 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Underwater Diver Gesture Recognition
Dec 08, 2023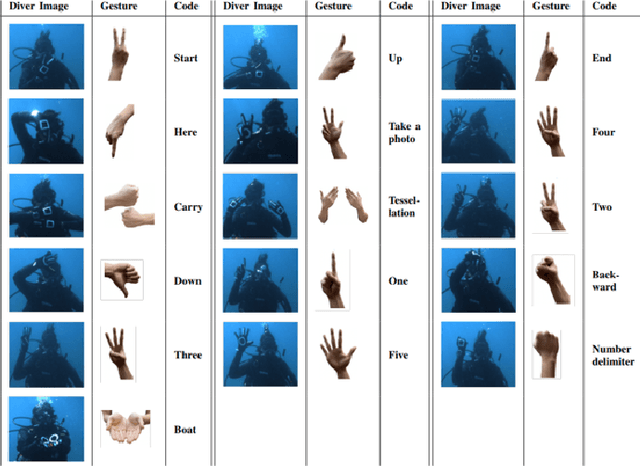
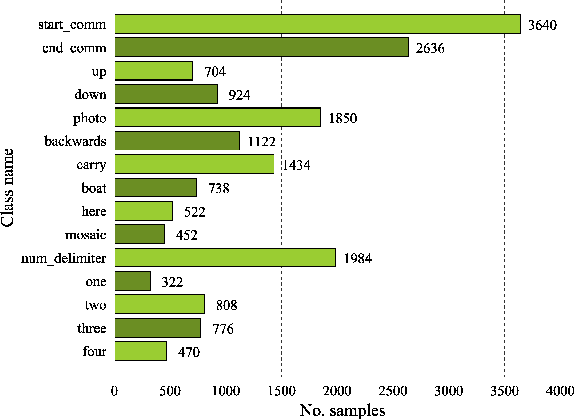
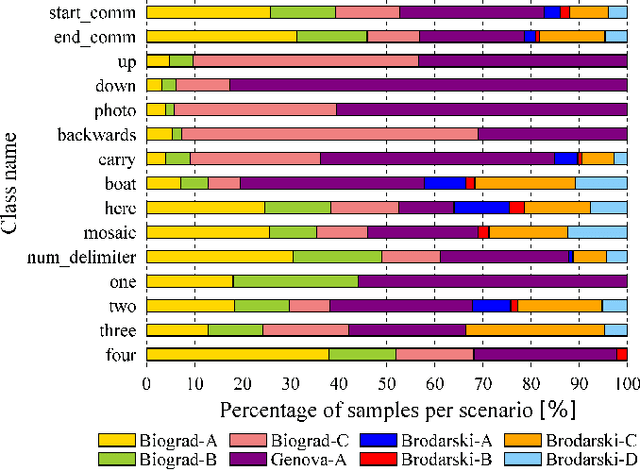
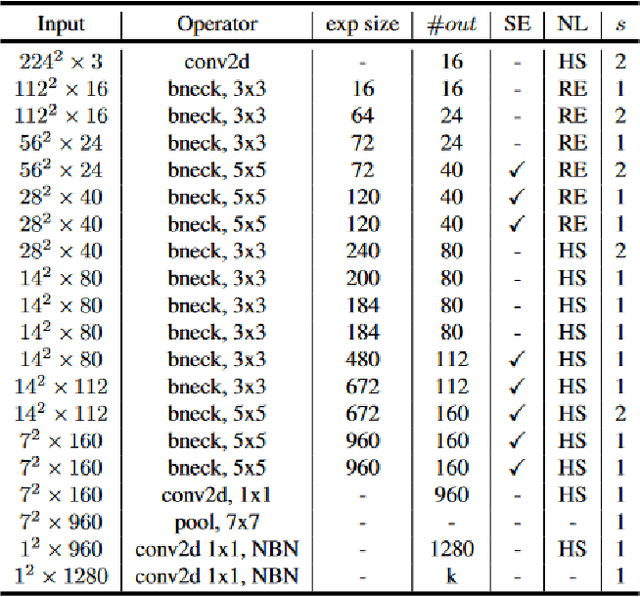
In recent years, usage and applications of Autonomous Underwater Vehicles has grown rapidly. Interaction of divers with the AUVs remains an integral part of the usage of AUVs for various applications and makes building robust and efficient underwater gesture recognition systems extremely important. In this paper, we propose an Underwater Gesture Recognition system trained on the Cognitive Autonomous Diving Buddy Underwater gesture dataset using deep learning that achieves 98.01\% accuracy on the dataset, which to the best of our knowledge is the best performance achieved on this dataset at the time of writing this paper. We also improve the Gesture Recognition System Interpretability by using XAI techniques to visualize the model's predictions.
Mavericks at BLP-2023 Task 1: Ensemble-based Approach Using Language Models for Violence Inciting Text Detection
Nov 30, 2023This paper presents our work for the Violence Inciting Text Detection shared task in the First Workshop on Bangla Language Processing. Social media has accelerated the propagation of hate and violence-inciting speech in society. It is essential to develop efficient mechanisms to detect and curb the propagation of such texts. The problem of detecting violence-inciting texts is further exacerbated in low-resource settings due to sparse research and less data. The data provided in the shared task consists of texts in the Bangla language, where each example is classified into one of the three categories defined based on the types of violence-inciting texts. We try and evaluate several BERT-based models, and then use an ensemble of the models as our final submission. Our submission is ranked 10th in the final leaderboard of the shared task with a macro F1 score of 0.737.
Mavericks at ArAIEval Shared Task: Towards a Safer Digital Space -- Transformer Ensemble Models Tackling Deception and Persuasion
Nov 30, 2023In this paper, we highlight our approach for the "Arabic AI Tasks Evaluation (ArAiEval) Shared Task 2023". We present our approaches for task 1-A and task 2-A of the shared task which focus on persuasion technique detection and disinformation detection respectively. Detection of persuasion techniques and disinformation has become imperative to avoid distortion of authentic information. The tasks use multigenre snippets of tweets and news articles for the given binary classification problem. We experiment with several transformer-based models that were pre-trained on the Arabic language. We fine-tune these state-of-the-art models on the provided dataset. Ensembling is employed to enhance the performance of the systems. We achieved a micro F1-score of 0.742 on task 1-A (8th rank on the leaderboard) and 0.901 on task 2-A (7th rank on the leaderboard) respectively.
Mavericks at NADI 2023 Shared Task: Unravelling Regional Nuances through Dialect Identification using Transformer-based Approach
Nov 30, 2023In this paper, we present our approach for the "Nuanced Arabic Dialect Identification (NADI) Shared Task 2023". We highlight our methodology for subtask 1 which deals with country-level dialect identification. Recognizing dialects plays an instrumental role in enhancing the performance of various downstream NLP tasks such as speech recognition and translation. The task uses the Twitter dataset (TWT-2023) that encompasses 18 dialects for the multi-class classification problem. Numerous transformer-based models, pre-trained on Arabic language, are employed for identifying country-level dialects. We fine-tune these state-of-the-art models on the provided dataset. The ensembling method is leveraged to yield improved performance of the system. We achieved an F1-score of 76.65 (11th rank on the leaderboard) on the test dataset.