 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Sep 16, 2021

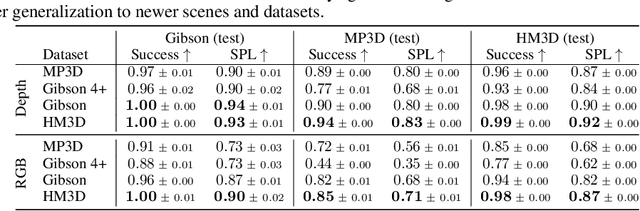
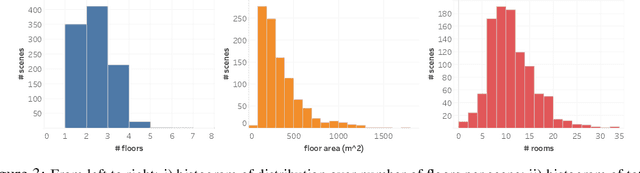
We present the Habitat-Matterport 3D (HM3D) dataset. HM3D is a large-scale dataset of 1,000 building-scale 3D reconstructions from a diverse set of real-world locations. Each scene in the dataset consists of a textured 3D mesh reconstruction of interiors such as multi-floor residences, stores, and other private indoor spaces. HM3D surpasses existing datasets available for academic research in terms of physical scale, completeness of the reconstruction, and visual fidelity. HM3D contains 112.5k m^2 of navigable space, which is 1.4 - 3.7x larger than other building-scale datasets such as MP3D and Gibson. When compared to existing photorealistic 3D datasets such as Replica, MP3D, Gibson, and ScanNet, images rendered from HM3D have 20 - 85% higher visual fidelity w.r.t. counterpart images captured with real cameras, and HM3D meshes have 34 - 91% fewer artifacts due to incomplete surface reconstruction. The increased scale, fidelity, and diversity of HM3D directly impacts the performance of embodied AI agents trained using it. In fact, we find that HM3D is `pareto optimal' in the following sense -- agents trained to perform PointGoal navigation on HM3D achieve the highest performance regardless of whether they are evaluated on HM3D, Gibson, or MP3D. No similar claim can be made about training on other datasets. HM3D-trained PointNav agents achieve 100% performance on Gibson-test dataset, suggesting that it might be time to retire that episode dataset.
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


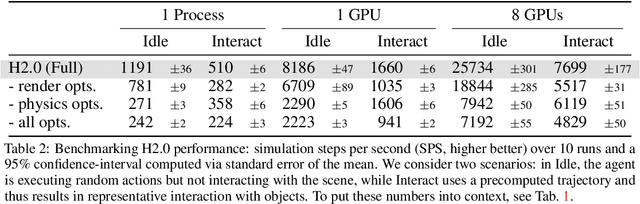
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.