 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning
Dec 15, 2025As humans, we are natural any-horizon reasoners, i.e., we can decide whether to iteratively skim long videos or watch short ones in full when necessary for a given task. With this in mind, one would expect video reasoning models to reason flexibly across different durations. However, SOTA models are still trained to predict answers in a single turn while processing a large number of frames, akin to watching an entire long video, requiring significant resources. This raises the question: Is it possible to develop performant any-horizon video reasoning systems? Inspired by human behavior, we first propose SAGE, an agent system that performs multi-turn reasoning on long videos while handling simpler problems in a single turn. Secondly, we introduce an easy synthetic data generation pipeline using Gemini-2.5-Flash to train the orchestrator, SAGE-MM, which lies at the core of SAGE. We further propose an effective RL post-training recipe essential for instilling any-horizon reasoning ability in SAGE-MM. Thirdly, we curate SAGE-Bench with an average duration of greater than 700 seconds for evaluating video reasoning ability in real-world entertainment use cases. Lastly, we empirically validate the effectiveness of our system, data, and RL recipe, observing notable improvements of up to 6.1% on open-ended video reasoning tasks, as well as an impressive 8.2% improvement on videos longer than 10 minutes.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025



We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.
OLA-VLM: Elevating Visual Perception in Multimodal LLMs with Auxiliary Embedding Distillation
Dec 12, 2024The standard practice for developing contemporary MLLMs is to feed features from vision encoder(s) into the LLM and train with natural language supervision. In this work, we posit an overlooked opportunity to optimize the intermediate LLM representations through a vision perspective (objective), i.e., solely natural language supervision is sub-optimal for the MLLM's visual understanding ability. To that end, we propose OLA-VLM, the first approach distilling knowledge into the LLM's hidden representations from a set of target visual representations. Firstly, we formulate the objective during the pretraining stage in MLLMs as a coupled optimization of predictive visual embedding and next text-token prediction. Secondly, we investigate MLLMs trained solely with natural language supervision and identify a positive correlation between the quality of visual representations within these models and their downstream performance. Moreover, upon probing our OLA-VLM, we observe improved representation quality owing to the embedding optimization. Thirdly, we demonstrate that our OLA-VLM outperforms the single and multi-encoder baselines, proving our approach's superiority over explicitly feeding the corresponding features to the LLM. Particularly, OLA-VLM boosts performance by an average margin of up to 2.5% on various benchmarks, with a notable improvement of 8.7% on the Depth task in CV-Bench. Our code is open-sourced at https://github.com/SHI-Labs/OLA-VLM .
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
May 09, 2024
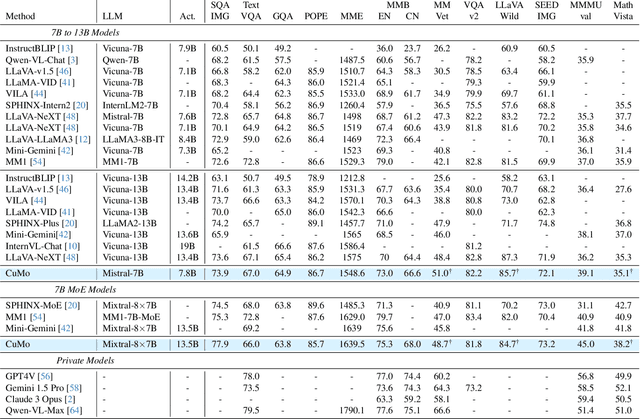
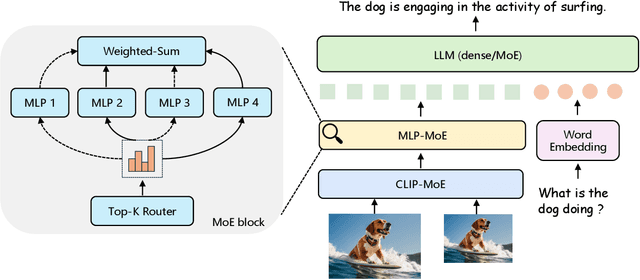
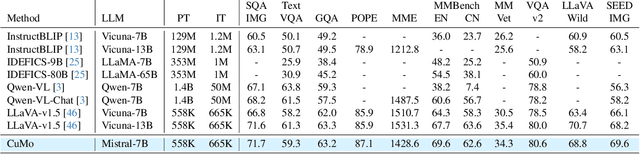
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
Benchmarking Object Detectors with COCO: A New Path Forward
Mar 27, 2024The Common Objects in Context (COCO) dataset has been instrumental in benchmarking object detectors over the past decade. Like every dataset, COCO contains subtle errors and imperfections stemming from its annotation procedure. With the advent of high-performing models, we ask whether these errors of COCO are hindering its utility in reliably benchmarking further progress. In search for an answer, we inspect thousands of masks from COCO (2017 version) and uncover different types of errors such as imprecise mask boundaries, non-exhaustively annotated instances, and mislabeled masks. Due to the prevalence of COCO, we choose to correct these errors to maintain continuity with prior research. We develop COCO-ReM (Refined Masks), a cleaner set of annotations with visibly better mask quality than COCO-2017. We evaluate fifty object detectors and find that models that predict visually sharper masks score higher on COCO-ReM, affirming that they were being incorrectly penalized due to errors in COCO-2017. Moreover, our models trained using COCO-ReM converge faster and score higher than their larger variants trained using COCO-2017, highlighting the importance of data quality in improving object detectors. With these findings, we advocate using COCO-ReM for future object detection research. Our dataset is available at https://cocorem.xyz
VCoder: Versatile Vision Encoders for Multimodal Large Language Models
Dec 21, 2023Humans possess the remarkable skill of Visual Perception, the ability to see and understand the seen, helping them make sense of the visual world and, in turn, reason. Multimodal Large Language Models (MLLM) have recently achieved impressive performance on vision-language tasks ranging from visual question-answering and image captioning to visual reasoning and image generation. However, when prompted to identify or count (perceive) the entities in a given image, existing MLLM systems fail. Working towards developing an accurate MLLM system for perception and reasoning, we propose using Versatile vision enCoders (VCoder) as perception eyes for Multimodal LLMs. We feed the VCoder with perception modalities such as segmentation or depth maps, improving the MLLM's perception abilities. Secondly, we leverage the images from COCO and outputs from off-the-shelf vision perception models to create our COCO Segmentation Text (COST) dataset for training and evaluating MLLMs on the object perception task. Thirdly, we introduce metrics to assess the object perception abilities in MLLMs on our COST dataset. Lastly, we provide extensive experimental evidence proving the VCoder's improved object-level perception skills over existing Multimodal LLMs, including GPT-4V. We open-source our dataset, code, and models to promote research. We open-source our code at https://github.com/SHI-Labs/VCoder
Matting Anything
Jun 08, 2023In this paper, we propose the Matting Anything Model (MAM), an efficient and versatile framework for estimating the alpha matte of any instance in an image with flexible and interactive visual or linguistic user prompt guidance. MAM offers several significant advantages over previous specialized image matting networks: (i) MAM is capable of dealing with various types of image matting, including semantic, instance, and referring image matting with only a single model; (ii) MAM leverages the feature maps from the Segment Anything Model (SAM) and adopts a lightweight Mask-to-Matte (M2M) module to predict the alpha matte through iterative refinement, which has only 2.7 million trainable parameters. (iii) By incorporating SAM, MAM simplifies the user intervention required for the interactive use of image matting from the trimap to the box, point, or text prompt. We evaluate the performance of MAM on various image matting benchmarks, and the experimental results demonstrate that MAM achieves comparable performance to the state-of-the-art specialized image matting models under different metrics on each benchmark. Overall, MAM shows superior generalization ability and can effectively handle various image matting tasks with fewer parameters, making it a practical solution for unified image matting. Our code and models are open-sourced at https://github.com/SHI-Labs/Matting-Anything.
OneFormer: One Transformer to Rule Universal Image Segmentation
Nov 10, 2022



Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible. To support further research, we open-source our code and models at https://github.com/SHI-Labs/OneFormer