 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Experience Required: Plug & Play Modular Transfer Learning for Semantic Visual Navigation
Feb 05, 2022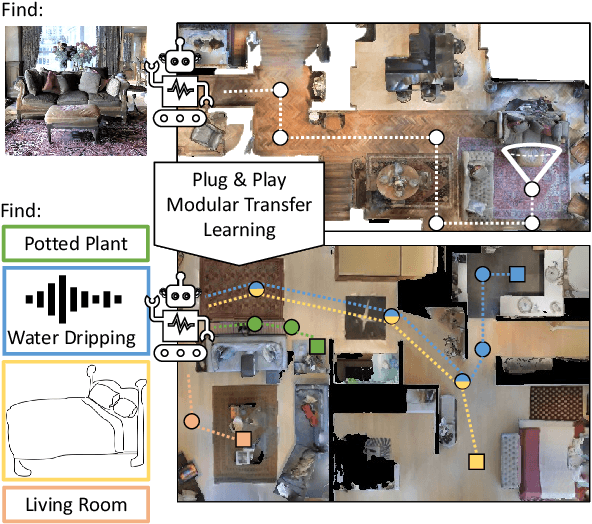
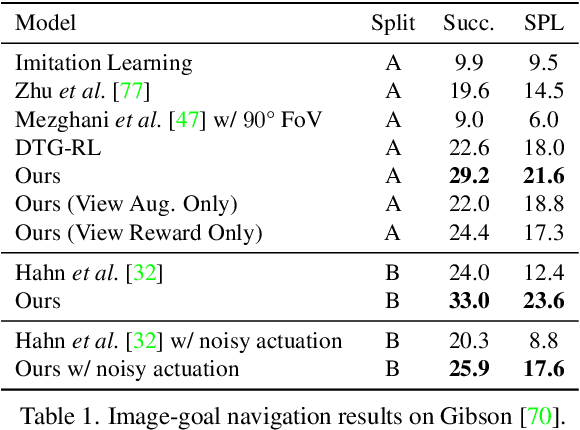
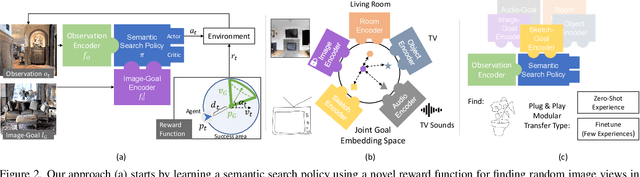
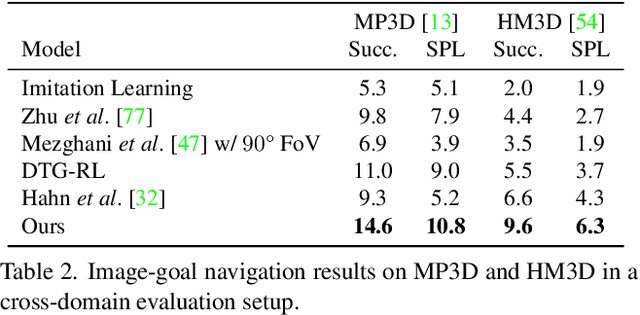
In reinforcement learning for visual navigation, it is common to develop a model for each new task, and train that model from scratch with task-specific interactions in 3D environments. However, this process is expensive; massive amounts of interactions are needed for the model to generalize well. Moreover, this process is repeated whenever there is a change in the task type or the goal modality. We present a unified approach to visual navigation using a novel modular transfer learning model. Our model can effectively leverage its experience from one source task and apply it to multiple target tasks (e.g., ObjectNav, RoomNav, ViewNav) with various goal modalities (e.g., image, sketch, audio, label). Furthermore, our model enables zero-shot experience learning, whereby it can solve the target tasks without receiving any task-specific interactive training. Our experiments on multiple photorealistic datasets and challenging tasks show that our approach learns faster, generalizes better, and outperforms SoTA models by a significant margin.
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Sep 16, 2021

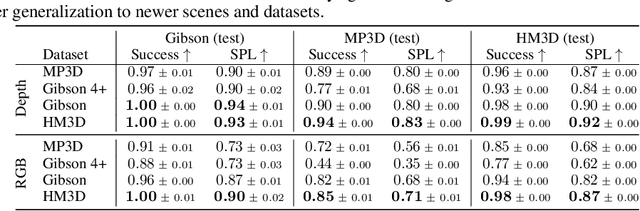
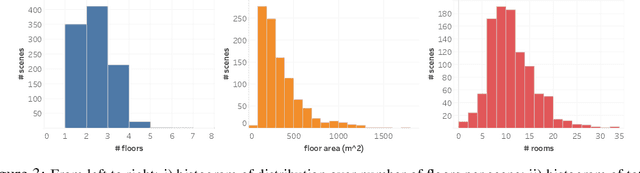
We present the Habitat-Matterport 3D (HM3D) dataset. HM3D is a large-scale dataset of 1,000 building-scale 3D reconstructions from a diverse set of real-world locations. Each scene in the dataset consists of a textured 3D mesh reconstruction of interiors such as multi-floor residences, stores, and other private indoor spaces. HM3D surpasses existing datasets available for academic research in terms of physical scale, completeness of the reconstruction, and visual fidelity. HM3D contains 112.5k m^2 of navigable space, which is 1.4 - 3.7x larger than other building-scale datasets such as MP3D and Gibson. When compared to existing photorealistic 3D datasets such as Replica, MP3D, Gibson, and ScanNet, images rendered from HM3D have 20 - 85% higher visual fidelity w.r.t. counterpart images captured with real cameras, and HM3D meshes have 34 - 91% fewer artifacts due to incomplete surface reconstruction. The increased scale, fidelity, and diversity of HM3D directly impacts the performance of embodied AI agents trained using it. In fact, we find that HM3D is `pareto optimal' in the following sense -- agents trained to perform PointGoal navigation on HM3D achieve the highest performance regardless of whether they are evaluated on HM3D, Gibson, or MP3D. No similar claim can be made about training on other datasets. HM3D-trained PointNav agents achieve 100% performance on Gibson-test dataset, suggesting that it might be time to retire that episode dataset.
Environment Predictive Coding for Embodied Agents
Feb 03, 2021
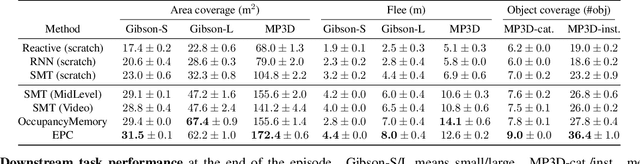
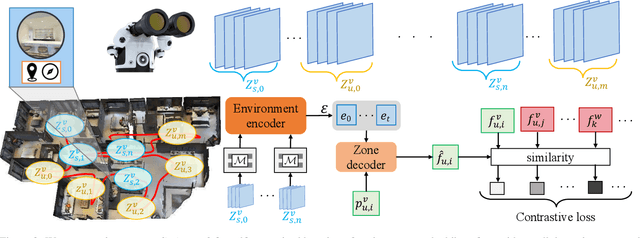

We introduce environment predictive coding, a self-supervised approach to learn environment-level representations for embodied agents. In contrast to prior work on self-supervised learning for images, we aim to jointly encode a series of images gathered by an agent as it moves about in 3D environments. We learn these representations via a zone prediction task, where we intelligently mask out portions of an agent's trajectory and predict them from the unmasked portions, conditioned on the agent's camera poses. By learning such representations on a collection of videos, we demonstrate successful transfer to multiple downstream navigation-oriented tasks. Our experiments on the photorealistic 3D environments of Gibson and Matterport3D show that our method outperforms the state-of-the-art on challenging tasks with only a limited budget of experience.
Occupancy Anticipation for Efficient Exploration and Navigation
Aug 25, 2020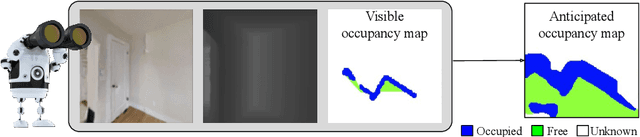
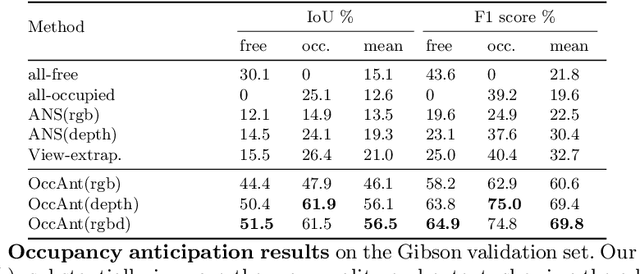
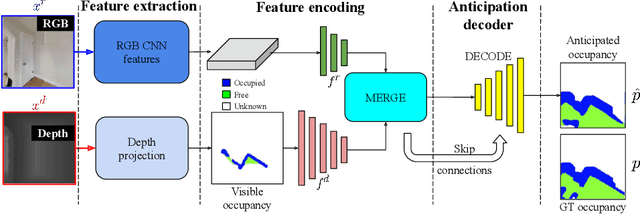
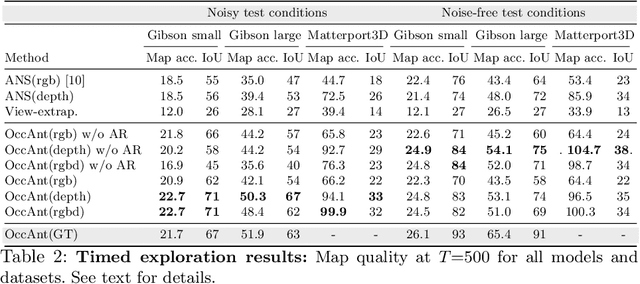
State-of-the-art navigation methods leverage a spatial memory to generalize to new environments, but their occupancy maps are limited to capturing the geometric structures directly observed by the agent. We propose occupancy anticipation, where the agent uses its egocentric RGB-D observations to infer the occupancy state beyond the visible regions. In doing so, the agent builds its spatial awareness more rapidly, which facilitates efficient exploration and navigation in 3D environments. By exploiting context in both the egocentric views and top-down maps our model successfully anticipates a broader map of the environment, with performance significantly better than strong baselines. Furthermore, when deployed for the sequential decision-making tasks of exploration and navigation, our model outperforms state-of-the-art methods on the Gibson and Matterport3D datasets. Our approach is the winning entry in the 2020 Habitat PointNav Challenge. Project page: http://vision.cs.utexas.edu/projects/occupancy_anticipation/
An Exploration of Embodied Visual Exploration
Jan 07, 2020
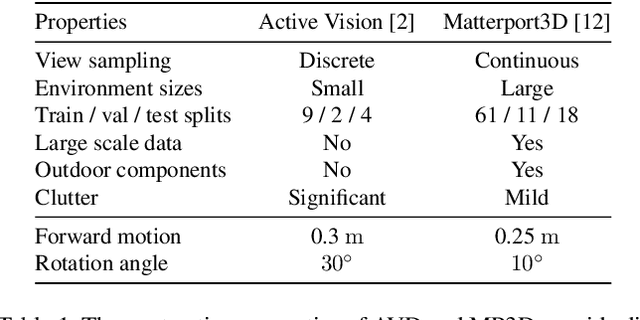

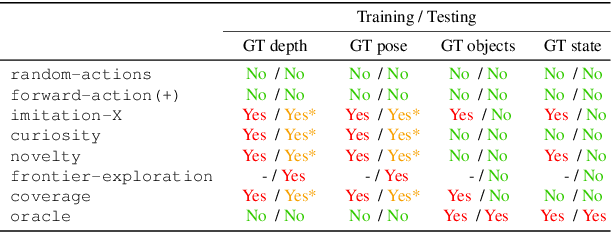
Embodied computer vision considers perception for robots in general, unstructured environments. Of particular importance is the embodied visual exploration problem: how might a robot equipped with a camera scope out a new environment? Despite the progress thus far, many basic questions pertinent to this problem remain unanswered: (i) What does it mean for an agent to explore its environment well? (ii) Which methods work well, and under which assumptions and environmental settings? (iii) Where do current approaches fall short, and where might future work seek to improve? Seeking answers to these questions, we perform a thorough empirical study of four state-of-the-art paradigms on two photorealistic simulated 3D environments. We present a taxonomy of key exploration methods and a standard framework for benchmarking visual exploration algorithms. Our experimental results offer insights, and suggest new performance metrics and baselines for future work in visual exploration.
Emergence of Exploratory Look-Around Behaviors through Active Observation Completion
Jun 27, 2019
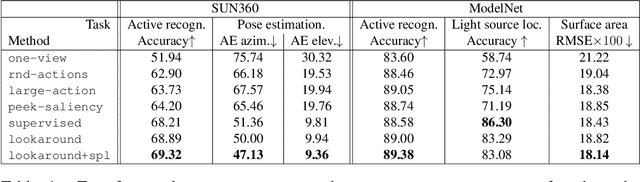

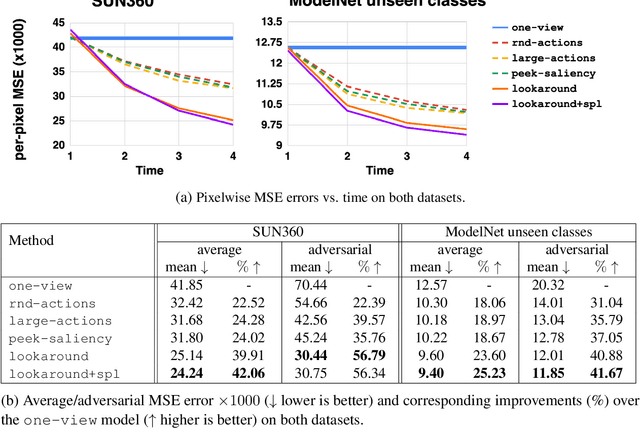
Standard computer vision systems assume access to intelligently captured inputs (e.g., photos from a human photographer), yet autonomously capturing good observations is a major challenge in itself. We address the problem of learning to look around: how can an agent learn to acquire informative visual observations? We propose a reinforcement learning solution, where the agent is rewarded for reducing its uncertainty about the unobserved portions of its environment. Specifically, the agent is trained to select a short sequence of glimpses after which it must infer the appearance of its full environment. To address the challenge of sparse rewards, we further introduce sidekick policy learning, which exploits the asymmetry in observability between training and test time. The proposed methods learn observation policies that not only perform the completion task for which they are trained, but also generalize to exhibit useful "look-around" behavior for a range of active perception tasks.
Sidekick Policy Learning for Active Visual Exploration
Jul 29, 2018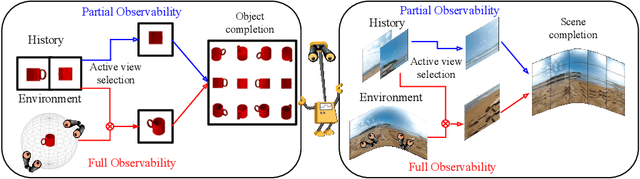
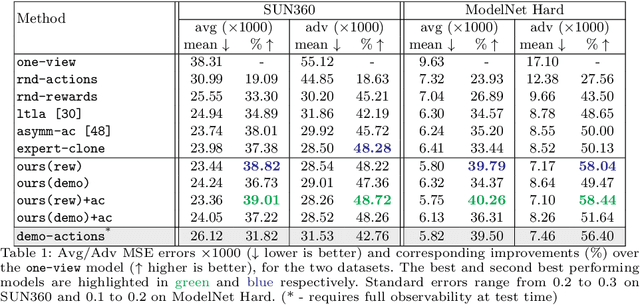

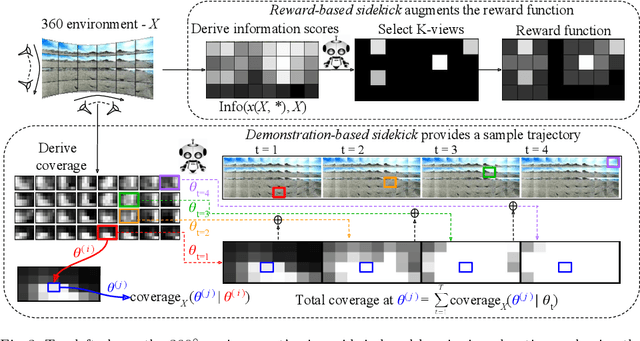
We consider an active visual exploration scenario, where an agent must intelligently select its camera motions to efficiently reconstruct the full environment from only a limited set of narrow field-of-view glimpses. While the agent has full observability of the environment during training, it has only partial observability once deployed, being constrained by what portions it has seen and what camera motions are permissible. We introduce sidekick policy learning to capitalize on this imbalance of observability. The main idea is a preparatory learning phase that attempts simplified versions of the eventual exploration task, then guides the agent via reward shaping or initial policy supervision. To support interpretation of the resulting policies, we also develop a novel policy visualization technique. Results on active visual exploration tasks with 360 scenes and 3D objects show that sidekicks consistently improve performance and convergence rates over existing methods. Code, data and demos are available.
CoMaL Tracking: Tracking Points at the Object Boundaries
Jun 07, 2017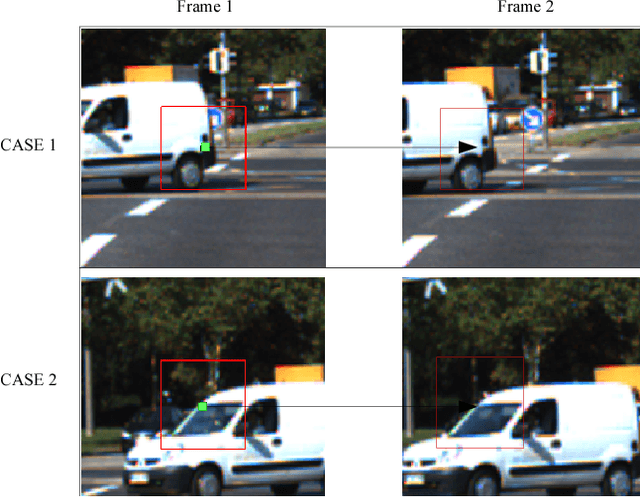
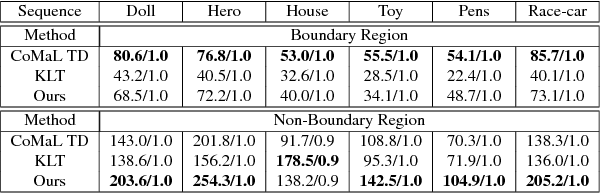
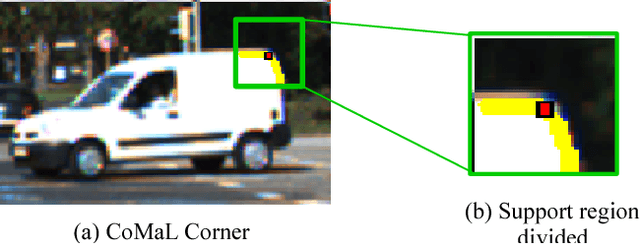
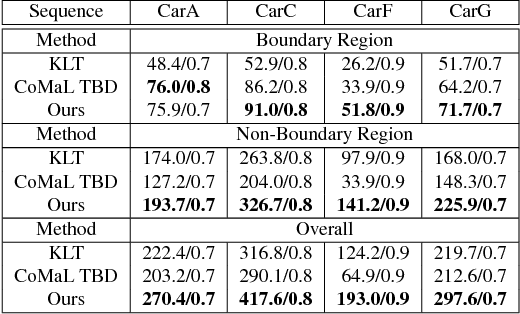
Traditional point tracking algorithms such as the KLT use local 2D information aggregation for feature detection and tracking, due to which their performance degrades at the object boundaries that separate multiple objects. Recently, CoMaL Features have been proposed that handle such a case. However, they proposed a simple tracking framework where the points are re-detected in each frame and matched. This is inefficient and may also lose many points that are not re-detected in the next frame. We propose a novel tracking algorithm to accurately and efficiently track CoMaL points. For this, the level line segment associated with the CoMaL points is matched to MSER segments in the next frame using shape-based matching and the matches are further filtered using texture-based matching. Experiments show improvements over a simple re-detect-and-match framework as well as KLT in terms of speed/accuracy on different real-world applications, especially at the object boundaries.
An Empirical Evaluation of Visual Question Answering for Novel Objects
Apr 08, 2017

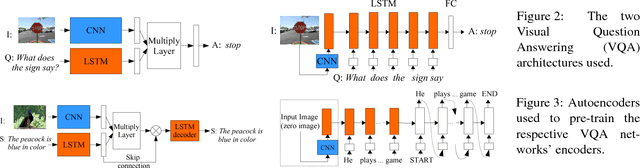
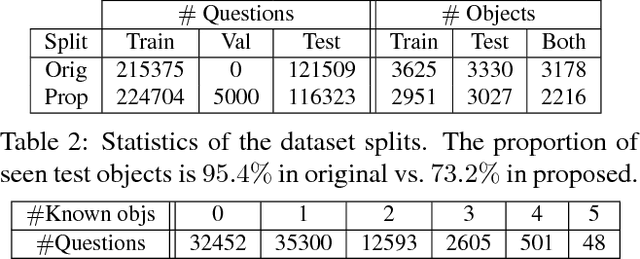
We study the problem of answering questions about images in the harder setting, where the test questions and corresponding images contain novel objects, which were not queried about in the training data. Such setting is inevitable in real world-owing to the heavy tailed distribution of the visual categories, there would be some objects which would not be annotated in the train set. We show that the performance of two popular existing methods drop significantly (up to 28%) when evaluated on novel objects cf. known objects. We propose methods which use large existing external corpora of (i) unlabeled text, i.e. books, and (ii) images tagged with classes, to achieve novel object based visual question answering. We do systematic empirical studies, for both an oracle case where the novel objects are known textually, as well as a fully automatic case without any explicit knowledge of the novel objects, but with the minimal assumption that the novel objects are semantically related to the existing objects in training. The proposed methods for novel object based visual question answering are modular and can potentially be used with many visual question answering architectures. We show consistent improvements with the two popular architectures and give qualitative analysis of the cases where the model does well and of those where it fails to bring improvements.