students. The use of Natural Language Processing techniques for suggesting similar questions is prevalent over the existing architecture. Mainly two approaches are studied for finding text similarity namely syntactic and semantic, however each has its draw-backs and fail to provide the desired outcome. In this article, a self-learning combined approach is proposed for determining textual similarity that introduces a robust weighted syntactic and semantic similarity index for determining similar questions from a predetermined database, this approach learns the optimal combination of the mentioned approaches for a database under consideration. Comprehensive analysis has been carried out to justify the efficiency and efficacy of the proposed approach over the existing literature.