 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConverting Epics/Stories into Pseudocode using Transformers
Dec 08, 2023The conversion of user epics or stories into their appropriate representation in pseudocode or code is a time-consuming task, which can take up a large portion of the time in an industrial project. With this research paper, we aim to present a methodology to generate pseudocode from a given agile user story of small functionalities so as to reduce the overall time spent on the industrial project. Pseudocode is a programming language agnostic representation of the steps involved in a computer program, which can be easily converted into any programming language. Leveraging the potential of Natural Language Processing, we want to simplify the development process in organizations that use the Agile Model of Software Development. We present a methodology to convert a problem described in the English language into pseudocode. This methodology divides the Text to Pseudocode conversion task into two stages or subtasks, each of which is treated like an individual machine translation task. Stage 1 is Text to Code Conversion and Stage 2 is Code to Pseudocode Conversion. We find that the CodeT5 model gives the best results in terms of BLEU score when trained separately on the two subtasks mentioned above. BLEU score is a metric that is used to measure the similarity between a machine-translated text and a set of reference translations.
Empathy and Distress Detection using Ensembles of Transformer Models
Dec 05, 2023This paper presents our approach for the WASSA 2023 Empathy, Emotion and Personality Shared Task. Empathy and distress are human feelings that are implicitly expressed in natural discourses. Empathy and distress detection are crucial challenges in Natural Language Processing that can aid our understanding of conversations. The provided dataset consists of several long-text examples in the English language, with each example associated with a numeric score for empathy and distress. We experiment with several BERT-based models as a part of our approach. We also try various ensemble methods. Our final submission has a Pearson's r score of 0.346, placing us third in the empathy and distress detection subtask.
Mavericks at BLP-2023 Task 1: Ensemble-based Approach Using Language Models for Violence Inciting Text Detection
Nov 30, 2023This paper presents our work for the Violence Inciting Text Detection shared task in the First Workshop on Bangla Language Processing. Social media has accelerated the propagation of hate and violence-inciting speech in society. It is essential to develop efficient mechanisms to detect and curb the propagation of such texts. The problem of detecting violence-inciting texts is further exacerbated in low-resource settings due to sparse research and less data. The data provided in the shared task consists of texts in the Bangla language, where each example is classified into one of the three categories defined based on the types of violence-inciting texts. We try and evaluate several BERT-based models, and then use an ensemble of the models as our final submission. Our submission is ranked 10th in the final leaderboard of the shared task with a macro F1 score of 0.737.
Suggesting Relevant Questions for a Query Using Statistical Natural Language Processing Technique
Apr 26, 2022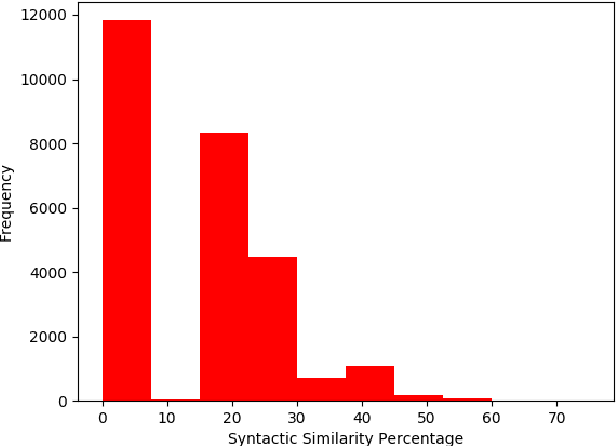
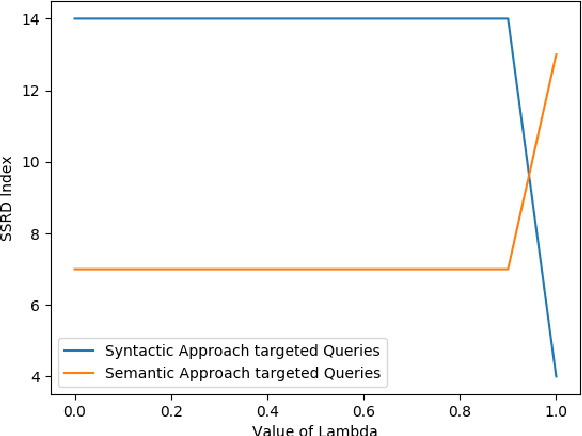
Suggesting similar questions for a user query has many applications ranging from reducing search time of users on e-commerce websites, training of employees in companies to holistic learning for students. The use of Natural Language Processing techniques for suggesting similar questions is prevalent over the existing architecture. Mainly two approaches are studied for finding text similarity namely syntactic and semantic, however each has its draw-backs and fail to provide the desired outcome. In this article, a self-learning combined approach is proposed for determining textual similarity that introduces a robust weighted syntactic and semantic similarity index for determining similar questions from a predetermined database, this approach learns the optimal combination of the mentioned approaches for a database under consideration. Comprehensive analysis has been carried out to justify the efficiency and efficacy of the proposed approach over the existing literature.