 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared LoRA Subspaces for almost Strict Continual Learning
Feb 05, 2026Adapting large pretrained models to new tasks efficiently and continually is crucial for real-world deployment but remains challenging due to catastrophic forgetting and the high cost of retraining. While parameter-efficient tuning methods like low rank adaptation (LoRA) reduce computational demands, they lack mechanisms for strict continual learning and knowledge integration, without relying on data replay, or multiple adapters. We propose Share, a novel approach to parameter efficient continual finetuning that learns and dynamically updates a single, shared low-rank subspace, enabling seamless adaptation across multiple tasks and modalities. Share constructs a foundational subspace that extracts core knowledge from past tasks and incrementally integrates new information by identifying essential subspace directions. Knowledge from each new task is incorporated into this evolving subspace, facilitating forward knowledge transfer, while minimizing catastrophic interference. This approach achieves up to 100x parameter reduction and 281x memory savings over traditional LoRA methods, maintaining performance comparable to jointly trained models. A single Share model can replace hundreds of task-specific LoRA adapters, supporting scalable, asynchronous continual learning. Experiments across image classification, natural language understanding, 3D pose estimation, and text-to-image generation validate its effectiveness, making Share a practical and scalable solution for lifelong learning in large-scale AI systems.
Name That Part: 3D Part Segmentation and Naming
Dec 19, 2025
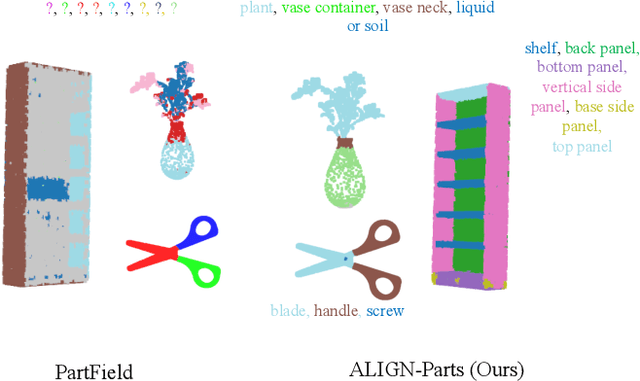

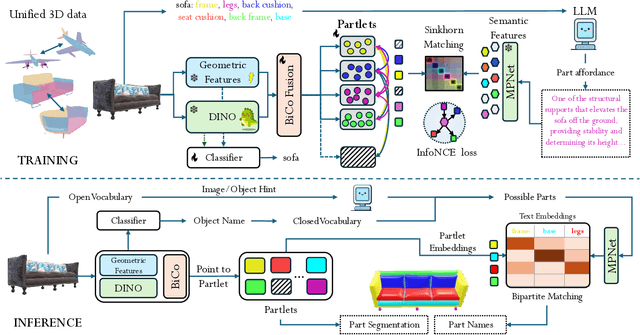
We address semantic 3D part segmentation: decomposing objects into parts with meaningful names. While datasets exist with part annotations, their definitions are inconsistent across datasets, limiting robust training. Previous methods produce unlabeled decompositions or retrieve single parts without complete shape annotations. We propose ALIGN-Parts, which formulates part naming as a direct set alignment task. Our method decomposes shapes into partlets - implicit 3D part representations - matched to part descriptions via bipartite assignment. We combine geometric cues from 3D part fields, appearance from multi-view vision features, and semantic knowledge from language-model-generated affordance descriptions. Text-alignment loss ensures partlets share embedding space with text, enabling a theoretically open-vocabulary matching setup, given sufficient data. Our efficient and novel, one-shot, 3D part segmentation and naming method finds applications in several downstream tasks, including serving as a scalable annotation engine. As our model supports zero-shot matching to arbitrary descriptions and confidence-calibrated predictions for known categories, with human verification, we create a unified ontology that aligns PartNet, 3DCoMPaT++, and Find3D, consisting of 1,794 unique 3D parts. We also show examples from our newly created Tex-Parts dataset. We also introduce 2 novel metrics appropriate for the named 3D part segmentation task.
EigenLoRAx: Recycling Adapters to Find Principal Subspaces for Resource-Efficient Adaptation and Inference
Feb 07, 2025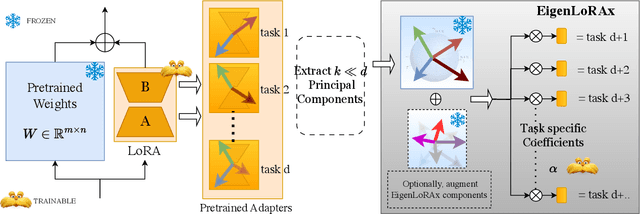
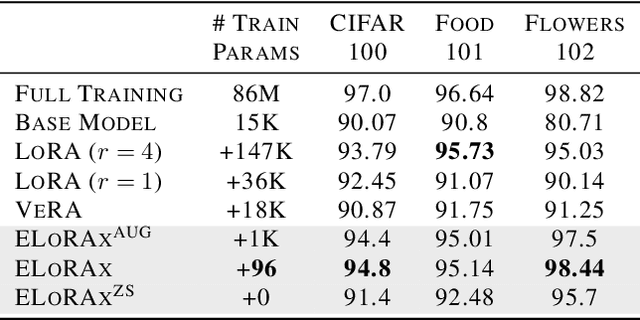
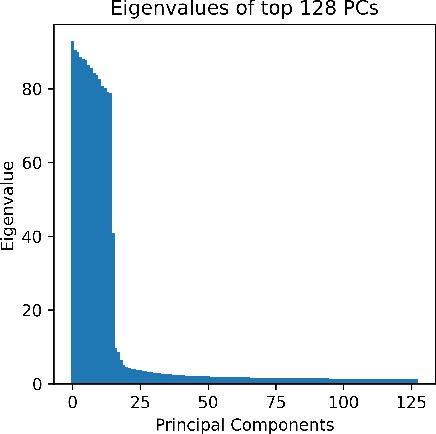
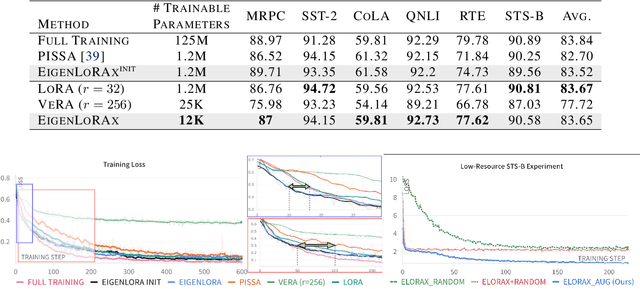
The rapid growth of large models has raised concerns about their environmental impact and equity in accessibility due to significant computational costs. Low-Rank Adapters (LoRA) offer a lightweight solution for finetuning large models, resulting in an abundance of publicly available adapters tailored to diverse domains. We ask: Can these pretrained adapters be leveraged to further streamline adaptation to new tasks while addressing these challenges? We introduce EigenLoRAx, a parameter-efficient finetuning method that recycles existing adapters to create a principal subspace aligned with their shared domain knowledge which can be further augmented with orthogonal basis vectors in low-resource scenarios. This enables rapid adaptation to new tasks by learning only lightweight coefficients on the principal components of the subspace - eliminating the need to finetune entire adapters. EigenLoRAx requires significantly fewer parameters and memory, improving efficiency for both training and inference. Our method demonstrates strong performance across diverse domains and tasks, offering a scalable for edge-based applications, personalization, and equitable deployment of large models in resource-constrained environments.
Task Arithmetic with LoRA for Continual Learning
Nov 04, 2023Continual learning refers to the problem where the training data is available in sequential chunks, termed "tasks". The majority of progress in continual learning has been stunted by the problem of catastrophic forgetting, which is caused by sequential training of the model on streams of data. Moreover, it becomes computationally expensive to sequentially train large models multiple times. To mitigate both of these problems at once, we propose a novel method to continually train transformer-based vision models using low-rank adaptation and task arithmetic. Our method completely bypasses the problem of catastrophic forgetting, as well as reducing the computational requirement for training models on each task. When aided with a small memory of 10 samples per class, our method achieves performance close to full-set finetuning. We present rigorous ablations to support the prowess of our method.
Two-stage Pipeline for Multilingual Dialect Detection
Mar 06, 2023Dialect Identification is a crucial task for localizing various Large Language Models. This paper outlines our approach to the VarDial 2023 shared task. Here we have to identify three or two dialects from three languages each which results in a 9-way classification for Track-1 and 6-way classification for Track-2 respectively. Our proposed approach consists of a two-stage system and outperforms other participants' systems and previous works in this domain. We achieve a score of 58.54% for Track-1 and 85.61% for Track-2. Our codebase is available publicly (https://github.com/ankit-vaidya19/EACL_VarDial2023).