 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAikyam: A Video Conferencing Utility for Deaf and Dumb
Dec 10, 2023



With the advent of the pandemic, the use of video conferencing platforms as a means of communication has greatly increased and with it, so have the remote opportunities. The deaf and dumb have traditionally faced several issues in communication, but now the effect is felt more severely. This paper proposes an all-encompassing video conferencing utility that can be used with existing video conferencing platforms to address these issues. Appropriate semantically correct sentences are generated from the signer's gestures which would be interpreted by the system. Along with an audio to emit this sentence, the user's feed is also used to annotate the sentence. This can be viewed by all participants, thus aiding smooth communication with all parties involved. This utility utilizes a simple LSTM model for classification of gestures. The sentences are constructed by a t5 based model. In order to achieve the required data flow, a virtual camera is used.
Empathy and Distress Detection using Ensembles of Transformer Models
Dec 05, 2023This paper presents our approach for the WASSA 2023 Empathy, Emotion and Personality Shared Task. Empathy and distress are human feelings that are implicitly expressed in natural discourses. Empathy and distress detection are crucial challenges in Natural Language Processing that can aid our understanding of conversations. The provided dataset consists of several long-text examples in the English language, with each example associated with a numeric score for empathy and distress. We experiment with several BERT-based models as a part of our approach. We also try various ensemble methods. Our final submission has a Pearson's r score of 0.346, placing us third in the empathy and distress detection subtask.
Study and Survey on Gesture Recognition Systems
Dec 01, 2023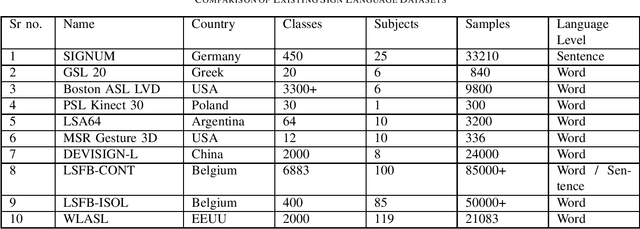

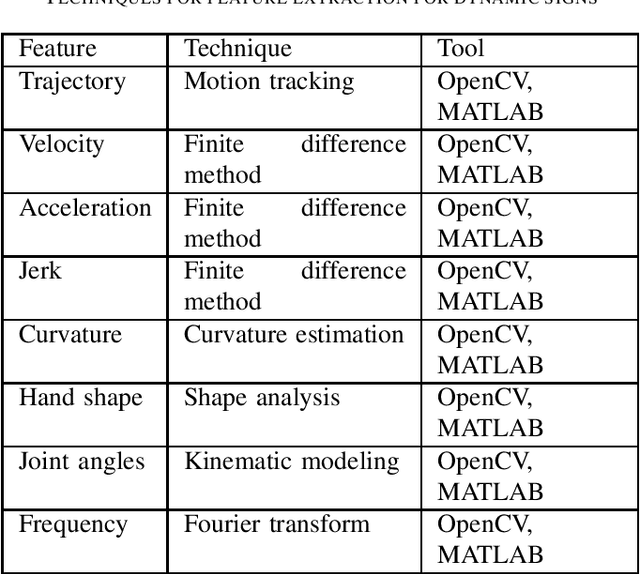
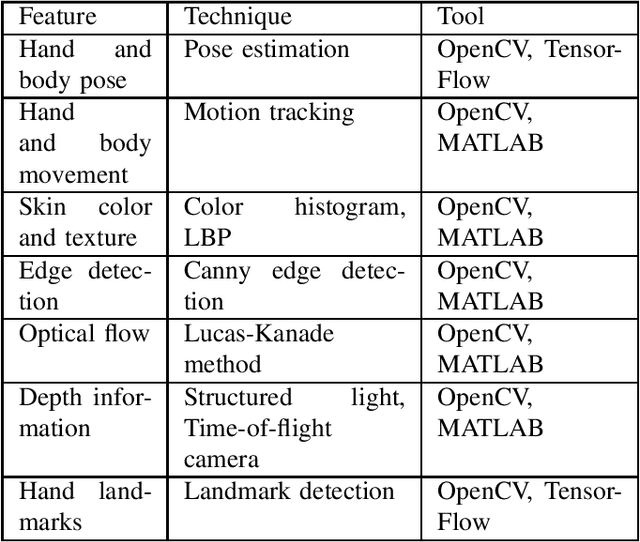
In recent years, there has been a considerable amount of research in the Gesture Recognition domain, mainly owing to the technological advancements in Computer Vision. Various new applications have been conceptualised and developed in this field. This paper discusses the implementation of gesture recognition systems in multiple sectors such as gaming, healthcare, home appliances, industrial robots, and virtual reality. Different methodologies for capturing gestures are compared and contrasted throughout this survey. Various data sources and data acquisition techniques have been discussed. The role of gestures in sign language has been studied and existing approaches have been reviewed. Common challenges faced while building gesture recognition systems have also been explored.
Mavericks at ArAIEval Shared Task: Towards a Safer Digital Space -- Transformer Ensemble Models Tackling Deception and Persuasion
Nov 30, 2023In this paper, we highlight our approach for the "Arabic AI Tasks Evaluation (ArAiEval) Shared Task 2023". We present our approaches for task 1-A and task 2-A of the shared task which focus on persuasion technique detection and disinformation detection respectively. Detection of persuasion techniques and disinformation has become imperative to avoid distortion of authentic information. The tasks use multigenre snippets of tweets and news articles for the given binary classification problem. We experiment with several transformer-based models that were pre-trained on the Arabic language. We fine-tune these state-of-the-art models on the provided dataset. Ensembling is employed to enhance the performance of the systems. We achieved a micro F1-score of 0.742 on task 1-A (8th rank on the leaderboard) and 0.901 on task 2-A (7th rank on the leaderboard) respectively.
Mavericks at BLP-2023 Task 1: Ensemble-based Approach Using Language Models for Violence Inciting Text Detection
Nov 30, 2023This paper presents our work for the Violence Inciting Text Detection shared task in the First Workshop on Bangla Language Processing. Social media has accelerated the propagation of hate and violence-inciting speech in society. It is essential to develop efficient mechanisms to detect and curb the propagation of such texts. The problem of detecting violence-inciting texts is further exacerbated in low-resource settings due to sparse research and less data. The data provided in the shared task consists of texts in the Bangla language, where each example is classified into one of the three categories defined based on the types of violence-inciting texts. We try and evaluate several BERT-based models, and then use an ensemble of the models as our final submission. Our submission is ranked 10th in the final leaderboard of the shared task with a macro F1 score of 0.737.
Mavericks at NADI 2023 Shared Task: Unravelling Regional Nuances through Dialect Identification using Transformer-based Approach
Nov 30, 2023In this paper, we present our approach for the "Nuanced Arabic Dialect Identification (NADI) Shared Task 2023". We highlight our methodology for subtask 1 which deals with country-level dialect identification. Recognizing dialects plays an instrumental role in enhancing the performance of various downstream NLP tasks such as speech recognition and translation. The task uses the Twitter dataset (TWT-2023) that encompasses 18 dialects for the multi-class classification problem. Numerous transformer-based models, pre-trained on Arabic language, are employed for identifying country-level dialects. We fine-tune these state-of-the-art models on the provided dataset. The ensembling method is leveraged to yield improved performance of the system. We achieved an F1-score of 76.65 (11th rank on the leaderboard) on the test dataset.