 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Forcing for Scalable Spatial Generation
Jun 11, 2026Text-to-image (T2I) models contain rich spatial priors. Synthesizing photorealistic, cluttered scenes requires an understanding of geometry, including perspective and relative scale. Prior works adapt T2I models to leverage this prior for depth prediction, but they require dense depth data and involve complex recipes. We propose Modality Forcing, a simple, scalable post-training recipe for joint image-depth generation using a single DiT trained on sparse depth data. Modality Forcing enables conditional and joint generation of image and depth in any permutation by assigning separate noise levels per modality. Per-modality decoders let us train on sparse, real-world depth and achieve strong, generalizable depth prediction. We further show that Modality Forcing inherits the scalability of T2I pre-training: by training a set of T2I models from scratch (370M to 3.3B parameters), we find that larger models trained on more image data produce more accurate depth. Our strongest model is competitive with state-of-the-art monocular depth estimators and reduces AbsRel by 57% relative to existing joint image-depth generative models. These results provide strong evidence that image generation is a scalable pre-training objective for spatial perception. https://modality-forcing.github.io/
GPIC: A Giant Permissive Image Corpus for Visual Generation
May 28, 2026Studying scalable methods for visual generative modeling requires large, accessible, and stable datasets. We introduce GPIC, a Giant Permissive Image Corpus of approximately 28 trillion pixels. GPIC comprises diverse internet images captioned by a state-of-the-art vision-language model, including 100M training, 200K validation, and 1M test examples. Moreover, all GPIC images are permissively licensed for both research and commercial use. GPIC is safety-filtered, deduplicated, and centrally hosted on Hugging Face. We provide a benchmarking protocol for generative modeling on GPIC. Finally, we provide a reference baseline for pixel-space flow matching on GPIC. Our dataset, benchmark, and models are available at https://huggingface.co/datasets/stanford-vision-lab/gpic. Evaluation toolkit and code are available at https://gpic.stanford.edu
Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation
Feb 11, 2026Latent diffusion models excel at generating high-quality images but lose the benefits of end-to-end modeling. They discard information during image encoding, require a separately trained decoder, and model an auxiliary distribution to the raw data. In this paper, we propose Latent Forcing, a simple modification to existing architectures that achieves the efficiency of latent diffusion while operating on raw natural images. Our approach orders the denoising trajectory by jointly processing latents and pixels with separately tuned noise schedules. This allows the latents to act as a scratchpad for intermediate computation before high-frequency pixel features are generated. We find that the order of conditioning signals is critical, and we analyze this to explain differences between REPA distillation in the tokenizer and the diffusion model, conditional versus unconditional generation, and how tokenizer reconstruction quality relates to diffusability. Applied to ImageNet, Latent Forcing achieves a new state-of-the-art for diffusion transformer-based pixel generation at our compute scale.
Towards Minimal Fine-Tuning of VLMs
Dec 22, 2025We introduce Image-LoRA, a lightweight parameter efficient fine-tuning (PEFT) recipe for transformer-based vision-language models (VLMs). Image-LoRA applies low-rank adaptation only to the value path of attention layers within the visual-token span, reducing adapter-only training FLOPs roughly in proportion to the visual-token fraction. We further adapt only a subset of attention heads, selected using head influence scores estimated with a rank-1 Image-LoRA, and stabilize per-layer updates via selection-size normalization. Across screen-centric grounding and referring benchmarks spanning text-heavy to image-heavy regimes, Image-LoRA matches or closely approaches standard LoRA accuracy while using fewer trainable parameters and lower adapter-only training FLOPs. The method also preserves the pure-text reasoning performance of VLMs before and after fine-tuning, as further shown on GSM8K.
Visual Test-time Scaling for GUI Agent Grounding
May 01, 2025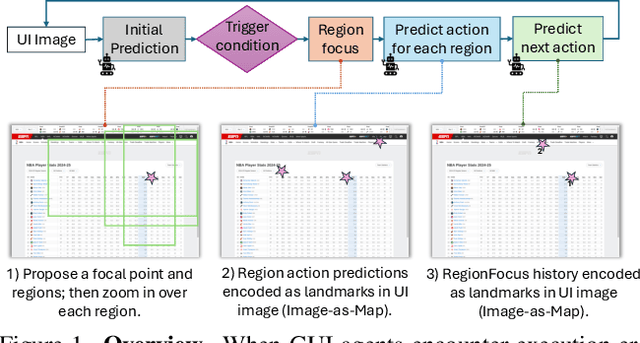
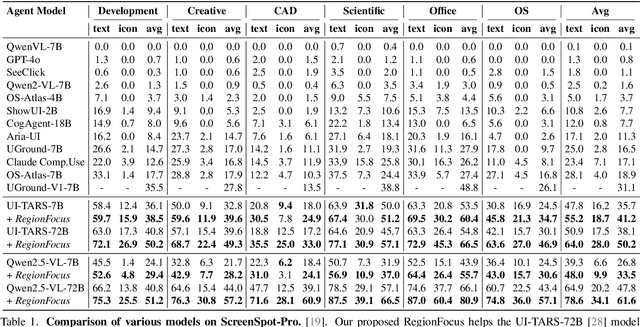
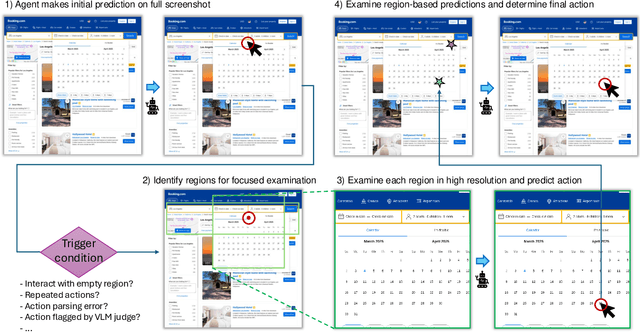
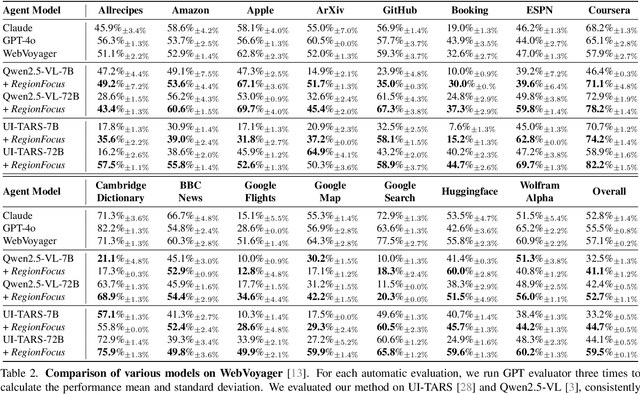
We introduce RegionFocus, a visual test-time scaling approach for Vision Language Model Agents. Understanding webpages is challenging due to the visual complexity of GUI images and the large number of interface elements, making accurate action selection difficult. Our approach dynamically zooms in on relevant regions, reducing background clutter and improving grounding accuracy. To support this process, we propose an image-as-map mechanism that visualizes key landmarks at each step, providing a transparent action record and enables the agent to effectively choose among action candidates. Even with a simple region selection strategy, we observe significant performance gains of 28+\% on Screenspot-pro and 24+\% on WebVoyager benchmarks on top of two state-of-the-art open vision language model agents, UI-TARS and Qwen2.5-VL, highlighting the effectiveness of visual test-time scaling in interactive settings. We achieve a new state-of-the-art grounding performance of 61.6\% on the ScreenSpot-Pro benchmark by applying RegionFocus to a Qwen2.5-VL-72B model. Our code will be released publicly at https://github.com/tiangeluo/RegionFocus.
Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization
Mar 14, 2025Since the advent of popular visual generation frameworks like VQGAN and latent diffusion models, state-of-the-art image generation systems have generally been two-stage systems that first tokenize or compress visual data into a lower-dimensional latent space before learning a generative model. Tokenizer training typically follows a standard recipe in which images are compressed and reconstructed subject to a combination of MSE, perceptual, and adversarial losses. Diffusion autoencoders have been proposed in prior work as a way to learn end-to-end perceptually-oriented image compression, but have not yet shown state-of-the-art performance on the competitive task of ImageNet-1K reconstruction. We propose FlowMo, a transformer-based diffusion autoencoder that achieves a new state-of-the-art for image tokenization at multiple compression rates without using convolutions, adversarial losses, spatially-aligned two-dimensional latent codes, or distilling from other tokenizers. Our key insight is that FlowMo training should be broken into a mode-matching pre-training stage and a mode-seeking post-training stage. In addition, we conduct extensive analyses and explore the training of generative models atop the FlowMo tokenizer. Our code and models will be available at http://kylesargent.github.io/flowmo .
LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding
Feb 27, 2025Our approach to training 3D vision-language understanding models is to train a feedforward model that makes predictions in 3D, but never requires 3D labels and is supervised only in 2D, using 2D losses and differentiable rendering. The approach is new for vision-language understanding. By treating the reconstruction as a ``latent variable'', we can render the outputs without placing unnecessary constraints on the network architecture (e.g. can be used with decoder-only models). For training, only need images and camera pose, and 2D labels. We show that we can even remove the need for 2D labels by using pseudo-labels from pretrained 2D models. We demonstrate this to pretrain a network, and we finetune it for 3D vision-language understanding tasks. We show this approach outperforms baselines/sota for 3D vision-language grounding, and also outperforms other 3D pretraining techniques. Project page: https://liftgs.github.io.
Probing Visual Language Priors in VLMs
Dec 31, 2024



Despite recent advances in Vision-Language Models (VLMs), many still over-rely on visual language priors present in their training data rather than true visual reasoning. To examine the situation, we introduce ViLP, a visual question answering (VQA) benchmark that pairs each question with three potential answers and three corresponding images: one image whose answer can be inferred from text alone, and two images that demand visual reasoning. By leveraging image generative models, we ensure significant variation in texture, shape, conceptual combinations, hallucinated elements, and proverb-based contexts, making our benchmark images distinctly out-of-distribution. While humans achieve near-perfect accuracy, modern VLMs falter; for instance, GPT-4 achieves only 66.17% on ViLP. To alleviate this, we propose a self-improving framework in which models generate new VQA pairs and images, then apply pixel-level and semantic corruptions to form "good-bad" image pairs for self-training. Our training objectives compel VLMs to focus more on actual visual inputs and have demonstrated their effectiveness in enhancing the performance of open-source VLMs, including LLaVA-v1.5 and Cambrian.
Lightplane: Highly-Scalable Components for Neural 3D Fields
Apr 30, 2024



Contemporary 3D research, particularly in reconstruction and generation, heavily relies on 2D images for inputs or supervision. However, current designs for these 2D-3D mapping are memory-intensive, posing a significant bottleneck for existing methods and hindering new applications. In response, we propose a pair of highly scalable components for 3D neural fields: Lightplane Render and Splatter, which significantly reduce memory usage in 2D-3D mapping. These innovations enable the processing of vastly more and higher resolution images with small memory and computational costs. We demonstrate their utility in various applications, from benefiting single-scene optimization with image-level losses to realizing a versatile pipeline for dramatically scaling 3D reconstruction and generation. Code: \url{https://github.com/facebookresearch/lightplane}.
Probing the 3D Awareness of Visual Foundation Models
Apr 12, 2024Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.