 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRM: Joint Reconstruction Model for Multiple Objects without Alignment
Mar 27, 2026Object-centric reconstruction seeks to recover the 3D structure of a scene through composition of independent objects. While this independence can simplify modeling, it discards strong signals that could improve reconstruction, notably repetition where the same object model is seen multiple times in a scene, or across scans. We propose the Joint Reconstruction Model (JRM) to leverage repetition by framing object reconstruction as one of personalized generation: multiple observations share a common subject that should be consistent for all observations, while still adhering to the specific pose and state from each. Prior methods in this direction rely on explicit matching and rigid alignment across observations, making them sensitive to errors and difficult to extend to non-rigid transformations. In contrast, JRM is a 3D flow-matching generative model that implicitly aggregates unaligned observations in its latent space, learning to produce consistent and faithful reconstructions in a data-driven manner without explicit constraints. Evaluations on synthetic and real-world data show that JRM's implicit aggregation removes the need for explicit alignment, improves robustness to incorrect associations, and naturally handles non-rigid changes such as articulation. Overall, JRM outperforms both independent and alignment-based baselines in reconstruction quality.
NuiWorld: Exploring a Scalable Framework for End-to-End Controllable World Generation
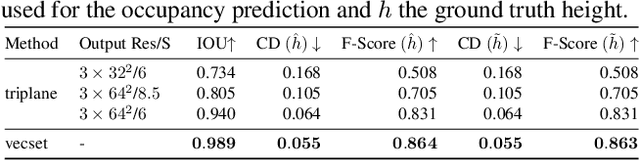
Jan 27, 2026World generation is a fundamental capability for applications like video games, simulation, and robotics. However, existing approaches face three main obstacles: controllability, scalability, and efficiency. End-to-end scene generation models have been limited by data scarcity. While object-centric generation approaches rely on fixed resolution representations, degrading fidelity for larger scenes. Training-free approaches, while flexible, are often slow and computationally expensive at inference time. We present NuiWorld, a framework that attempts to address these challenges. To overcome data scarcity, we propose a generative bootstrapping strategy that starts from a few input images. Leveraging recent 3D reconstruction and expandable scene generation techniques, we synthesize scenes of varying sizes and layouts, producing enough data to train an end-to-end model. Furthermore, our framework enables controllability through pseudo sketch labels, and demonstrates a degree of generalization to previously unseen sketches. Our approach represents scenes as a collection of variable scene chunks, which are compressed into a flattened vector-set representation. This significantly reduces the token length for large scenes, enabling consistent geometric fidelity across scenes sizes while improving training and inference efficiency.
LangNavBench: Evaluation of Natural Language Understanding in Semantic Navigation
Jul 09, 2025Recent progress in large vision-language models has driven improvements in language-based semantic navigation, where an embodied agent must reach a target object described in natural language. Despite these advances, we still lack a clear, language-focused benchmark for testing how well such agents ground the words in their instructions. We address this gap with LangNav, an open-set dataset specifically created to test an agent's ability to locate objects described at different levels of detail, from broad category names to fine attributes and object-object relations. Every description in LangNav was manually checked, yielding a lower error rate than existing lifelong- and semantic-navigation datasets. On top of LangNav we build LangNavBench, a benchmark that measures how well current semantic-navigation methods understand and act on these descriptions while moving toward their targets. LangNavBench allows us to systematically compare models on their handling of attributes, spatial and relational cues, and category hierarchies, offering the first thorough, language-centric evaluation of embodied navigation systems. We also present Multi-Layered Feature Map (MLFM), a method that builds a queryable multi-layered semantic map, particularly effective when dealing with small objects or instructions involving spatial relations. MLFM outperforms state-of-the-art mapping-based navigation baselines on the LangNav dataset.
HSM: Hierarchical Scene Motifs for Multi-Scale Indoor Scene Generation
Mar 21, 2025
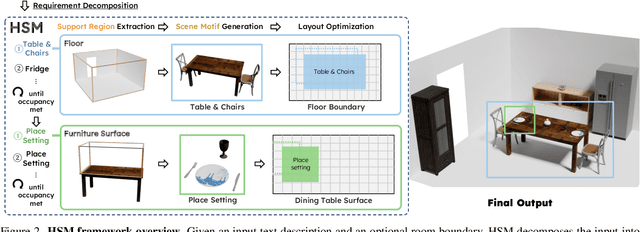

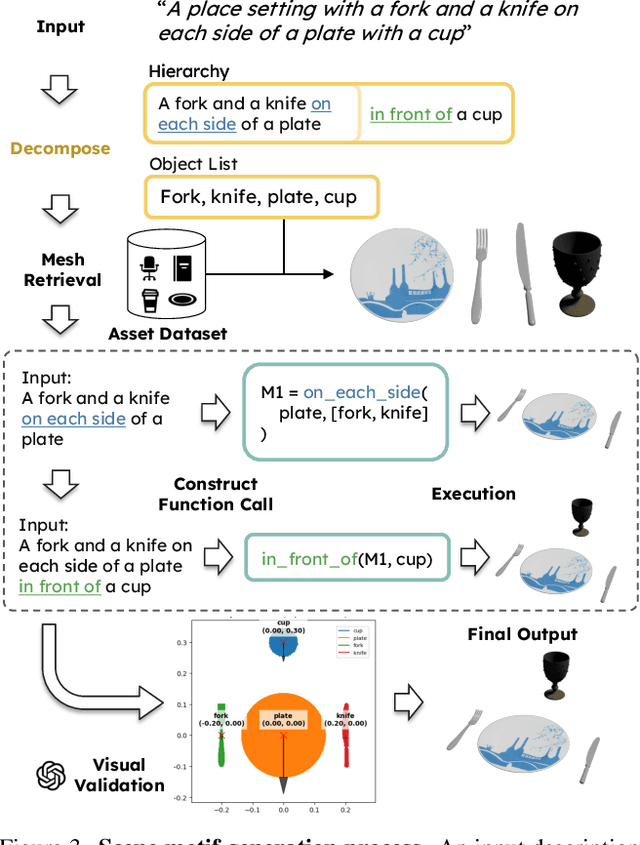
Despite advances in indoor 3D scene layout generation, synthesizing scenes with dense object arrangements remains challenging. Existing methods primarily focus on large furniture while neglecting smaller objects, resulting in unrealistically empty scenes. Those that place small objects typically do not honor arrangement specifications, resulting in largely random placement not following the text description. We present HSM, a hierarchical framework for indoor scene generation with dense object arrangements across spatial scales. Indoor scenes are inherently hierarchical, with surfaces supporting objects at different scales, from large furniture on floors to smaller objects on tables and shelves. HSM embraces this hierarchy and exploits recurring cross-scale spatial patterns to generate complex and realistic indoor scenes in a unified manner. Our experiments show that HSM outperforms existing methods by generating scenes that are more realistic and better conform to user input across room types and spatial configurations.
NuiScene: Exploring Efficient Generation of Unbounded Outdoor Scenes
Mar 20, 2025
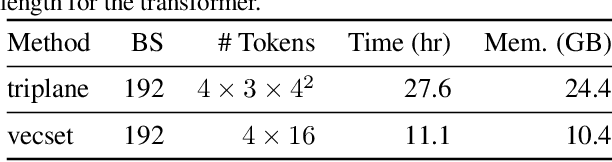
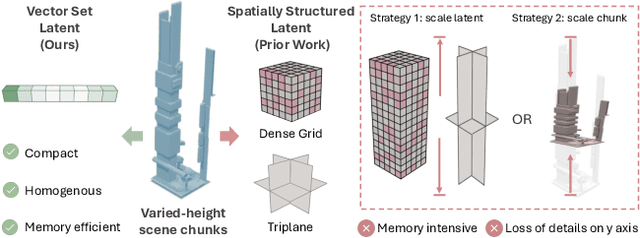
In this paper, we explore the task of generating expansive outdoor scenes, ranging from castles to high-rises. Unlike indoor scene generation, which has been a primary focus of prior work, outdoor scene generation presents unique challenges, including wide variations in scene heights and the need for a method capable of rapidly producing large landscapes. To address this, we propose an efficient approach that encodes scene chunks as uniform vector sets, offering better compression and performance than the spatially structured latents used in prior methods. Furthermore, we train an explicit outpainting model for unbounded generation, which improves coherence compared to prior resampling-based inpainting schemes while also speeding up generation by eliminating extra diffusion steps. To facilitate this task, we curate NuiScene43, a small but high-quality set of scenes, preprocessed for joint training. Notably, when trained on scenes of varying styles, our model can blend different environments, such as rural houses and city skyscrapers, within the same scene, highlighting the potential of our curation process to leverage heterogeneous scenes for joint training.
SceneEval: Evaluating Semantic Coherence in Text-Conditioned 3D Indoor Scene Synthesis
Mar 18, 2025
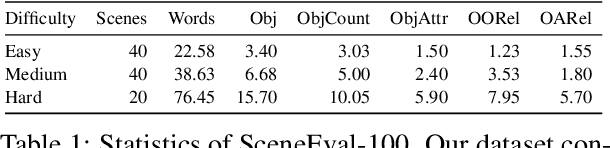
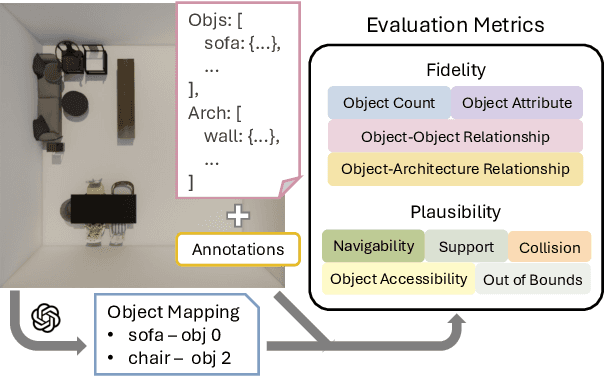

Despite recent advances in text-conditioned 3D indoor scene generation, there remain gaps in the evaluation of these methods. Existing metrics primarily assess the realism of generated scenes by comparing them to a set of ground-truth scenes, often overlooking alignment with the input text - a critical factor in determining how effectively a method meets user requirements. We present SceneEval, an evaluation framework designed to address this limitation. SceneEval includes metrics for both explicit user requirements, such as the presence of specific objects and their attributes described in the input text, and implicit expectations, like the absence of object collisions, providing a comprehensive assessment of scene quality. To facilitate evaluation, we introduce SceneEval-100, a dataset of scene descriptions with annotated ground-truth scene properties. We evaluate recent scene generation methods using SceneEval and demonstrate its ability to provide detailed assessments of the generated scenes, highlighting strengths and areas for improvement across multiple dimensions. Our results show that current methods struggle at generating scenes that meet user requirements, underscoring the need for further research in this direction.
Learning Object Placement Programs for Indoor Scene Synthesis with Iterative Self Training
Mar 06, 2025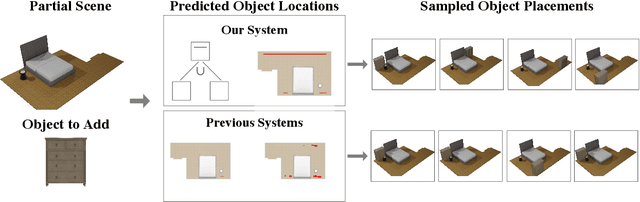
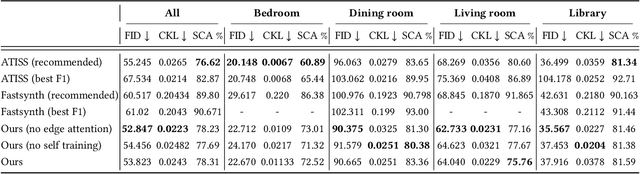
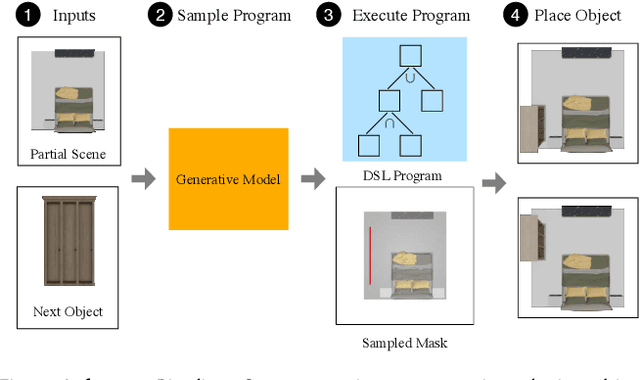
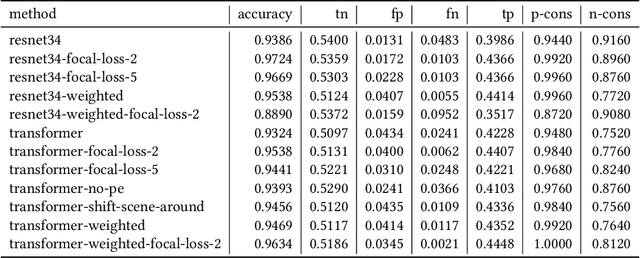
Data driven and autoregressive indoor scene synthesis systems generate indoor scenes automatically by suggesting and then placing objects one at a time. Empirical observations show that current systems tend to produce incomplete next object location distributions. We introduce a system which addresses this problem. We design a Domain Specific Language (DSL) that specifies functional constraints. Programs from our language take as input a partial scene and object to place. Upon execution they predict possible object placements. We design a generative model which writes these programs automatically. Available 3D scene datasets do not contain programs to train on, so we build upon previous work in unsupervised program induction to introduce a new program bootstrapping algorithm. In order to quantify our empirical observations we introduce a new evaluation procedure which captures how well a system models per-object location distributions. We ask human annotators to label all the possible places an object can go in a scene and show that our system produces per-object location distributions more consistent with human annotators. Our system also generates indoor scenes of comparable quality to previous systems and while previous systems degrade in performance when training data is sparse, our system does not degrade to the same degree.
Enhancing DNA Foundation Models to Address Masking Inefficiencies
Feb 25, 2025Masked language modelling (MLM) as a pretraining objective has been widely adopted in genomic sequence modelling. While pretrained models can successfully serve as encoders for various downstream tasks, the distribution shift between pretraining and inference detrimentally impacts performance, as the pretraining task is to map [MASK] tokens to predictions, yet the [MASK] is absent during downstream applications. This means the encoder does not prioritize its encodings of non-[MASK] tokens, and expends parameters and compute on work only relevant to the MLM task, despite this being irrelevant at deployment time. In this work, we propose a modified encoder-decoder architecture based on the masked autoencoder framework, designed to address this inefficiency within a BERT-based transformer. We empirically show that the resulting mismatch is particularly detrimental in genomic pipelines where models are often used for feature extraction without fine-tuning. We evaluate our approach on the BIOSCAN-5M dataset, comprising over 2 million unique DNA barcodes. We achieve substantial performance gains in both closed-world and open-world classification tasks when compared against causal models and bidirectional architectures pretrained with MLM tasks.
Semantic Mapping in Indoor Embodied AI -- A Comprehensive Survey and Future Directions
Jan 10, 2025



Intelligent embodied agents (e.g. robots) need to perform complex semantic tasks in unfamiliar environments. Among many skills that the agents need to possess, building and maintaining a semantic map of the environment is most crucial in long-horizon tasks. A semantic map captures information about the environment in a structured way, allowing the agent to reference it for advanced reasoning throughout the task. While existing surveys in embodied AI focus on general advancements or specific tasks like navigation and manipulation, this paper provides a comprehensive review of semantic map-building approaches in embodied AI, specifically for indoor navigation. We categorize these approaches based on their structural representation (spatial grids, topological graphs, dense point-clouds or hybrid maps) and the type of information they encode (implicit features or explicit environmental data). We also explore the strengths and limitations of the map building techniques, highlight current challenges, and propose future research directions. We identify that the field is moving towards developing open-vocabulary, queryable, task-agnostic map representations, while high memory demands and computational inefficiency still remaining to be open challenges. This survey aims to guide current and future researchers in advancing semantic mapping techniques for embodied AI systems.
ViGiL3D: A Linguistically Diverse Dataset for 3D Visual Grounding
Jan 02, 2025



3D visual grounding (3DVG) involves localizing entities in a 3D scene referred to by natural language text. Such models are useful for embodied AI and scene retrieval applications, which involve searching for objects or patterns using natural language descriptions. While recent works have focused on LLM-based scaling of 3DVG datasets, these datasets do not capture the full range of potential prompts which could be specified in the English language. To ensure that we are scaling up and testing against a useful and representative set of prompts, we propose a framework for linguistically analyzing 3DVG prompts and introduce Visual Grounding with Diverse Language in 3D (ViGiL3D), a diagnostic dataset for evaluating visual grounding methods against a diverse set of language patterns. We evaluate existing open-vocabulary 3DVG methods to demonstrate that these methods are not yet proficient in understanding and identifying the targets of more challenging, out-of-distribution prompts, toward real-world applications.