 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Intimacy Analysis using Ensembles of Multilingual Transformers
Dec 05, 2023



Intimacy estimation of a given text has recently gained importance due to the increase in direct interaction of NLP systems with humans. Intimacy is an important aspect of natural language and has a substantial impact on our everyday communication. Thus the level of intimacy can provide us with deeper insights and richer semantics of conversations. In this paper, we present our work on the SemEval shared task 9 on predicting the level of intimacy for the given text. The dataset consists of tweets in ten languages, out of which only six are available in the training dataset. We conduct several experiments and show that an ensemble of multilingual models along with a language-specific monolingual model has the best performance. We also evaluate other data augmentation methods such as translation and present the results. Lastly, we study the results thoroughly and present some noteworthy insights into this problem.
Empathy and Distress Detection using Ensembles of Transformer Models
Dec 05, 2023This paper presents our approach for the WASSA 2023 Empathy, Emotion and Personality Shared Task. Empathy and distress are human feelings that are implicitly expressed in natural discourses. Empathy and distress detection are crucial challenges in Natural Language Processing that can aid our understanding of conversations. The provided dataset consists of several long-text examples in the English language, with each example associated with a numeric score for empathy and distress. We experiment with several BERT-based models as a part of our approach. We also try various ensemble methods. Our final submission has a Pearson's r score of 0.346, placing us third in the empathy and distress detection subtask.
Mavericks at BLP-2023 Task 1: Ensemble-based Approach Using Language Models for Violence Inciting Text Detection
Nov 30, 2023This paper presents our work for the Violence Inciting Text Detection shared task in the First Workshop on Bangla Language Processing. Social media has accelerated the propagation of hate and violence-inciting speech in society. It is essential to develop efficient mechanisms to detect and curb the propagation of such texts. The problem of detecting violence-inciting texts is further exacerbated in low-resource settings due to sparse research and less data. The data provided in the shared task consists of texts in the Bangla language, where each example is classified into one of the three categories defined based on the types of violence-inciting texts. We try and evaluate several BERT-based models, and then use an ensemble of the models as our final submission. Our submission is ranked 10th in the final leaderboard of the shared task with a macro F1 score of 0.737.
SenTest: Evaluating Robustness of Sentence Encoders
Nov 29, 2023
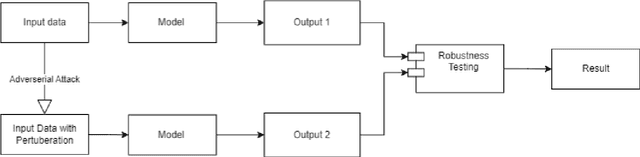


Contrastive learning has proven to be an effective method for pre-training models using weakly labeled data in the vision domain. Sentence transformers are the NLP counterparts to this architecture, and have been growing in popularity due to their rich and effective sentence representations. Having effective sentence representations is paramount in multiple tasks, such as information retrieval, retrieval augmented generation (RAG), and sentence comparison. Keeping in mind the deployability factor of transformers, evaluating the robustness of sentence transformers is of utmost importance. This work focuses on evaluating the robustness of the sentence encoders. We employ several adversarial attacks to evaluate its robustness. This system uses character-level attacks in the form of random character substitution, word-level attacks in the form of synonym replacement, and sentence-level attacks in the form of intra-sentence word order shuffling. The results of the experiments strongly undermine the robustness of sentence encoders. The models produce significantly different predictions as well as embeddings on perturbed datasets. The accuracy of the models can fall up to 15 percent on perturbed datasets as compared to unperturbed datasets. Furthermore, the experiments demonstrate that these embeddings does capture the semantic and syntactic structure (sentence order) of sentences. However, existing supervised classification strategies fail to leverage this information, and merely function as n-gram detectors.
My Boli: Code-mixed Marathi-English Corpora, Pretrained Language Models and Evaluation Benchmarks
Jun 24, 2023



The research on code-mixed data is limited due to the unavailability of dedicated code-mixed datasets and pre-trained language models. In this work, we focus on the low-resource Indian language Marathi which lacks any prior work in code-mixing. We present L3Cube-MeCorpus, a large code-mixed Marathi-English (Mr-En) corpus with 5 million tweets for pretraining. We also release L3Cube-MeBERT and MeRoBERTa, code-mixed BERT-based transformer models pre-trained on MeCorpus. Furthermore, for benchmarking, we present three supervised datasets MeHate, MeSent, and MeLID for downstream tasks like code-mixed Mr-En hate speech detection, sentiment analysis, and language identification respectively. These evaluation datasets individually consist of manually annotated \url{~}12,000 Marathi-English code-mixed tweets. Ablations show that the models trained on this novel corpus significantly outperform the existing state-of-the-art BERT models. This is the first work that presents artifacts for code-mixed Marathi research. All datasets and models are publicly released at https://github.com/l3cube-pune/MarathiNLP .
A Twitter BERT Approach for Offensive Language Detection in Marathi
Dec 20, 2022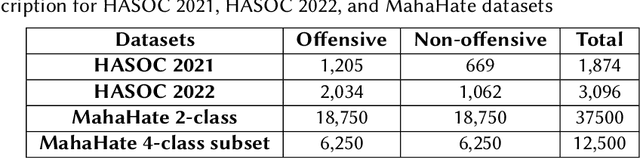
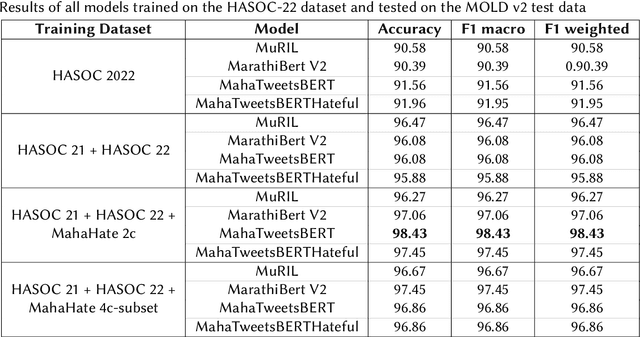
Automated offensive language detection is essential in combating the spread of hate speech, particularly in social media. This paper describes our work on Offensive Language Identification in low resource Indic language Marathi. The problem is formulated as a text classification task to identify a tweet as offensive or non-offensive. We evaluate different mono-lingual and multi-lingual BERT models on this classification task, focusing on BERT models pre-trained with social media datasets. We compare the performance of MuRIL, MahaTweetBERT, MahaTweetBERT-Hateful, and MahaBERT on the HASOC 2022 test set. We also explore external data augmentation from other existing Marathi hate speech corpus HASOC 2021 and L3Cube-MahaHate. The MahaTweetBERT, a BERT model, pre-trained on Marathi tweets when fine-tuned on the combined dataset (HASOC 2021 + HASOC 2022 + MahaHate), outperforms all models with an F1 score of 98.43 on the HASOC 2022 test set. With this, we also provide a new state-of-the-art result on HASOC 2022 / MOLD v2 test set.
Large Language Models for Multi-label Propaganda Detection
Oct 20, 2022
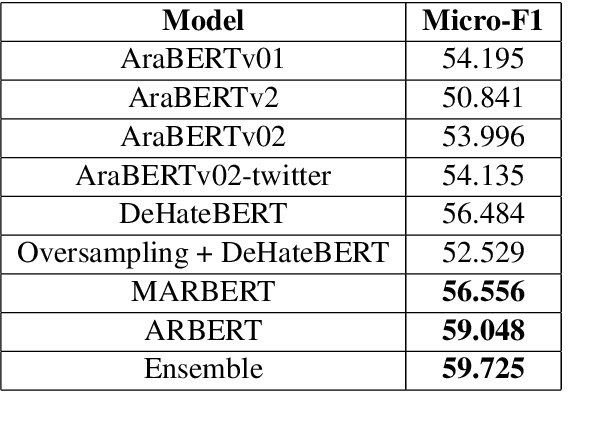
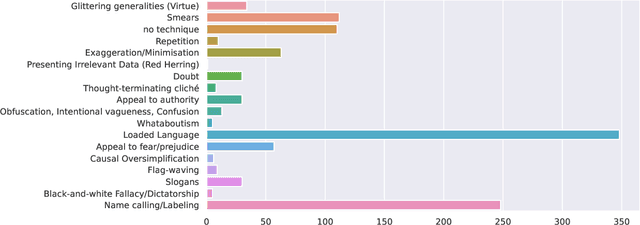
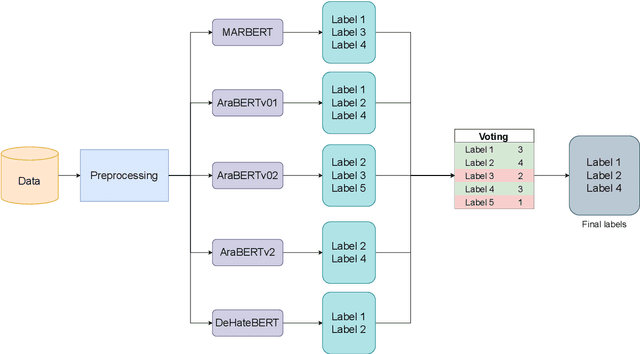
The spread of propaganda through the internet has increased drastically over the past years. Lately, propaganda detection has started gaining importance because of the negative impact it has on society. In this work, we describe our approach for the WANLP 2022 shared task which handles the task of propaganda detection in a multi-label setting. The task demands the model to label the given text as having one or more types of propaganda techniques. There are a total of 21 propaganda techniques to be detected. We show that an ensemble of five models performs the best on the task, scoring a micro-F1 score of 59.73%. We also conduct comprehensive ablations and propose various future directions for this work.
Spread Love Not Hate: Undermining the Importance of Hateful Pre-training for Hate Speech Detection
Oct 09, 2022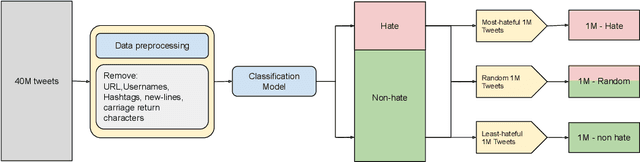
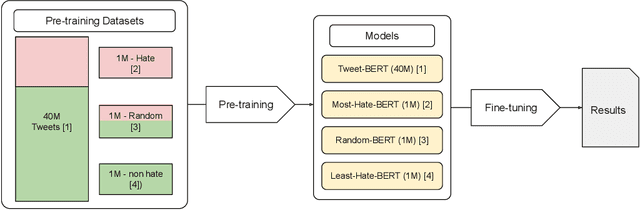
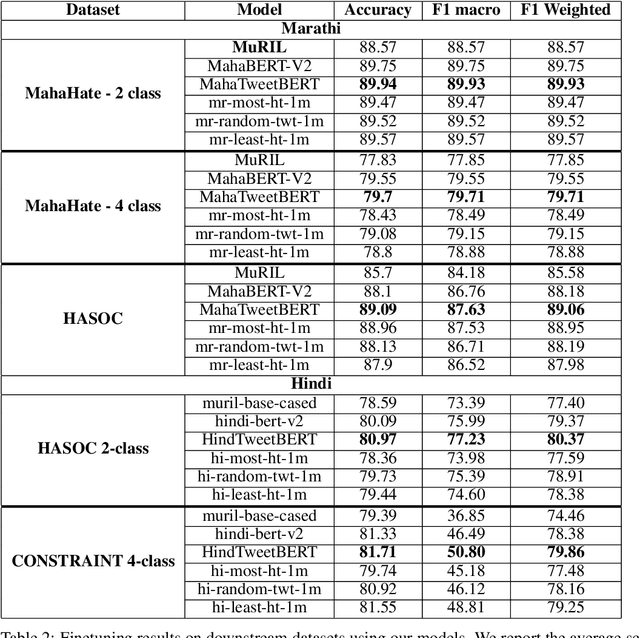

Pre-training large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. Although this method has proven to be effective for many domains, it might not always provide desirable benefits. In this paper we study the effects of hateful pre-training on low resource hate speech classification tasks. While previous studies on English language have emphasized its importance, we aim to to augment their observations with some non-obvious insights. We evaluate different variations of tweet based BERT models pre-trained on hateful, non-hateful and mixed subsets of 40M tweet dataset. This evaluation is carried for Indian languages Hindi and Marathi. This paper is an empirical evidence that hateful pre-training is not the best pre-training option for hate speech detection. We show that pre-training on non-hateful text from target domain provides similar or better results. Further, we introduce HindTweetBERT and MahaTweetBERT, the first publicly available BERT models pre-trained on Hindi and Marathi tweets respectively. We show that they provide state-of-the-art performance on hate speech classification tasks. We also release a gold hate speech evaluation benchmark HateEval-Hi and HateEval-Mr consisting of manually labeled 2000 tweets each.
Band-to-Band Tunneling based Ultra-Energy Efficient Silicon Neuron
Feb 26, 2019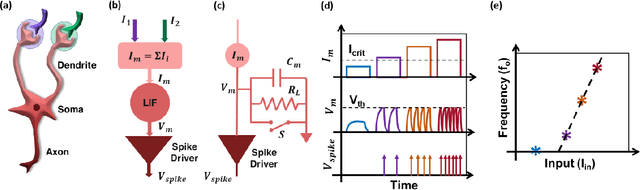
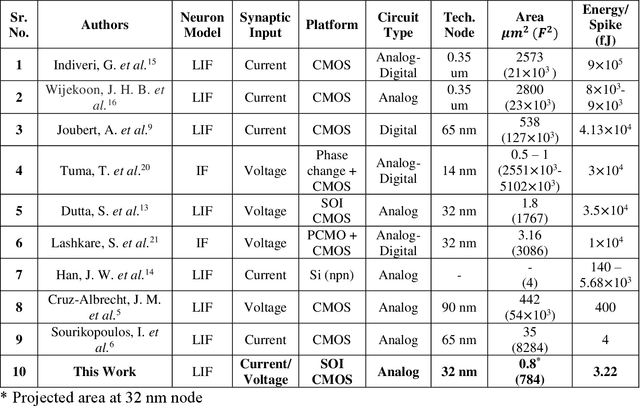
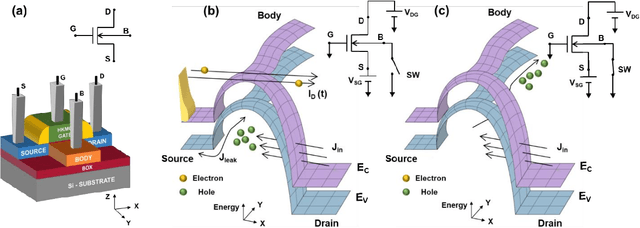
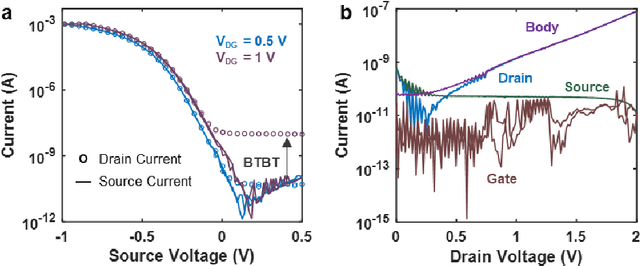
The human brain comprises about a hundred billion neurons connected through quadrillion synapses. Spiking Neural Networks (SNNs) take inspiration from the brain to model complex cognitive and learning tasks. Neuromorphic engineering implements SNNs in hardware, aspiring to mimic the brain at scale (i.e., 100 billion neurons) with biological area and energy efficiency. The design of ultra-energy efficient and compact neurons is essential for the large-scale implementation of SNNs in hardware. In this work, we have experimentally demonstrated a Partially Depleted (PD) Silicon-On-Insulator (SOI) MOSFET based Leaky-Integrate & Fire (LIF) neuron where energy-and area-efficiency is enabled by two elements of design - first tunneling based operation and second compact sub-threshold SOI control circuit design. Band-to-Band Tunneling (BTBT) induced hole storage in the body is used for the "Integrate" function of the neuron. A compact control circuit "Fires" a spike when the body potential exceeds the firing threshold. The neuron then "Resets" by removing the stored holes from the body contact of the device. Additionally, the control circuit provides "Leakiness" in the neuron which is an essential property of biological neurons. The proposed neuron provides 10x higher area efficiency compared to CMOS design with equivalent energy/spike. Alternatively, it has 10^4x higher energy efficiency at area-equivalent neuron technologies. Biologically comparable energy- and area-efficiency along with CMOS compatibility make the proposed device attractive for large-scale hardware implementation of SNNs.