 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenTest: Evaluating Robustness of Sentence Encoders
Nov 29, 2023
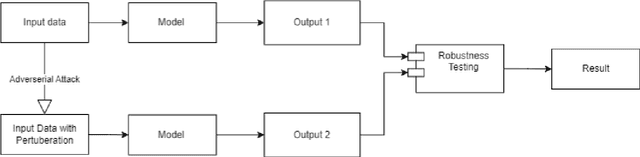


Contrastive learning has proven to be an effective method for pre-training models using weakly labeled data in the vision domain. Sentence transformers are the NLP counterparts to this architecture, and have been growing in popularity due to their rich and effective sentence representations. Having effective sentence representations is paramount in multiple tasks, such as information retrieval, retrieval augmented generation (RAG), and sentence comparison. Keeping in mind the deployability factor of transformers, evaluating the robustness of sentence transformers is of utmost importance. This work focuses on evaluating the robustness of the sentence encoders. We employ several adversarial attacks to evaluate its robustness. This system uses character-level attacks in the form of random character substitution, word-level attacks in the form of synonym replacement, and sentence-level attacks in the form of intra-sentence word order shuffling. The results of the experiments strongly undermine the robustness of sentence encoders. The models produce significantly different predictions as well as embeddings on perturbed datasets. The accuracy of the models can fall up to 15 percent on perturbed datasets as compared to unperturbed datasets. Furthermore, the experiments demonstrate that these embeddings does capture the semantic and syntactic structure (sentence order) of sentences. However, existing supervised classification strategies fail to leverage this information, and merely function as n-gram detectors.
My Boli: Code-mixed Marathi-English Corpora, Pretrained Language Models and Evaluation Benchmarks
Jun 24, 2023The research on code-mixed data is limited due to the unavailability of dedicated code-mixed datasets and pre-trained language models. In this work, we focus on the low-resource Indian language Marathi which lacks any prior work in code-mixing. We present L3Cube-MeCorpus, a large code-mixed Marathi-English (Mr-En) corpus with 5 million tweets for pretraining. We also release L3Cube-MeBERT and MeRoBERTa, code-mixed BERT-based transformer models pre-trained on MeCorpus. Furthermore, for benchmarking, we present three supervised datasets MeHate, MeSent, and MeLID for downstream tasks like code-mixed Mr-En hate speech detection, sentiment analysis, and language identification respectively. These evaluation datasets individually consist of manually annotated \url{~}12,000 Marathi-English code-mixed tweets. Ablations show that the models trained on this novel corpus significantly outperform the existing state-of-the-art BERT models. This is the first work that presents artifacts for code-mixed Marathi research. All datasets and models are publicly released at https://github.com/l3cube-pune/MarathiNLP .
A Twitter BERT Approach for Offensive Language Detection in Marathi
Dec 20, 2022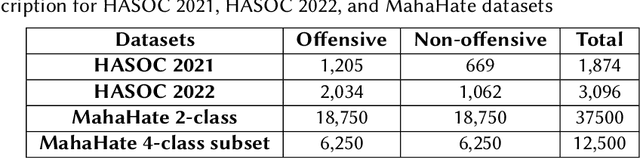
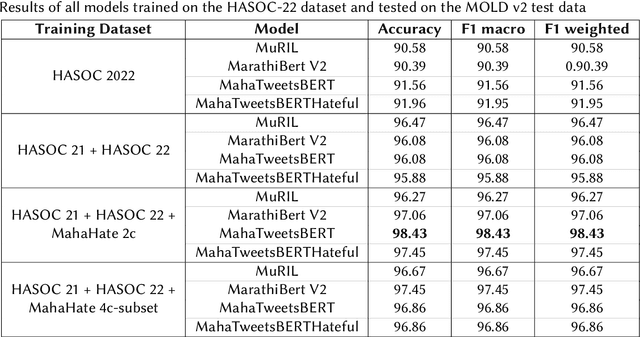
Automated offensive language detection is essential in combating the spread of hate speech, particularly in social media. This paper describes our work on Offensive Language Identification in low resource Indic language Marathi. The problem is formulated as a text classification task to identify a tweet as offensive or non-offensive. We evaluate different mono-lingual and multi-lingual BERT models on this classification task, focusing on BERT models pre-trained with social media datasets. We compare the performance of MuRIL, MahaTweetBERT, MahaTweetBERT-Hateful, and MahaBERT on the HASOC 2022 test set. We also explore external data augmentation from other existing Marathi hate speech corpus HASOC 2021 and L3Cube-MahaHate. The MahaTweetBERT, a BERT model, pre-trained on Marathi tweets when fine-tuned on the combined dataset (HASOC 2021 + HASOC 2022 + MahaHate), outperforms all models with an F1 score of 98.43 on the HASOC 2022 test set. With this, we also provide a new state-of-the-art result on HASOC 2022 / MOLD v2 test set.
Spread Love Not Hate: Undermining the Importance of Hateful Pre-training for Hate Speech Detection
Oct 09, 2022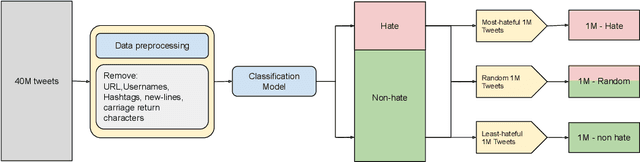
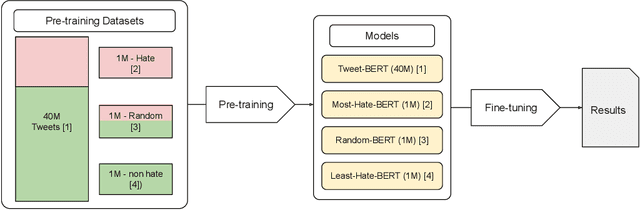
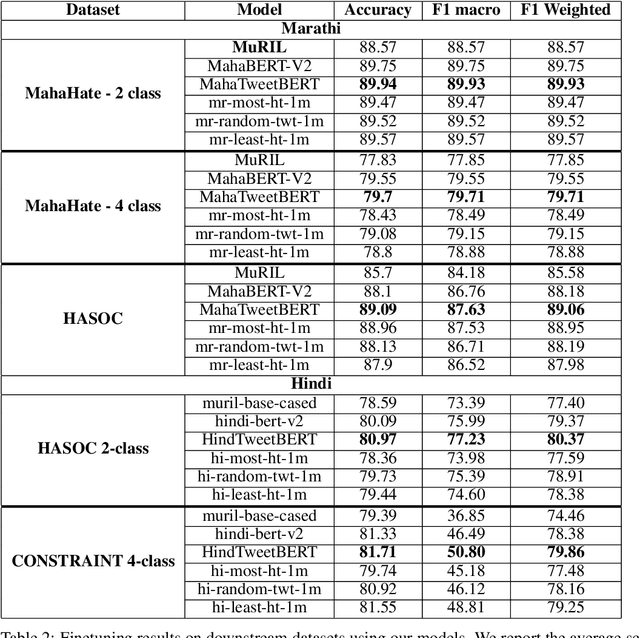

Pre-training large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. Although this method has proven to be effective for many domains, it might not always provide desirable benefits. In this paper we study the effects of hateful pre-training on low resource hate speech classification tasks. While previous studies on English language have emphasized its importance, we aim to to augment their observations with some non-obvious insights. We evaluate different variations of tweet based BERT models pre-trained on hateful, non-hateful and mixed subsets of 40M tweet dataset. This evaluation is carried for Indian languages Hindi and Marathi. This paper is an empirical evidence that hateful pre-training is not the best pre-training option for hate speech detection. We show that pre-training on non-hateful text from target domain provides similar or better results. Further, we introduce HindTweetBERT and MahaTweetBERT, the first publicly available BERT models pre-trained on Hindi and Marathi tweets respectively. We show that they provide state-of-the-art performance on hate speech classification tasks. We also release a gold hate speech evaluation benchmark HateEval-Hi and HateEval-Mr consisting of manually labeled 2000 tweets each.
Optimize_Prime@DravidianLangTech-ACL2022: Abusive Comment Detection in Tamil
Apr 19, 2022
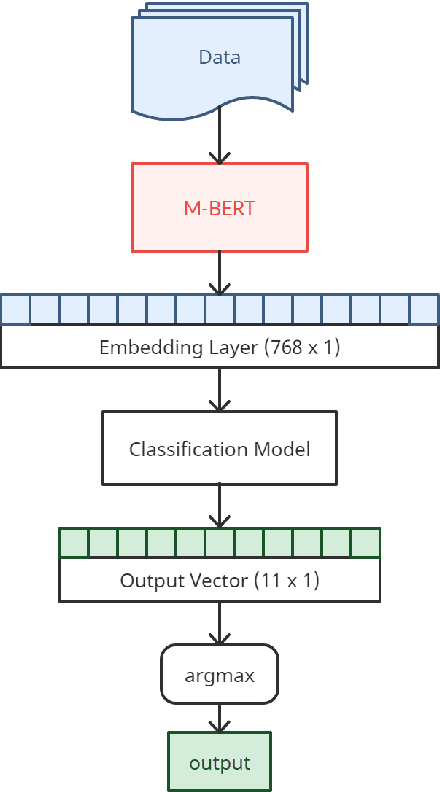
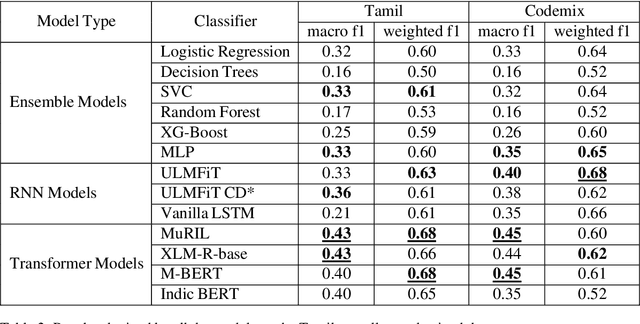
This paper tries to address the problem of abusive comment detection in low-resource indic languages. Abusive comments are statements that are offensive to a person or a group of people. These comments are targeted toward individuals belonging to specific ethnicities, genders, caste, race, sexuality, etc. Abusive Comment Detection is a significant problem, especially with the recent rise in social media users. This paper presents the approach used by our team - Optimize_Prime, in the ACL 2022 shared task "Abusive Comment Detection in Tamil." This task detects and classifies YouTube comments in Tamil and Tamil- English Codemixed format into multiple categories. We have used three methods to optimize our results: Ensemble models, Recurrent Neural Networks, and Transformers. In the Tamil data, MuRIL and XLM-RoBERTA were our best performing models with a macro-averaged f1 score of 0.43. Furthermore, for the Code-mixed data, MuRIL and M-BERT provided sub-lime results, with a macro-averaged f1 score of 0.45.
Optimize_Prime@DravidianLangTech-ACL2022: Emotion Analysis in Tamil
Apr 19, 2022
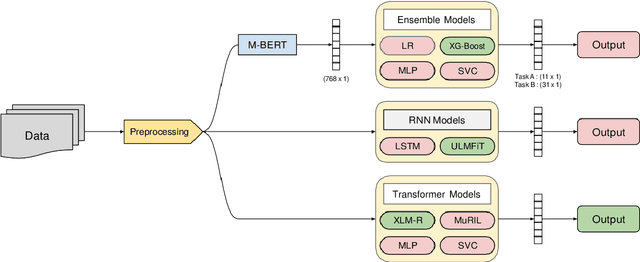
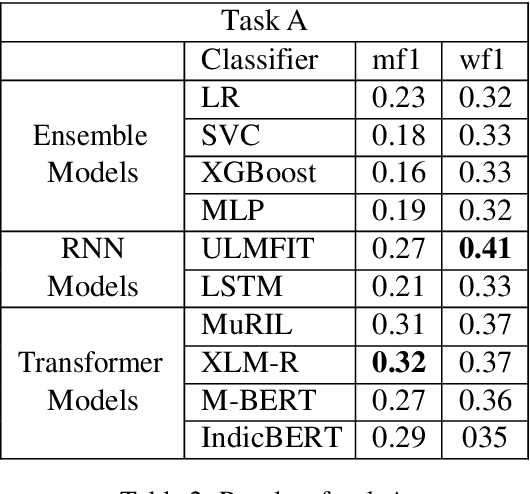
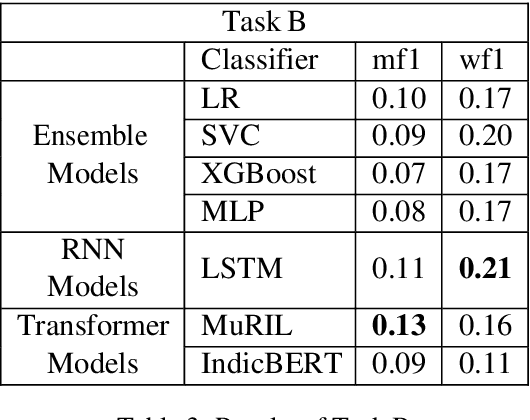
This paper aims to perform an emotion analysis of social media comments in Tamil. Emotion analysis is the process of identifying the emotional context of the text. In this paper, we present the findings obtained by Team Optimize_Prime in the ACL 2022 shared task "Emotion Analysis in Tamil." The task aimed to classify social media comments into categories of emotion like Joy, Anger, Trust, Disgust, etc. The task was further divided into two subtasks, one with 11 broad categories of emotions and the other with 31 specific categories of emotion. We implemented three different approaches to tackle this problem: transformer-based models, Recurrent Neural Networks (RNNs), and Ensemble models. XLM-RoBERTa performed the best on the first task with a macro-averaged f1 score of 0.27, while MuRIL provided the best results on the second task with a macro-averaged f1 score of 0.13.