 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding
Feb 27, 2025Our approach to training 3D vision-language understanding models is to train a feedforward model that makes predictions in 3D, but never requires 3D labels and is supervised only in 2D, using 2D losses and differentiable rendering. The approach is new for vision-language understanding. By treating the reconstruction as a ``latent variable'', we can render the outputs without placing unnecessary constraints on the network architecture (e.g. can be used with decoder-only models). For training, only need images and camera pose, and 2D labels. We show that we can even remove the need for 2D labels by using pseudo-labels from pretrained 2D models. We demonstrate this to pretrain a network, and we finetune it for 3D vision-language understanding tasks. We show this approach outperforms baselines/sota for 3D vision-language grounding, and also outperforms other 3D pretraining techniques. Project page: https://liftgs.github.io.
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
Oct 19, 2023



We present Habitat 3.0: a simulation platform for studying collaborative human-robot tasks in home environments. Habitat 3.0 offers contributions across three dimensions: (1) Accurate humanoid simulation: addressing challenges in modeling complex deformable bodies and diversity in appearance and motion, all while ensuring high simulation speed. (2) Human-in-the-loop infrastructure: enabling real human interaction with simulated robots via mouse/keyboard or a VR interface, facilitating evaluation of robot policies with human input. (3) Collaborative tasks: studying two collaborative tasks, Social Navigation and Social Rearrangement. Social Navigation investigates a robot's ability to locate and follow humanoid avatars in unseen environments, whereas Social Rearrangement addresses collaboration between a humanoid and robot while rearranging a scene. These contributions allow us to study end-to-end learned and heuristic baselines for human-robot collaboration in-depth, as well as evaluate them with humans in the loop. Our experiments demonstrate that learned robot policies lead to efficient task completion when collaborating with unseen humanoid agents and human partners that might exhibit behaviors that the robot has not seen before. Additionally, we observe emergent behaviors during collaborative task execution, such as the robot yielding space when obstructing a humanoid agent, thereby allowing the effective completion of the task by the humanoid agent. Furthermore, our experiments using the human-in-the-loop tool demonstrate that our automated evaluation with humanoids can provide an indication of the relative ordering of different policies when evaluated with real human collaborators. Habitat 3.0 unlocks interesting new features in simulators for Embodied AI, and we hope it paves the way for a new frontier of embodied human-AI interaction capabilities.
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?
Oct 03, 2023



We present a large empirical investigation on the use of pre-trained visual representations (PVRs) for training downstream policies that execute real-world tasks. Our study spans five different PVRs, two different policy-learning paradigms (imitation and reinforcement learning), and three different robots for 5 distinct manipulation and indoor navigation tasks. From this effort, we can arrive at three insights: 1) the performance trends of PVRs in the simulation are generally indicative of their trends in the real world, 2) the use of PVRs enables a first-of-its-kind result with indoor ImageNav (zero-shot transfer to a held-out scene in the real world), and 3) the benefits from variations in PVRs, primarily data-augmentation and fine-tuning, also transfer to the real-world performance. See project website for additional details and visuals.
Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
Mar 31, 2023



We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data scale and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 5.6M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Finally, we show that task or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. These models required over 10,000 GPU-hours to train and can be found on our website for the benefit of the research community.
OVRL-V2: A simple state-of-art baseline for ImageNav and ObjectNav
Mar 14, 2023We present a single neural network architecture composed of task-agnostic components (ViTs, convolutions, and LSTMs) that achieves state-of-art results on both the ImageNav ("go to location in <this picture>") and ObjectNav ("find a chair") tasks without any task-specific modules like object detection, segmentation, mapping, or planning modules. Such general-purpose methods offer advantages of simplicity in design, positive scaling with available compute, and versatile applicability to multiple tasks. Our work builds upon the recent success of self-supervised learning (SSL) for pre-training vision transformers (ViT). However, while the training recipes for convolutional networks are mature and robust, the recipes for ViTs are contingent and brittle, and in the case of ViTs for visual navigation, yet to be fully discovered. Specifically, we find that vanilla ViTs do not outperform ResNets on visual navigation. We propose the use of a compression layer operating over ViT patch representations to preserve spatial information along with policy training improvements. These improvements allow us to demonstrate positive scaling laws for the first time in visual navigation tasks. Consequently, our model advances state-of-the-art performance on ImageNav from 54.2% to 82.0% success and performs competitively against concurrent state-of-art on ObjectNav with success rate of 64.0% vs. 65.0%. Overall, this work does not present a fundamentally new approach, but rather recommendations for training a general-purpose architecture that achieves state-of-art performance today and could serve as a strong baseline for future methods.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

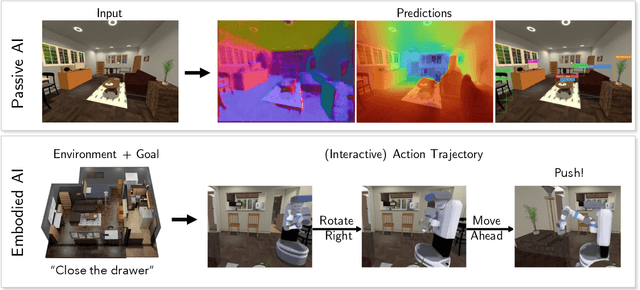
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Is Mapping Necessary for Realistic PointGoal Navigation?
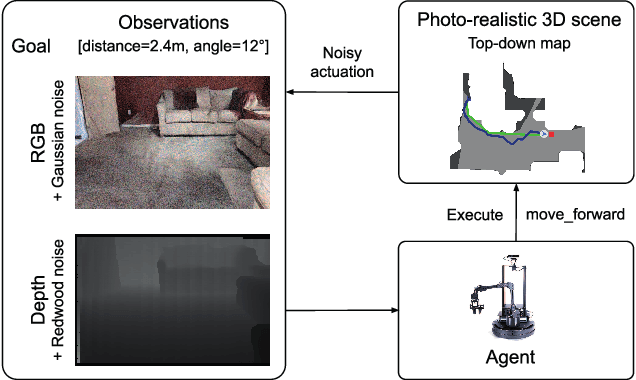
Jun 07, 2022
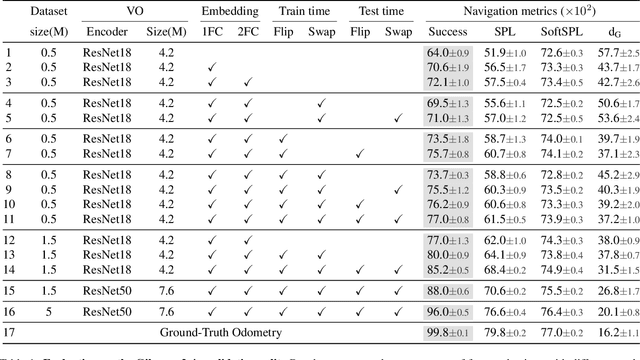
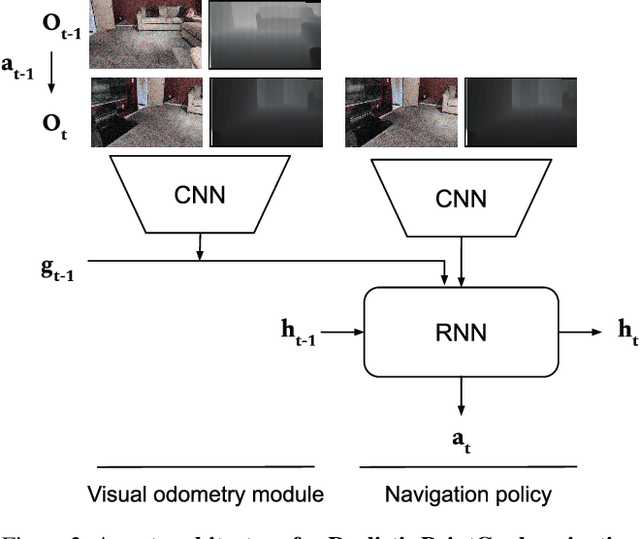
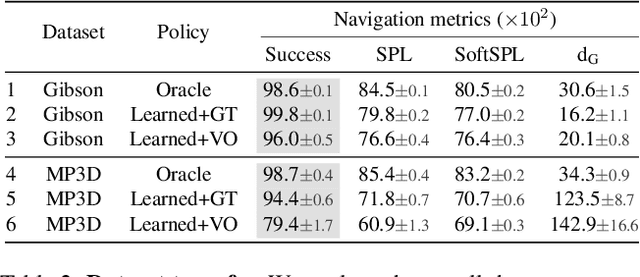
Can an autonomous agent navigate in a new environment without building an explicit map? For the task of PointGoal navigation ('Go to $\Delta x$, $\Delta y$') under idealized settings (no RGB-D and actuation noise, perfect GPS+Compass), the answer is a clear 'yes' - map-less neural models composed of task-agnostic components (CNNs and RNNs) trained with large-scale reinforcement learning achieve 100% Success on a standard dataset (Gibson). However, for PointNav in a realistic setting (RGB-D and actuation noise, no GPS+Compass), this is an open question; one we tackle in this paper. The strongest published result for this task is 71.7% Success. First, we identify the main (perhaps, only) cause of the drop in performance: the absence of GPS+Compass. An agent with perfect GPS+Compass faced with RGB-D sensing and actuation noise achieves 99.8% Success (Gibson-v2 val). This suggests that (to paraphrase a meme) robust visual odometry is all we need for realistic PointNav; if we can achieve that, we can ignore the sensing and actuation noise. With that as our operating hypothesis, we scale the dataset and model size, and develop human-annotation-free data-augmentation techniques to train models for visual odometry. We advance the state of art on the Habitat Realistic PointNav Challenge from 71% to 94% Success (+23, 31% relative) and 53% to 74% SPL (+21, 40% relative). While our approach does not saturate or 'solve' this dataset, this strong improvement combined with promising zero-shot sim2real transfer (to a LoCoBot) provides evidence consistent with the hypothesis that explicit mapping may not be necessary for navigation, even in a realistic setting.
Offline Visual Representation Learning for Embodied Navigation
Apr 27, 2022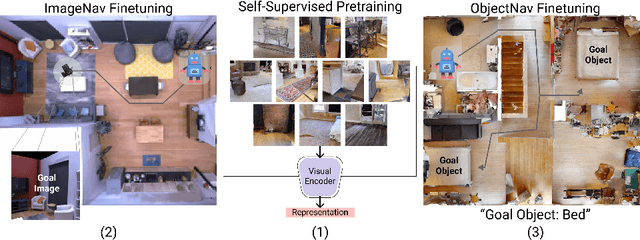
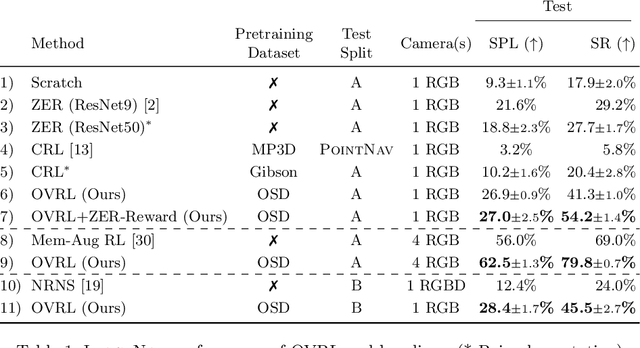
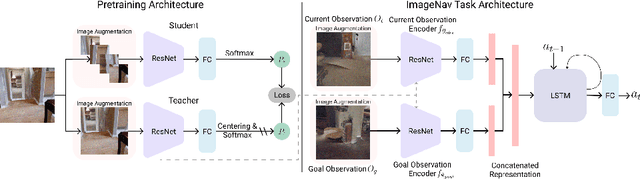
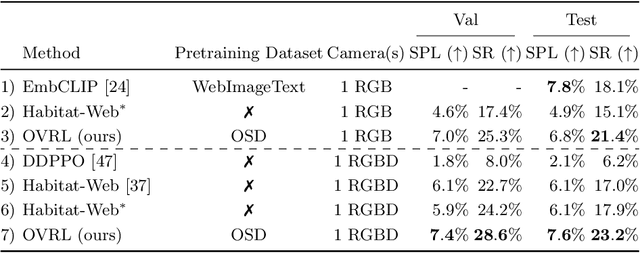
How should we learn visual representations for embodied agents that must see and move? The status quo is tabula rasa in vivo, i.e. learning visual representations from scratch while also learning to move, potentially augmented with auxiliary tasks (e.g. predicting the action taken between two successive observations). In this paper, we show that an alternative 2-stage strategy is far more effective: (1) offline pretraining of visual representations with self-supervised learning (SSL) using large-scale pre-rendered images of indoor environments (Omnidata), and (2) online finetuning of visuomotor representations on specific tasks with image augmentations under long learning schedules. We call this method Offline Visual Representation Learning (OVRL). We conduct large-scale experiments - on 3 different 3D datasets (Gibson, HM3D, MP3D), 2 tasks (ImageNav, ObjectNav), and 2 policy learning algorithms (RL, IL) - and find that the OVRL representations lead to significant across-the-board improvements in state of art, on ImageNav from 29.2% to 54.2% (+25% absolute, 86% relative) and on ObjectNav from 18.1% to 23.2% (+5.1% absolute, 28% relative). Importantly, both results were achieved by the same visual encoder generalizing to datasets that were not seen during pretraining. While the benefits of pretraining sometimes diminish (or entirely disappear) with long finetuning schedules, we find that OVRL's performance gains continue to increase (not decrease) as the agent is trained for 2 billion frames of experience.