 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndiText Boost: Text Augmentation for Low Resource India Languages
Jan 23, 2024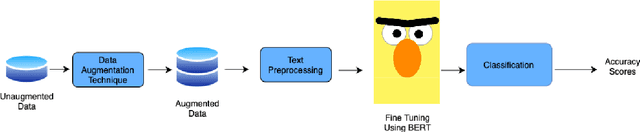
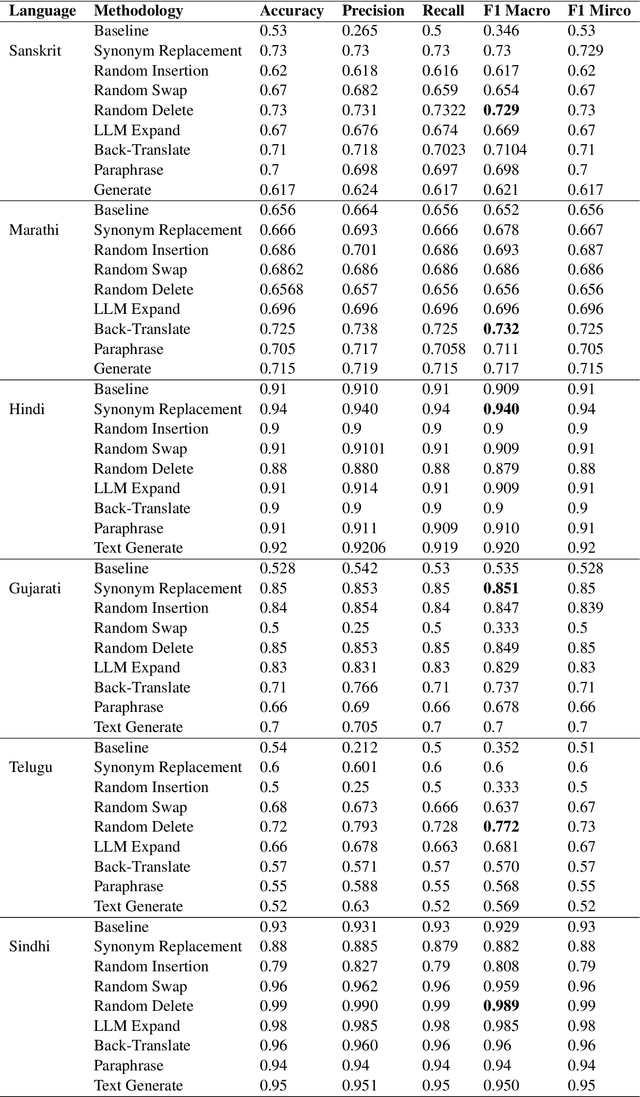
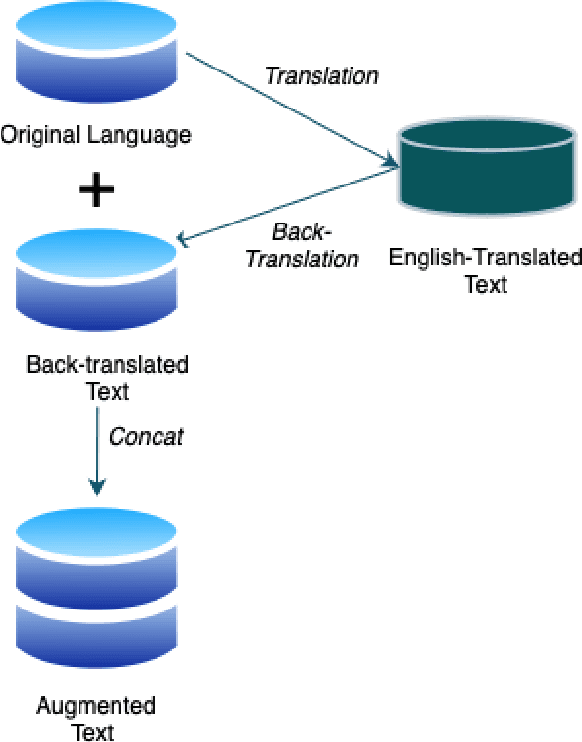
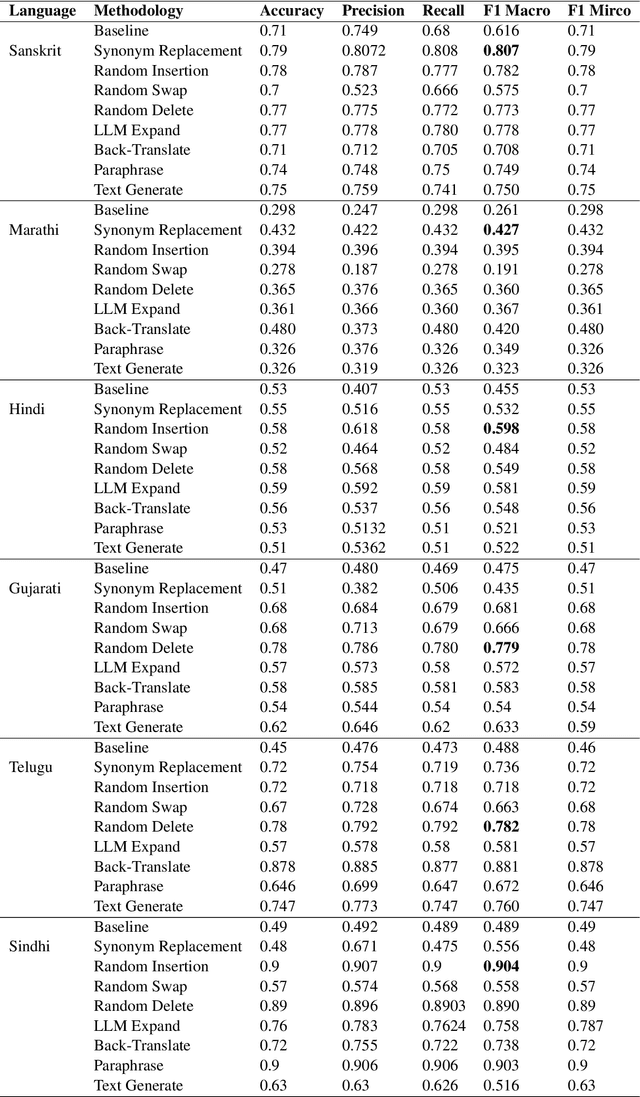
Text Augmentation is an important task for low-resource languages. It helps deal with the problem of data scarcity. A data augmentation strategy is used to deal with the problem of data scarcity. Through the years, much work has been done on data augmentation for the English language. In contrast, very less work has been done on Indian languages. This is contrary to the fact that data augmentation is used to deal with data scarcity. In this work, we focus on implementing techniques like Easy Data Augmentation, Back Translation, Paraphrasing, Text Generation using LLMs, and Text Expansion using LLMs for text classification on different languages. We focus on 6 Indian languages namely: Sindhi, Marathi, Hindi, Gujarati, Telugu, and Sanskrit. According to our knowledge, no such work exists for text augmentation on Indian languages. We carry out binary as well as multi-class text classification to make our results more comparable. We get surprising results as basic data augmentation techniques surpass LLMs.
Breaking Language Barriers: A Question Answering Dataset for Hindi and Marathi
Sep 01, 2023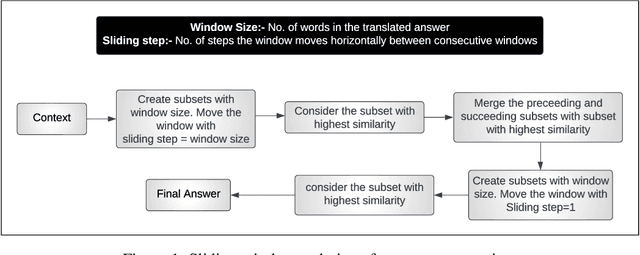
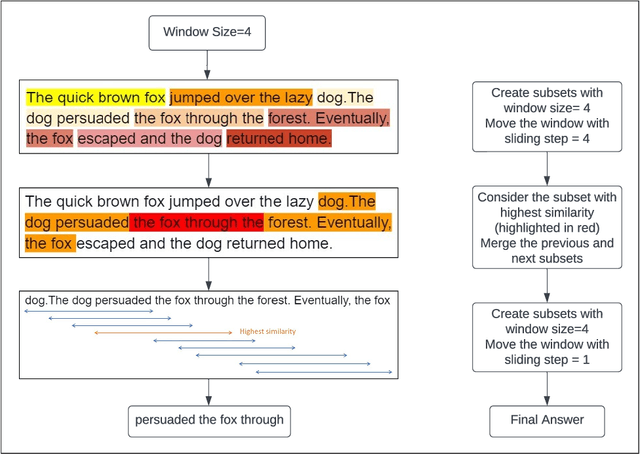
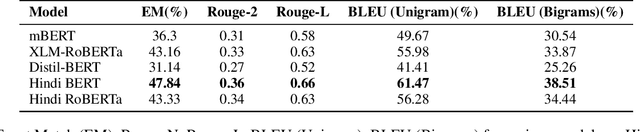
The recent advances in deep-learning have led to the development of highly sophisticated systems with an unquenchable appetite for data. On the other hand, building good deep-learning models for low-resource languages remains a challenging task. This paper focuses on developing a Question Answering dataset for two such languages- Hindi and Marathi. Despite Hindi being the 3rd most spoken language worldwide, with 345 million speakers, and Marathi being the 11th most spoken language globally, with 83.2 million speakers, both languages face limited resources for building efficient Question Answering systems. To tackle the challenge of data scarcity, we have developed a novel approach for translating the SQuAD 2.0 dataset into Hindi and Marathi. We release the largest Question-Answering dataset available for these languages, with each dataset containing 28,000 samples. We evaluate the dataset on various architectures and release the best-performing models for both Hindi and Marathi, which will facilitate further research in these languages. Leveraging similarity tools, our method holds the potential to create datasets in diverse languages, thereby enhancing the understanding of natural language across varied linguistic contexts. Our fine-tuned models, code, and dataset will be made publicly available.
Enhancing Low Resource NER Using Assisting Language And Transfer Learning
Jun 10, 2023
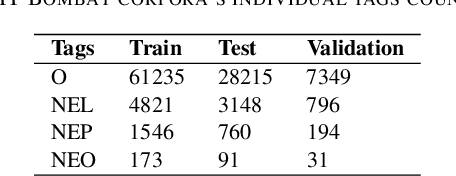
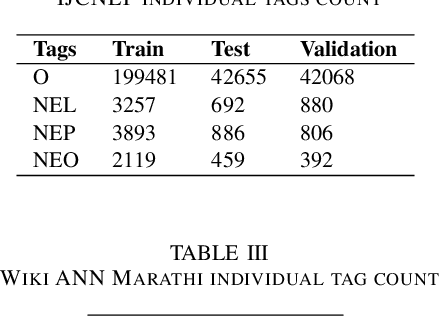
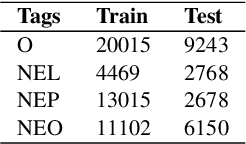
Named Entity Recognition (NER) is a fundamental task in NLP that is used to locate the key information in text and is primarily applied in conversational and search systems. In commercial applications, NER or comparable slot-filling methods have been widely deployed for popular languages. NER is used in applications such as human resources, customer service, search engines, content classification, and academia. In this paper, we draw focus on identifying name entities for low-resource Indian languages that are closely related, like Hindi and Marathi. We use various adaptations of BERT such as baseBERT, AlBERT, and RoBERTa to train a supervised NER model. We also compare multilingual models with monolingual models and establish a baseline. In this work, we show the assisting capabilities of the Hindi and Marathi languages for the NER task. We show that models trained using multiple languages perform better than a single language. However, we also observe that blind mixing of all datasets doesn't necessarily provide improvements and data selection methods may be required.
Suggesting Relevant Questions for a Query Using Statistical Natural Language Processing Technique
Apr 26, 2022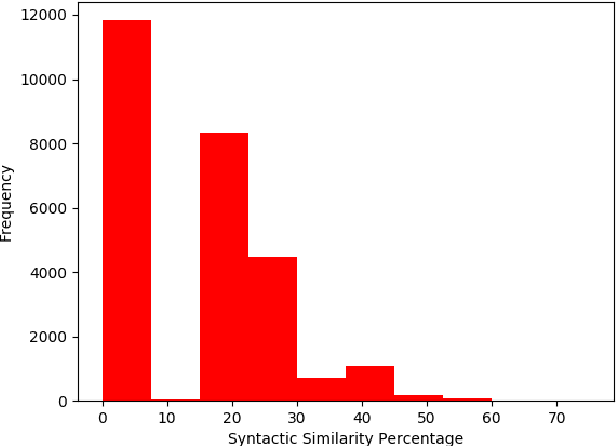
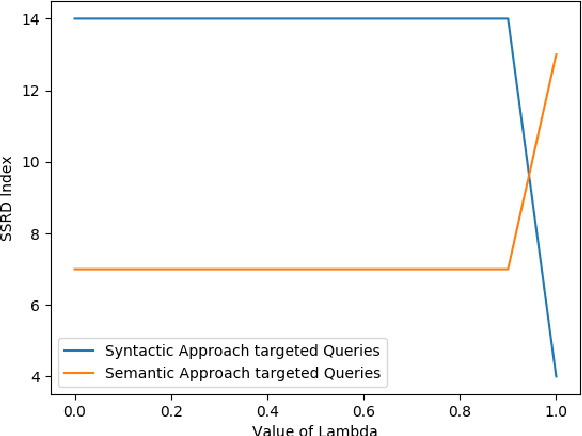
Suggesting similar questions for a user query has many applications ranging from reducing search time of users on e-commerce websites, training of employees in companies to holistic learning for students. The use of Natural Language Processing techniques for suggesting similar questions is prevalent over the existing architecture. Mainly two approaches are studied for finding text similarity namely syntactic and semantic, however each has its draw-backs and fail to provide the desired outcome. In this article, a self-learning combined approach is proposed for determining textual similarity that introduces a robust weighted syntactic and semantic similarity index for determining similar questions from a predetermined database, this approach learns the optimal combination of the mentioned approaches for a database under consideration. Comprehensive analysis has been carried out to justify the efficiency and efficacy of the proposed approach over the existing literature.
PICT@DravidianLangTech-ACL2022: Neural Machine Translation On Dravidian Languages
Apr 19, 2022
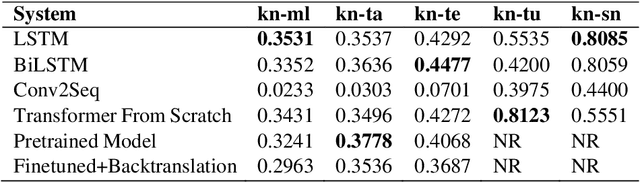


This paper presents a summary of the findings that we obtained based on the shared task on machine translation of Dravidian languages. We stood first in three of the five sub-tasks which were assigned to us for the main shared task. We carried out neural machine translation for the following five language pairs: Kannada to Tamil, Kannada to Telugu, Kannada to Malayalam, Kannada to Sanskrit, and Kannada to Tulu. The datasets for each of the five language pairs were used to train various translation models, including Seq2Seq models such as LSTM, bidirectional LSTM, Conv2Seq, and training state-of-the-art as transformers from scratch, and fine-tuning already pre-trained models. For some models involving monolingual corpora, we implemented backtranslation as well. These models' accuracy was later tested with a part of the same dataset using BLEU score as an evaluation metric.
Optimize_Prime@DravidianLangTech-ACL2022: Abusive Comment Detection in Tamil
Apr 19, 2022
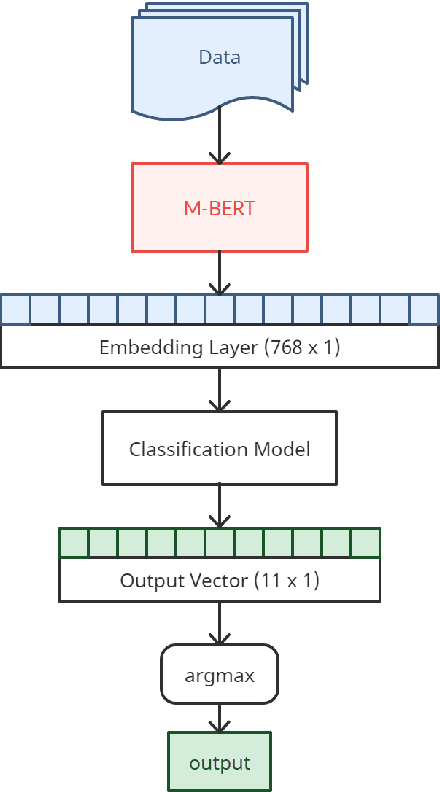
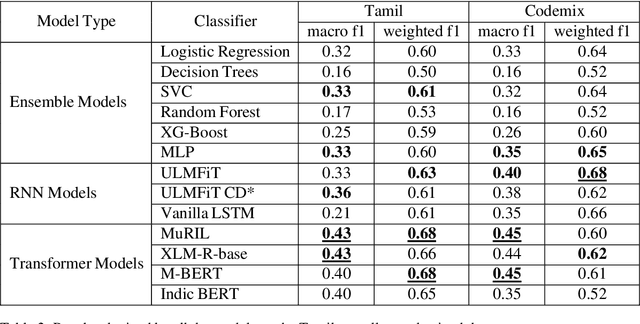
This paper tries to address the problem of abusive comment detection in low-resource indic languages. Abusive comments are statements that are offensive to a person or a group of people. These comments are targeted toward individuals belonging to specific ethnicities, genders, caste, race, sexuality, etc. Abusive Comment Detection is a significant problem, especially with the recent rise in social media users. This paper presents the approach used by our team - Optimize_Prime, in the ACL 2022 shared task "Abusive Comment Detection in Tamil." This task detects and classifies YouTube comments in Tamil and Tamil- English Codemixed format into multiple categories. We have used three methods to optimize our results: Ensemble models, Recurrent Neural Networks, and Transformers. In the Tamil data, MuRIL and XLM-RoBERTA were our best performing models with a macro-averaged f1 score of 0.43. Furthermore, for the Code-mixed data, MuRIL and M-BERT provided sub-lime results, with a macro-averaged f1 score of 0.45.
Optimize_Prime@DravidianLangTech-ACL2022: Emotion Analysis in Tamil
Apr 19, 2022
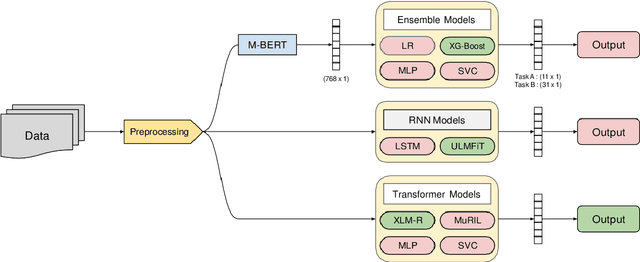
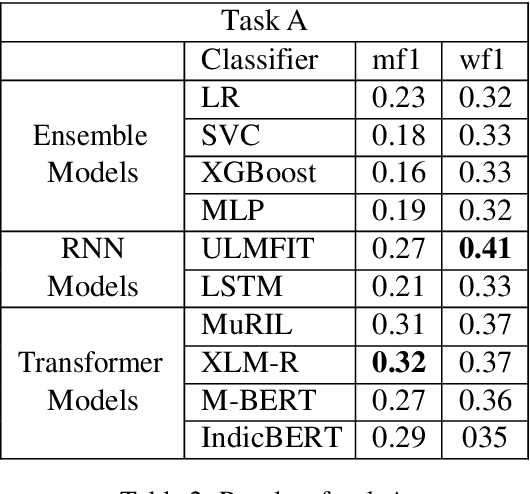
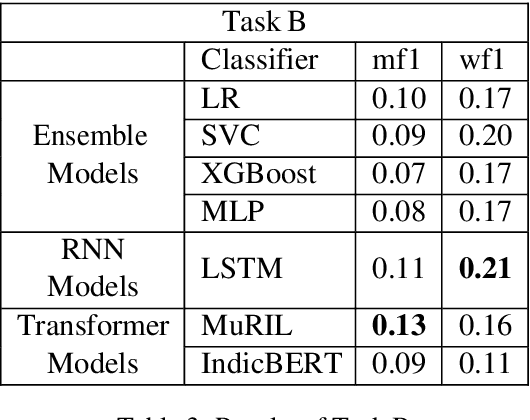
This paper aims to perform an emotion analysis of social media comments in Tamil. Emotion analysis is the process of identifying the emotional context of the text. In this paper, we present the findings obtained by Team Optimize_Prime in the ACL 2022 shared task "Emotion Analysis in Tamil." The task aimed to classify social media comments into categories of emotion like Joy, Anger, Trust, Disgust, etc. The task was further divided into two subtasks, one with 11 broad categories of emotions and the other with 31 specific categories of emotion. We implemented three different approaches to tackle this problem: transformer-based models, Recurrent Neural Networks (RNNs), and Ensemble models. XLM-RoBERTa performed the best on the first task with a macro-averaged f1 score of 0.27, while MuRIL provided the best results on the second task with a macro-averaged f1 score of 0.13.
L3Cube-MahaNER: A Marathi Named Entity Recognition Dataset and BERT models
Apr 12, 2022
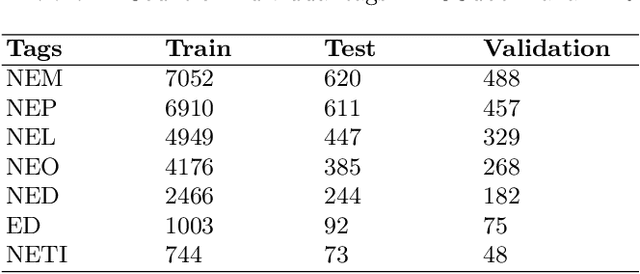
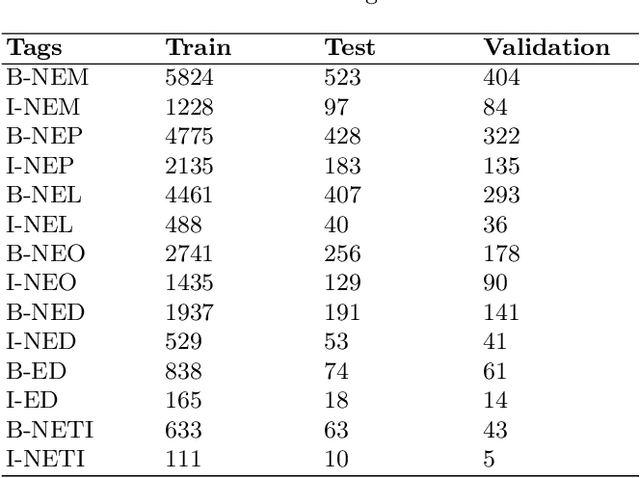
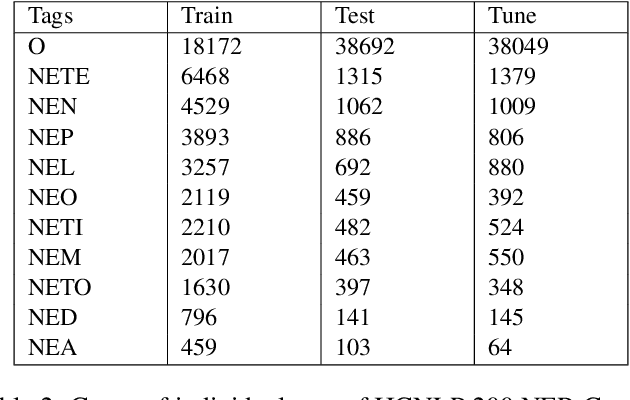
Named Entity Recognition (NER) is a basic NLP task and finds major applications in conversational and search systems. It helps us identify key entities in a sentence used for the downstream application. NER or similar slot filling systems for popular languages have been heavily used in commercial applications. In this work, we focus on Marathi, an Indian language, spoken prominently by the people of Maharashtra state. Marathi is a low resource language and still lacks useful NER resources. We present L3Cube-MahaNER, the first major gold standard named entity recognition dataset in Marathi. We also describe the manual annotation guidelines followed during the process. In the end, we benchmark the dataset on different CNN, LSTM, and Transformer based models like mBERT, XLM-RoBERTa, IndicBERT, MahaBERT, etc. The MahaBERT provides the best performance among all the models. The data and models are available at https://github.com/l3cube-pune/MarathiNLP .
Mono vs Multilingual BERT: A Case Study in Hindi and Marathi Named Entity Recognition
Mar 24, 2022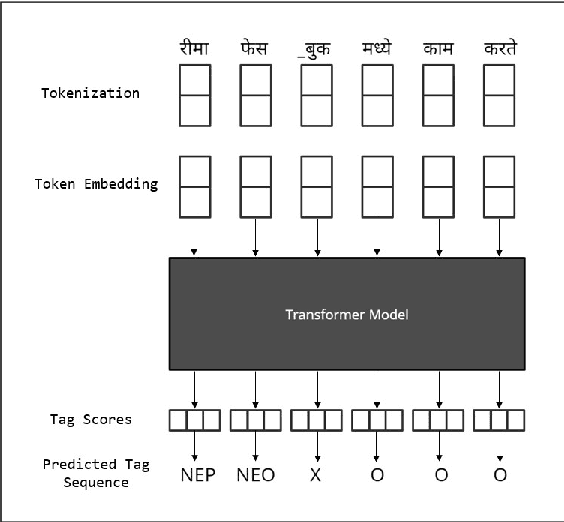

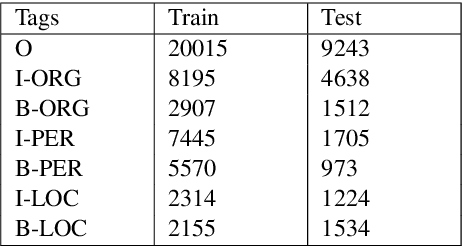
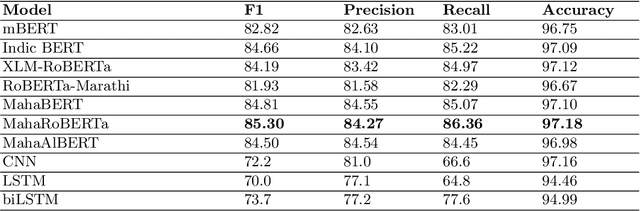
Named entity recognition (NER) is the process of recognising and classifying important information (entities) in text. Proper nouns, such as a person's name, an organization's name, or a location's name, are examples of entities. The NER is one of the important modules in applications like human resources, customer support, search engines, content classification, and academia. In this work, we consider NER for low-resource Indian languages like Hindi and Marathi. The transformer-based models have been widely used for NER tasks. We consider different variations of BERT like base-BERT, RoBERTa, and AlBERT and benchmark them on publicly available Hindi and Marathi NER datasets. We provide an exhaustive comparison of different monolingual and multilingual transformer-based models and establish simple baselines currently missing in the literature. We show that the monolingual MahaRoBERTa model performs the best for Marathi NER whereas the multilingual XLM-RoBERTa performs the best for Hindi NER. We also perform cross-language evaluation and present mixed observations.
Analyzing Architectures for Neural Machine Translation Using Low Computational Resources
Nov 06, 2021
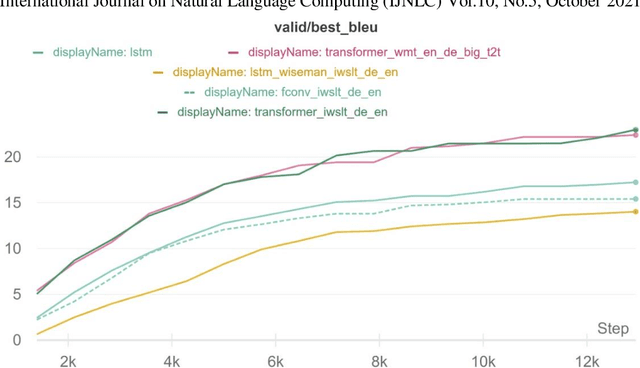
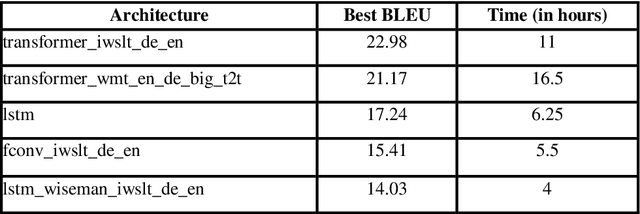
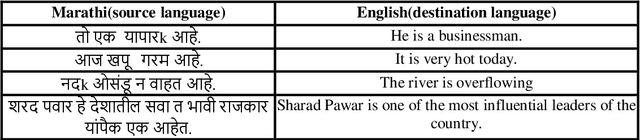
With the recent developments in the field of Natural Language Processing, there has been a rise in the use of different architectures for Neural Machine Translation. Transformer architectures are used to achieve state-of-the-art accuracy, but they are very computationally expensive to train. Everyone cannot have such setups consisting of high-end GPUs and other resources. We train our models on low computational resources and investigate the results. As expected, transformers outperformed other architectures, but there were some surprising results. Transformers consisting of more encoders and decoders took more time to train but had fewer BLEU scores. LSTM performed well in the experiment and took comparatively less time to train than transformers, making it suitable to use in situations having time constraints.