 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Language Barriers: A Question Answering Dataset for Hindi and Marathi
Sep 01, 2023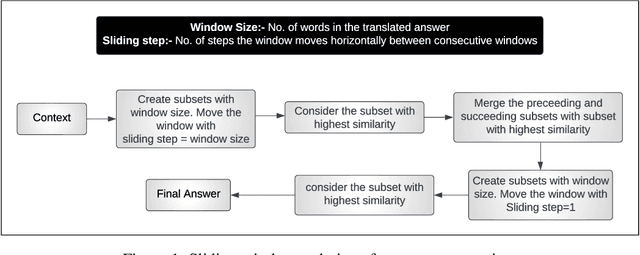
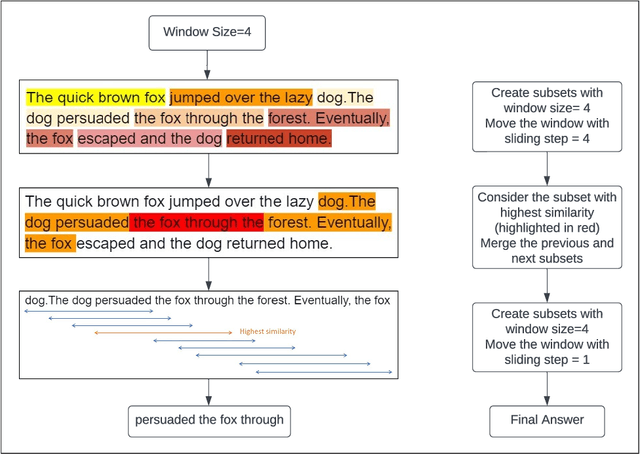
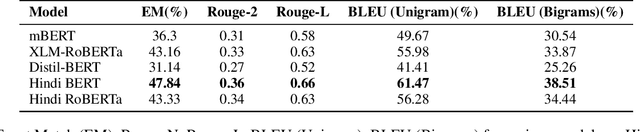
The recent advances in deep-learning have led to the development of highly sophisticated systems with an unquenchable appetite for data. On the other hand, building good deep-learning models for low-resource languages remains a challenging task. This paper focuses on developing a Question Answering dataset for two such languages- Hindi and Marathi. Despite Hindi being the 3rd most spoken language worldwide, with 345 million speakers, and Marathi being the 11th most spoken language globally, with 83.2 million speakers, both languages face limited resources for building efficient Question Answering systems. To tackle the challenge of data scarcity, we have developed a novel approach for translating the SQuAD 2.0 dataset into Hindi and Marathi. We release the largest Question-Answering dataset available for these languages, with each dataset containing 28,000 samples. We evaluate the dataset on various architectures and release the best-performing models for both Hindi and Marathi, which will facilitate further research in these languages. Leveraging similarity tools, our method holds the potential to create datasets in diverse languages, thereby enhancing the understanding of natural language across varied linguistic contexts. Our fine-tuned models, code, and dataset will be made publicly available.
Enhancing Low Resource NER Using Assisting Language And Transfer Learning
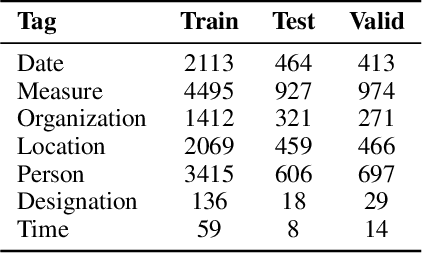
Jun 10, 2023Named Entity Recognition (NER) is a fundamental task in NLP that is used to locate the key information in text and is primarily applied in conversational and search systems. In commercial applications, NER or comparable slot-filling methods have been widely deployed for popular languages. NER is used in applications such as human resources, customer service, search engines, content classification, and academia. In this paper, we draw focus on identifying name entities for low-resource Indian languages that are closely related, like Hindi and Marathi. We use various adaptations of BERT such as baseBERT, AlBERT, and RoBERTa to train a supervised NER model. We also compare multilingual models with monolingual models and establish a baseline. In this work, we show the assisting capabilities of the Hindi and Marathi languages for the NER task. We show that models trained using multiple languages perform better than a single language. However, we also observe that blind mixing of all datasets doesn't necessarily provide improvements and data selection methods may be required.
L3Cube-MahaNER: A Marathi Named Entity Recognition Dataset and BERT models
Apr 12, 2022
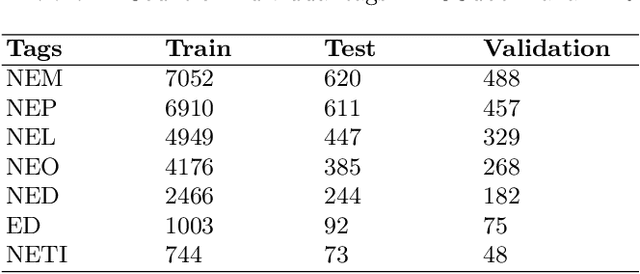
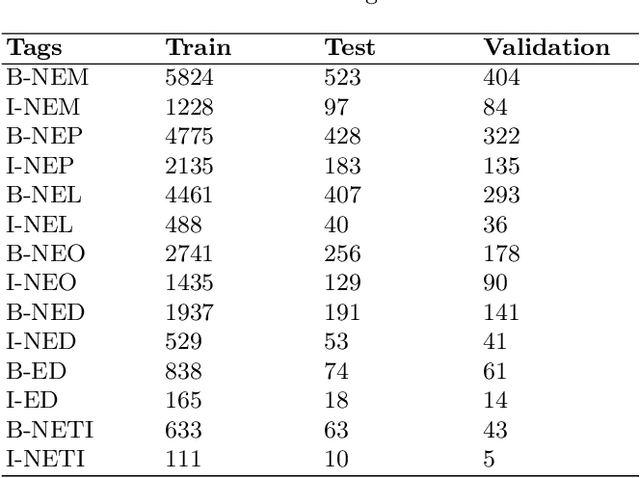
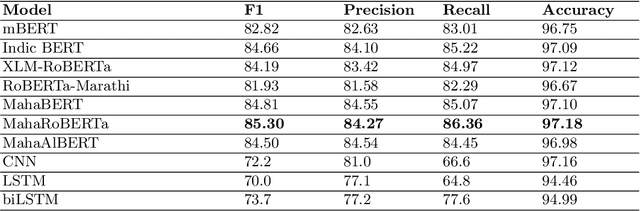
Named Entity Recognition (NER) is a basic NLP task and finds major applications in conversational and search systems. It helps us identify key entities in a sentence used for the downstream application. NER or similar slot filling systems for popular languages have been heavily used in commercial applications. In this work, we focus on Marathi, an Indian language, spoken prominently by the people of Maharashtra state. Marathi is a low resource language and still lacks useful NER resources. We present L3Cube-MahaNER, the first major gold standard named entity recognition dataset in Marathi. We also describe the manual annotation guidelines followed during the process. In the end, we benchmark the dataset on different CNN, LSTM, and Transformer based models like mBERT, XLM-RoBERTa, IndicBERT, MahaBERT, etc. The MahaBERT provides the best performance among all the models. The data and models are available at https://github.com/l3cube-pune/MarathiNLP .
Mono vs Multilingual BERT: A Case Study in Hindi and Marathi Named Entity Recognition
Mar 24, 2022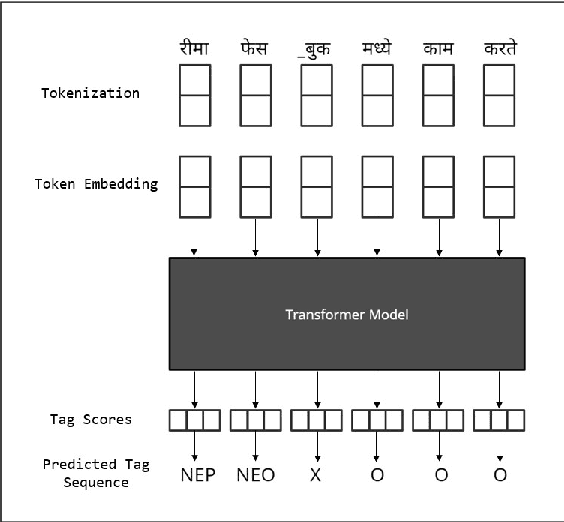

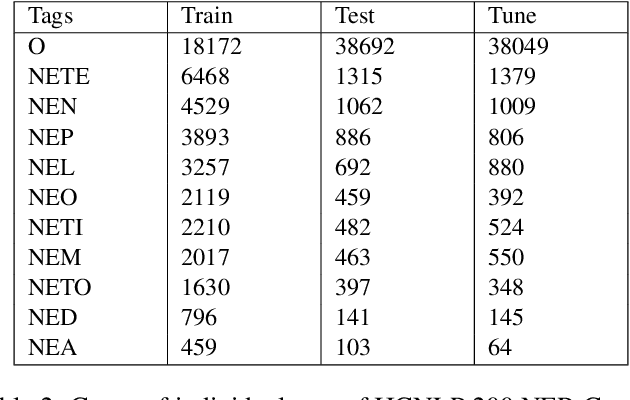
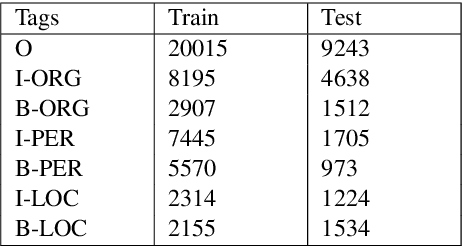
Named entity recognition (NER) is the process of recognising and classifying important information (entities) in text. Proper nouns, such as a person's name, an organization's name, or a location's name, are examples of entities. The NER is one of the important modules in applications like human resources, customer support, search engines, content classification, and academia. In this work, we consider NER for low-resource Indian languages like Hindi and Marathi. The transformer-based models have been widely used for NER tasks. We consider different variations of BERT like base-BERT, RoBERTa, and AlBERT and benchmark them on publicly available Hindi and Marathi NER datasets. We provide an exhaustive comparison of different monolingual and multilingual transformer-based models and establish simple baselines currently missing in the literature. We show that the monolingual MahaRoBERTa model performs the best for Marathi NER whereas the multilingual XLM-RoBERTa performs the best for Hindi NER. We also perform cross-language evaluation and present mixed observations.