 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Preserving Reinforcement Learning
Mar 12, 2026Policy gradient algorithms have driven many recent advancements in language model reasoning. An appealing property is their ability to learn from exploration on their own trajectories, a process crucial for fostering diverse and creative solutions. As we show in this paper, many policy gradient algorithms naturally reduce the entropy -- and thus the diversity of explored trajectories -- as part of training, yielding a policy increasingly limited in its ability to explore. In this paper, we argue that entropy should be actively monitored and controlled throughout training. We formally analyze the contributions of leading policy gradient objectives on entropy dynamics, identify empirical factors (such as numerical precision) that significantly impact entropy behavior, and propose explicit mechanisms for entropy control. These include REPO, a family of algorithms that modify the advantage function to regulate entropy, and ADAPO, an adaptive asymmetric clipping approach. Models trained with our entropy-preserving methods maintain diversity throughout training, yielding final policies that are more performant and retain their trainability for sequential learning in new environments.
* Published at ICLR 2026
Robust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Cut Your Losses in Large-Vocabulary Language Models
Nov 13, 2024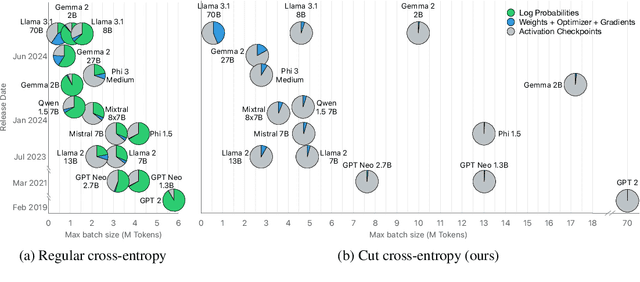
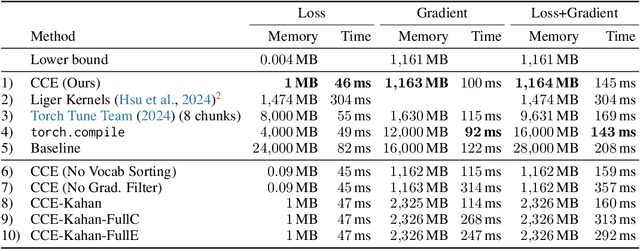
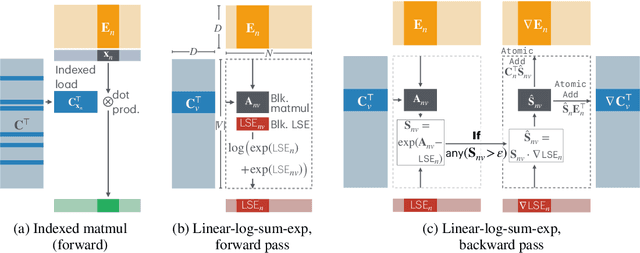
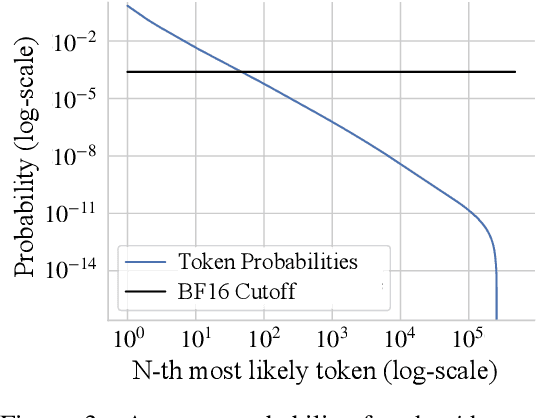
As language models grow ever larger, so do their vocabularies. This has shifted the memory footprint of LLMs during training disproportionately to one single layer: the cross-entropy in the loss computation. Cross-entropy builds up a logit matrix with entries for each pair of input tokens and vocabulary items and, for small models, consumes an order of magnitude more memory than the rest of the LLM combined. We propose Cut Cross-Entropy (CCE), a method that computes the cross-entropy loss without materializing the logits for all tokens into global memory. Rather, CCE only computes the logit for the correct token and evaluates the log-sum-exp over all logits on the fly. We implement a custom kernel that performs the matrix multiplications and the log-sum-exp reduction over the vocabulary in flash memory, making global memory consumption for the cross-entropy computation negligible. This has a dramatic effect. Taking the Gemma 2 (2B) model as an example, CCE reduces the memory footprint of the loss computation from 24 GB to 1 MB, and the total training-time memory consumption of the classifier head from 28 GB to 1 GB. To improve the throughput of CCE, we leverage the inherent sparsity of softmax and propose to skip elements of the gradient computation that have a negligible (i.e., below numerical precision) contribution to the gradient. Experiments demonstrate that the dramatic reduction in memory consumption is accomplished without sacrificing training speed or convergence.
Does Spatial Cognition Emerge in Frontier Models?
Oct 09, 2024Not yet. We present SPACE, a benchmark that systematically evaluates spatial cognition in frontier models. Our benchmark builds on decades of research in cognitive science. It evaluates large-scale mapping abilities that are brought to bear when an organism traverses physical environments, smaller-scale reasoning about object shapes and layouts, and cognitive infrastructure such as spatial attention and memory. For many tasks, we instantiate parallel presentations via text and images, allowing us to benchmark both large language models and large multimodal models. Results suggest that contemporary frontier models fall short of the spatial intelligence of animals, performing near chance level on a number of classic tests of animal cognition.
Emergence of Maps in the Memories of Blind Navigation Agents
Jan 30, 2023Animal navigation research posits that organisms build and maintain internal spatial representations, or maps, of their environment. We ask if machines -- specifically, artificial intelligence (AI) navigation agents -- also build implicit (or 'mental') maps. A positive answer to this question would (a) explain the surprising phenomenon in recent literature of ostensibly map-free neural-networks achieving strong performance, and (b) strengthen the evidence of mapping as a fundamental mechanism for navigation by intelligent embodied agents, whether they be biological or artificial. Unlike animal navigation, we can judiciously design the agent's perceptual system and control the learning paradigm to nullify alternative navigation mechanisms. Specifically, we train 'blind' agents -- with sensing limited to only egomotion and no other sensing of any kind -- to perform PointGoal navigation ('go to $\Delta$ x, $\Delta$ y') via reinforcement learning. Our agents are composed of navigation-agnostic components (fully-connected and recurrent neural networks), and our experimental setup provides no inductive bias towards mapping. Despite these harsh conditions, we find that blind agents are (1) surprisingly effective navigators in new environments (~95% success); (2) they utilize memory over long horizons (remembering ~1,000 steps of past experience in an episode); (3) this memory enables them to exhibit intelligent behavior (following walls, detecting collisions, taking shortcuts); (4) there is emergence of maps and collision detection neurons in the representations of the environment built by a blind agent as it navigates; and (5) the emergent maps are selective and task dependent (e.g. the agent 'forgets' exploratory detours). Overall, this paper presents no new techniques for the AI audience, but a surprising finding, an insight, and an explanation.
PIRLNav: Pretraining with Imitation and RL Finetuning for ObjectNav
Jan 18, 2023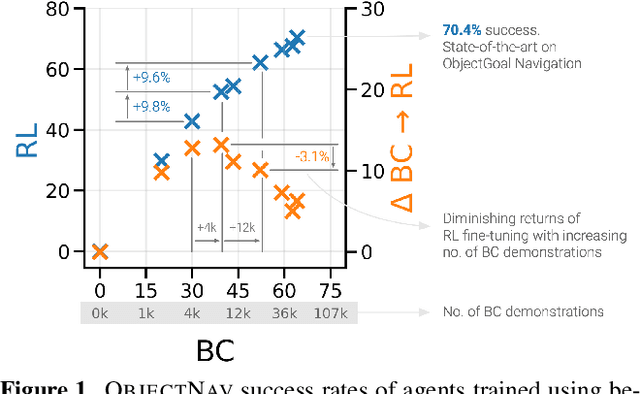

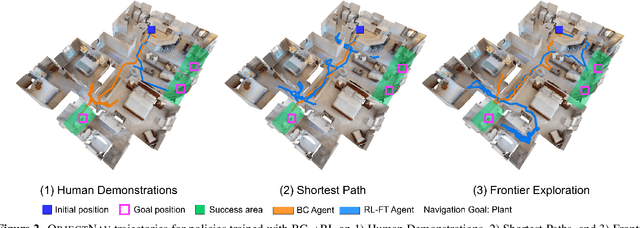
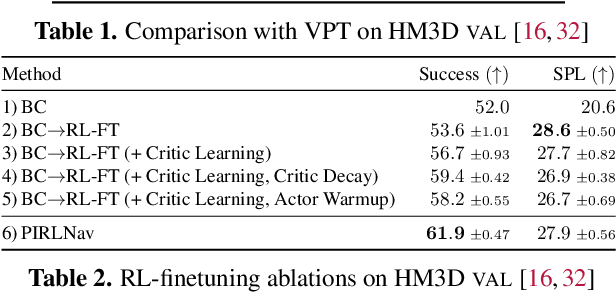
We study ObjectGoal Navigation - where a virtual robot situated in a new environment is asked to navigate to an object. Prior work has shown that imitation learning (IL) on a dataset of human demonstrations achieves promising results. However, this has limitations $-$ 1) IL policies generalize poorly to new states, since the training mimics actions not their consequences, and 2) collecting demonstrations is expensive. On the other hand, reinforcement learning (RL) is trivially scalable, but requires careful reward engineering to achieve desirable behavior. We present a two-stage learning scheme for IL pretraining on human demonstrations followed by RL-finetuning. This leads to a PIRLNav policy that advances the state-of-the-art on ObjectNav from $60.0\%$ success rate to $65.0\%$ ($+5.0\%$ absolute). Using this IL$\rightarrow$RL training recipe, we present a rigorous empirical analysis of design choices. First, we investigate whether human demonstrations can be replaced with `free' (automatically generated) sources of demonstrations, e.g. shortest paths (SP) or task-agnostic frontier exploration (FE) trajectories. We find that IL$\rightarrow$RL on human demonstrations outperforms IL$\rightarrow$RL on SP and FE trajectories, even when controlled for the same IL-pretraining success on TRAIN, and even on a subset of VAL episodes where IL-pretraining success favors the SP or FE policies. Next, we study how RL-finetuning performance scales with the size of the IL pretraining dataset. We find that as we increase the size of the IL-pretraining dataset and get to high IL accuracies, the improvements from RL-finetuning are smaller, and that $90\%$ of the performance of our best IL$\rightarrow$RL policy can be achieved with less than half the number of IL demonstrations. Finally, we analyze failure modes of our ObjectNav policies, and present guidelines for further improving them.
VER: Scaling On-Policy RL Leads to the Emergence of Navigation in Embodied Rearrangement
Oct 11, 2022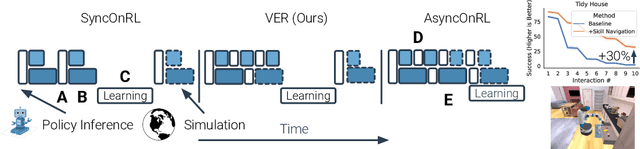
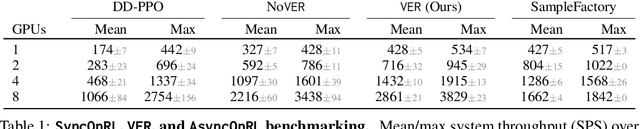
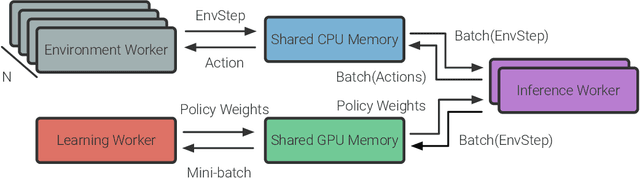

We present Variable Experience Rollout (VER), a technique for efficiently scaling batched on-policy reinforcement learning in heterogenous environments (where different environments take vastly different times to generate rollouts) to many GPUs residing on, potentially, many machines. VER combines the strengths of and blurs the line between synchronous and asynchronous on-policy RL methods (SyncOnRL and AsyncOnRL, respectively). VER learns from on-policy experience (like SyncOnRL) and has no synchronization points (like AsyncOnRL). VER leads to significant and consistent speed-ups across a broad range of embodied navigation and mobile manipulation tasks in photorealistic 3D simulation environments. Specifically, for PointGoal navigation and ObjectGoal navigation in Habitat 1.0, VER is 60-100% faster (1.6-2x speedup) than DD-PPO, the current state of art distributed SyncOnRL, with similar sample efficiency. For mobile manipulation tasks (open fridge/cabinet, pick/place objects) in Habitat 2.0 VER is 150% faster (2.5x speedup) on 1 GPU and 170% faster (2.7x speedup) on 8 GPUs than DD-PPO. Compared to SampleFactory (the current state-of-the-art AsyncOnRL), VER matches its speed on 1 GPU, and is 70% faster (1.7x speedup) on 8 GPUs with better sample efficiency. We leverage these speed-ups to train chained skills for GeometricGoal rearrangement tasks in the Home Assistant Benchmark (HAB). We find a surprising emergence of navigation in skills that do not ostensible require any navigation. Specifically, the Pick skill involves a robot picking an object from a table. During training the robot was always spawned close to the table and never needed to navigate. However, we find that if base movement is part of the action space, the robot learns to navigate then pick an object in new environments with 50% success, demonstrating surprisingly high out-of-distribution generalization.
Is Mapping Necessary for Realistic PointGoal Navigation?
Jun 07, 2022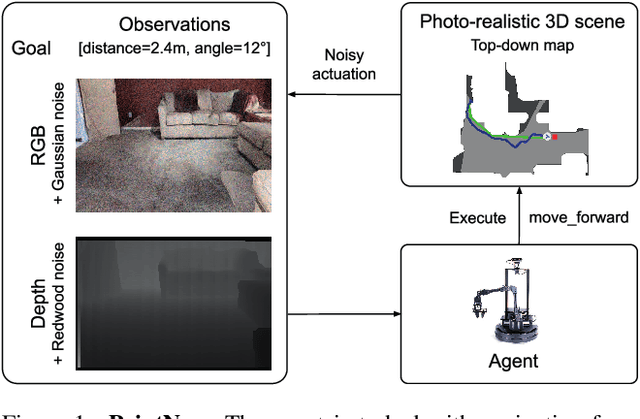
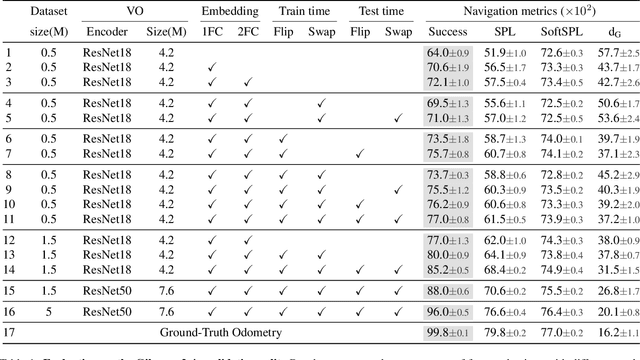
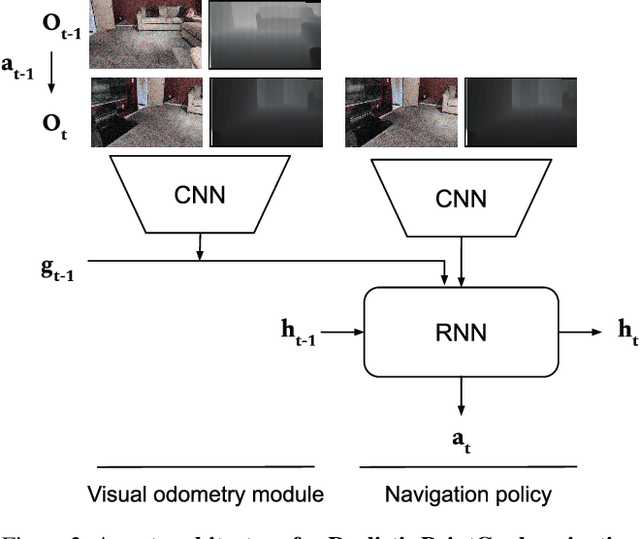
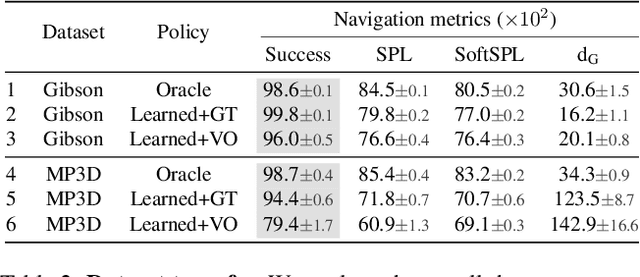
Can an autonomous agent navigate in a new environment without building an explicit map? For the task of PointGoal navigation ('Go to $\Delta x$, $\Delta y$') under idealized settings (no RGB-D and actuation noise, perfect GPS+Compass), the answer is a clear 'yes' - map-less neural models composed of task-agnostic components (CNNs and RNNs) trained with large-scale reinforcement learning achieve 100% Success on a standard dataset (Gibson). However, for PointNav in a realistic setting (RGB-D and actuation noise, no GPS+Compass), this is an open question; one we tackle in this paper. The strongest published result for this task is 71.7% Success. First, we identify the main (perhaps, only) cause of the drop in performance: the absence of GPS+Compass. An agent with perfect GPS+Compass faced with RGB-D sensing and actuation noise achieves 99.8% Success (Gibson-v2 val). This suggests that (to paraphrase a meme) robust visual odometry is all we need for realistic PointNav; if we can achieve that, we can ignore the sensing and actuation noise. With that as our operating hypothesis, we scale the dataset and model size, and develop human-annotation-free data-augmentation techniques to train models for visual odometry. We advance the state of art on the Habitat Realistic PointNav Challenge from 71% to 94% Success (+23, 31% relative) and 53% to 74% SPL (+21, 40% relative). While our approach does not saturate or 'solve' this dataset, this strong improvement combined with promising zero-shot sim2real transfer (to a LoCoBot) provides evidence consistent with the hypothesis that explicit mapping may not be necessary for navigation, even in a realistic setting.
Realistic PointGoal Navigation via Auxiliary Losses and Information Bottleneck
Sep 17, 2021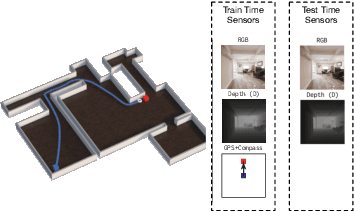
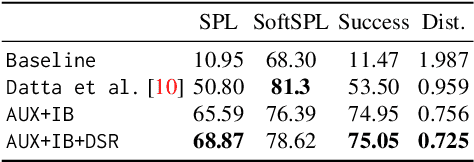
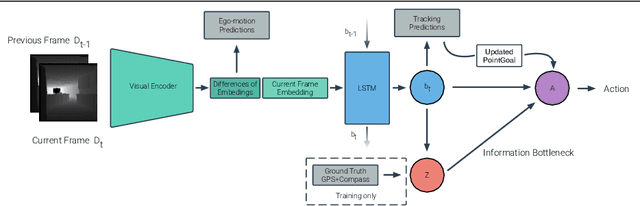
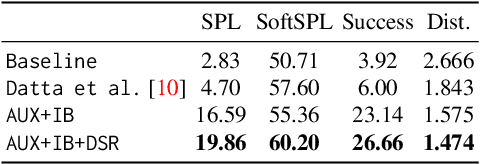
We propose a novel architecture and training paradigm for training realistic PointGoal Navigation -- navigating to a target coordinate in an unseen environment under actuation and sensor noise without access to ground-truth localization. Specifically, we find that the primary challenge under this setting is learning localization -- when stripped of idealized localization, agents fail to stop precisely at the goal despite reliably making progress towards it. To address this we introduce a set of auxiliary losses to help the agent learn localization. Further, we explore the idea of treating the precise location of the agent as privileged information -- it is unavailable during test time, however, it is available during training time in simulation. We grant the agent restricted access to ground-truth localization readings during training via an information bottleneck. Under this setting, the agent incurs a penalty for using this privileged information, encouraging the agent to only leverage this information when it is crucial to learning. This enables the agent to first learn navigation and then learn localization instead of conflating these two objectives in training. We evaluate our proposed method both in a semi-idealized (noiseless simulation without Compass+GPS) and realistic (addition of noisy simulation) settings. Specifically, our method outperforms existing baselines on the semi-idealized setting by 18\%/21\% SPL/Success and by 15\%/20\% SPL in the realistic setting. Our improved Success and SPL metrics indicate our agent's improved ability to accurately self-localize while maintaining a strong navigation policy. Our implementation can be found at https://github.com/NicoGrande/habitat-pointnav-via-ib.
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Sep 16, 2021

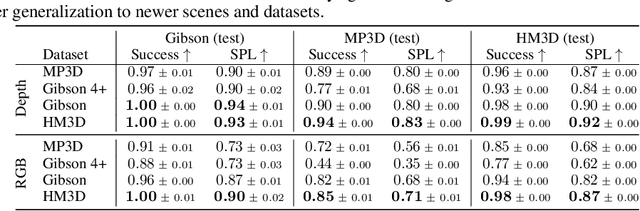
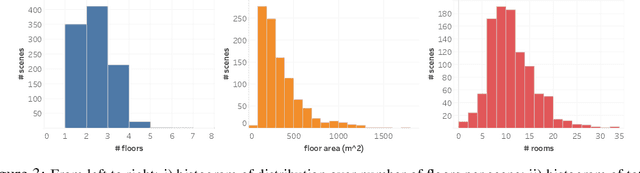
We present the Habitat-Matterport 3D (HM3D) dataset. HM3D is a large-scale dataset of 1,000 building-scale 3D reconstructions from a diverse set of real-world locations. Each scene in the dataset consists of a textured 3D mesh reconstruction of interiors such as multi-floor residences, stores, and other private indoor spaces. HM3D surpasses existing datasets available for academic research in terms of physical scale, completeness of the reconstruction, and visual fidelity. HM3D contains 112.5k m^2 of navigable space, which is 1.4 - 3.7x larger than other building-scale datasets such as MP3D and Gibson. When compared to existing photorealistic 3D datasets such as Replica, MP3D, Gibson, and ScanNet, images rendered from HM3D have 20 - 85% higher visual fidelity w.r.t. counterpart images captured with real cameras, and HM3D meshes have 34 - 91% fewer artifacts due to incomplete surface reconstruction. The increased scale, fidelity, and diversity of HM3D directly impacts the performance of embodied AI agents trained using it. In fact, we find that HM3D is `pareto optimal' in the following sense -- agents trained to perform PointGoal navigation on HM3D achieve the highest performance regardless of whether they are evaluated on HM3D, Gibson, or MP3D. No similar claim can be made about training on other datasets. HM3D-trained PointNav agents achieve 100% performance on Gibson-test dataset, suggesting that it might be time to retire that episode dataset.