 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Placement Programs for Indoor Scene Synthesis with Iterative Self Training
Mar 06, 2025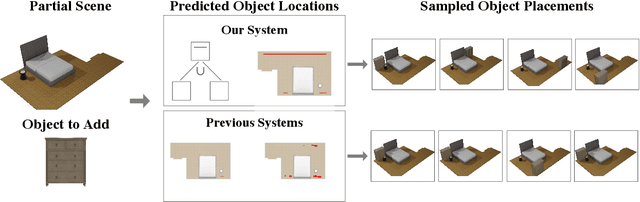
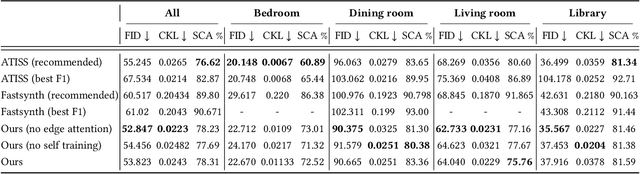
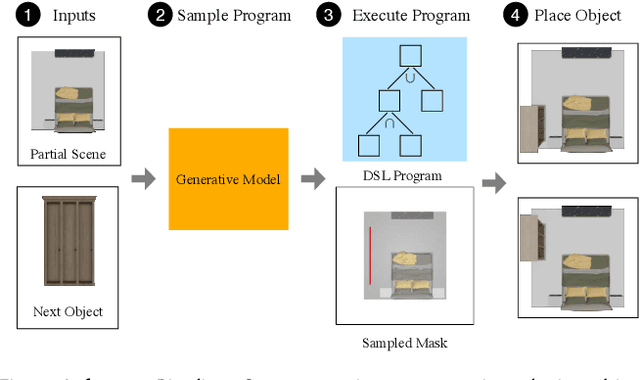
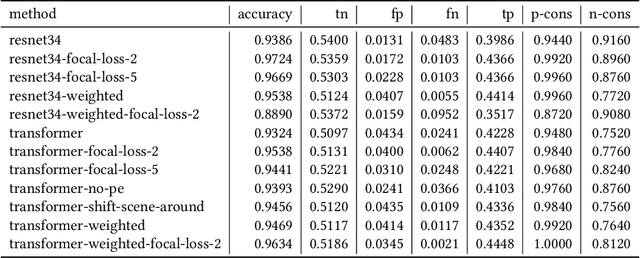
Data driven and autoregressive indoor scene synthesis systems generate indoor scenes automatically by suggesting and then placing objects one at a time. Empirical observations show that current systems tend to produce incomplete next object location distributions. We introduce a system which addresses this problem. We design a Domain Specific Language (DSL) that specifies functional constraints. Programs from our language take as input a partial scene and object to place. Upon execution they predict possible object placements. We design a generative model which writes these programs automatically. Available 3D scene datasets do not contain programs to train on, so we build upon previous work in unsupervised program induction to introduce a new program bootstrapping algorithm. In order to quantify our empirical observations we introduce a new evaluation procedure which captures how well a system models per-object location distributions. We ask human annotators to label all the possible places an object can go in a scene and show that our system produces per-object location distributions more consistent with human annotators. Our system also generates indoor scenes of comparable quality to previous systems and while previous systems degrade in performance when training data is sparse, our system does not degrade to the same degree.