 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction2Scene: 3D Indoor Scene Layout from Functional Specifications
May 29, 2026Most text-driven 3D indoor scene synthesis methods generate rooms from object-centric prompts, asking what furniture should be placed rather than how the space is used. Yet in real interior design, a layout is judged by how well it supports its occupants, e.g., their activities and physical needs. We introduce Function2Scene, a framework for generating 3D indoor layouts from functional specifications, i.e., natural-language design briefs describing who will use a room and what they need to do there. Given such a specification, our system parses occupant personas and activities, derives a customized set of functional design constraints from a taxonomy of 17 criteria spanning spatial, ergonomic, activity, and environmental considerations, and uses these constraints to guide layout generation. Rather than relying on an LLM to directly produce a final scene, Function2Scene performs iterative evaluation and refinement through a tool-augmented check-and-repair loop, combining geometric measurements, LLM-based contextual reasoning, and VLM-based visual assessment. Experiments on 30 professionally written interior-design cases show that Function2Scene produces layouts that better satisfy functional requirements than recent LLM-based scene synthesis baselines, with our results preferred in 94.3% of pairwise comparisons. Our work reframes text-driven indoor scene synthesis from placing plausible objects to designing spaces that support human use.
Artiverse: A Diverse and Physically Grounded Dataset for Articulated Objects
May 23, 2026We present Artiverse, a diverse and physically grounded dataset of high-quality articulated 3D objects designed for realistic functional modeling and simulation. Artiverse contains 5.4K human-authored objects across a broad range of 88 categories, aggregated from multiple 3D static repositories. Objects are annotated with functional parts, interior structures, realistic kinematic relationships and articulated joints including multi-DoF joints, and physical attributes such as metric scale, material, and mass. We develop a semi-automated annotation pipeline that combines few-shot segmentation, geometric reasoning, and multi-stage human verification to achieve high-quality and efficient annotation, reducing manual annotation time by over 30%. We demonstrate the value of Artiverse on tasks of part mobility analysis, articulated object generation, and physics-based interaction. Artiverse provides a data resource to advance functional understanding for articulated objects.
EgoFun3D: Modeling Interactive Objects from Egocentric Videos using Function Templates
Apr 13, 2026We present EgoFun3D, a coordinated task formulation, dataset, and benchmark for modeling interactive 3D objects from egocentric videos. Interactive objects are of high interest for embodied AI but scarce, making modeling from readily available real-world videos valuable. Our task focuses on obtaining simulation-ready interactive 3D objects from egocentric video input. While prior work largely focuses on articulations, we capture general cross-part functional mappings (e.g., rotation of stove knob controls stove burner temperature) through function templates, a structured computational representation. Function templates enable precise evaluation and direct compilation into executable code across simulation platforms. To enable comprehensive benchmarking, we introduce a dataset of 271 egocentric videos featuring challenging real-world interactions with paired 3D geometry, segmentation over 2D and 3D, articulation and function template annotations. To tackle the task, we propose a 4-stage pipeline consisting of: 2D part segmentation, reconstruction, articulation estimation, and function template inference. Comprehensive benchmarking shows that the task is challenging for off-the-shelf methods, highlighting avenues for future work.
LangNavBench: Evaluation of Natural Language Understanding in Semantic Navigation
Jul 09, 2025Recent progress in large vision-language models has driven improvements in language-based semantic navigation, where an embodied agent must reach a target object described in natural language. Despite these advances, we still lack a clear, language-focused benchmark for testing how well such agents ground the words in their instructions. We address this gap with LangNav, an open-set dataset specifically created to test an agent's ability to locate objects described at different levels of detail, from broad category names to fine attributes and object-object relations. Every description in LangNav was manually checked, yielding a lower error rate than existing lifelong- and semantic-navigation datasets. On top of LangNav we build LangNavBench, a benchmark that measures how well current semantic-navigation methods understand and act on these descriptions while moving toward their targets. LangNavBench allows us to systematically compare models on their handling of attributes, spatial and relational cues, and category hierarchies, offering the first thorough, language-centric evaluation of embodied navigation systems. We also present Multi-Layered Feature Map (MLFM), a method that builds a queryable multi-layered semantic map, particularly effective when dealing with small objects or instructions involving spatial relations. MLFM outperforms state-of-the-art mapping-based navigation baselines on the LangNav dataset.
Generalizable Articulated Object Reconstruction from Casually Captured RGBD Videos
Jun 10, 2025Articulated objects are prevalent in daily life. Understanding their kinematic structure and reconstructing them have numerous applications in embodied AI and robotics. However, current methods require carefully captured data for training or inference, preventing practical, scalable, and generalizable reconstruction of articulated objects. We focus on reconstruction of an articulated object from a casually captured RGBD video shot with a hand-held camera. A casually captured video of an interaction with an articulated object is easy to acquire at scale using smartphones. However, this setting is quite challenging, as the object and camera move simultaneously and there are significant occlusions as the person interacts with the object. To tackle these challenges, we introduce a coarse-to-fine framework that infers joint parameters and segments movable parts of the object from a dynamic RGBD video. To evaluate our method under this new setting, we build a 20$\times$ larger synthetic dataset of 784 videos containing 284 objects across 11 categories. We compare our approach with existing methods that also take video as input. Experiments show that our method can reconstruct synthetic and real articulated objects across different categories from dynamic RGBD videos, outperforming existing methods significantly.
Hybrid Neural-MPM for Interactive Fluid Simulations in Real-Time
May 25, 2025



We propose a neural physics system for real-time, interactive fluid simulations. Traditional physics-based methods, while accurate, are computationally intensive and suffer from latency issues. Recent machine-learning methods reduce computational costs while preserving fidelity; yet most still fail to satisfy the latency constraints for real-time use and lack support for interactive applications. To bridge this gap, we introduce a novel hybrid method that integrates numerical simulation, neural physics, and generative control. Our neural physics jointly pursues low-latency simulation and high physical fidelity by employing a fallback safeguard to classical numerical solvers. Furthermore, we develop a diffusion-based controller that is trained using a reverse modeling strategy to generate external dynamic force fields for fluid manipulation. Our system demonstrates robust performance across diverse 2D/3D scenarios, material types, and obstacle interactions, achieving real-time simulations at high frame rates (11~29% latency) while enabling fluid control guided by user-friendly freehand sketches. We present a significant step towards practical, controllable, and physically plausible fluid simulations for real-time interactive applications. We promise to release both models and data upon acceptance.
Digital Twin Generation from Visual Data: A Survey
Apr 17, 2025This survey explores recent developments in generating digital twins from videos. Such digital twins can be used for robotics application, media content creation, or design and construction works. We analyze various approaches, including 3D Gaussian Splatting, generative in-painting, semantic segmentation, and foundation models highlighting their advantages and limitations. Additionally, we discuss challenges such as occlusions, lighting variations, and scalability, as well as potential future research directions. This survey aims to provide a comprehensive overview of state-of-the-art methodologies and their implications for real-world applications. Awesome list: https://github.com/ndrwmlnk/awesome-digital-twins
HSM: Hierarchical Scene Motifs for Multi-Scale Indoor Scene Generation
Mar 21, 2025
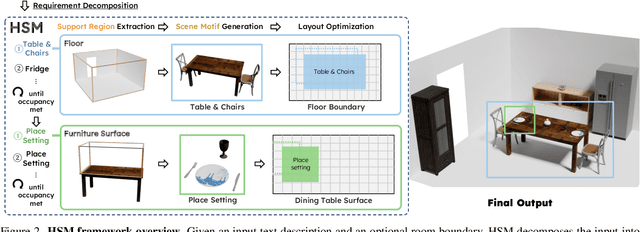

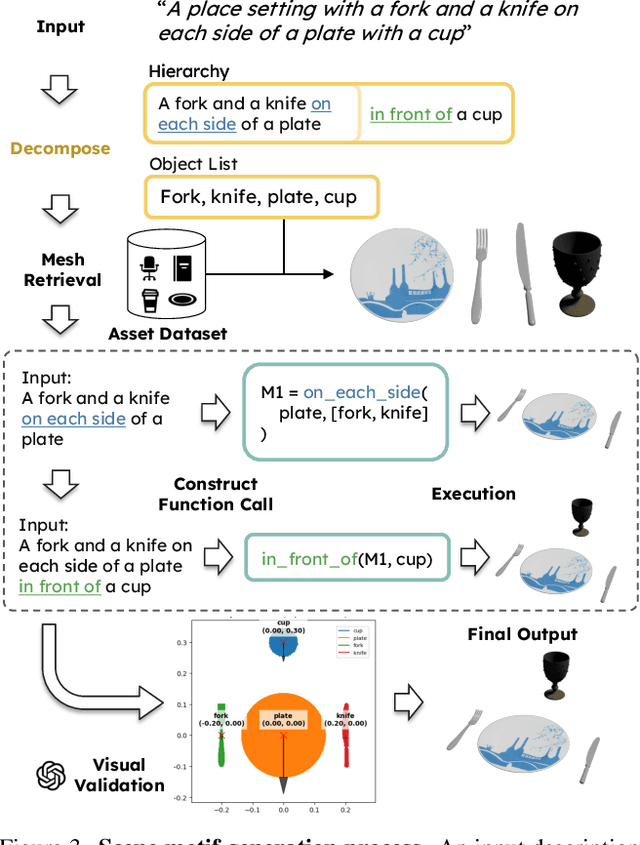
Despite advances in indoor 3D scene layout generation, synthesizing scenes with dense object arrangements remains challenging. Existing methods primarily focus on large furniture while neglecting smaller objects, resulting in unrealistically empty scenes. Those that place small objects typically do not honor arrangement specifications, resulting in largely random placement not following the text description. We present HSM, a hierarchical framework for indoor scene generation with dense object arrangements across spatial scales. Indoor scenes are inherently hierarchical, with surfaces supporting objects at different scales, from large furniture on floors to smaller objects on tables and shelves. HSM embraces this hierarchy and exploits recurring cross-scale spatial patterns to generate complex and realistic indoor scenes in a unified manner. Our experiments show that HSM outperforms existing methods by generating scenes that are more realistic and better conform to user input across room types and spatial configurations.
SceneEval: Evaluating Semantic Coherence in Text-Conditioned 3D Indoor Scene Synthesis
Mar 18, 2025
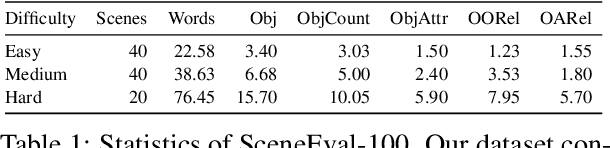
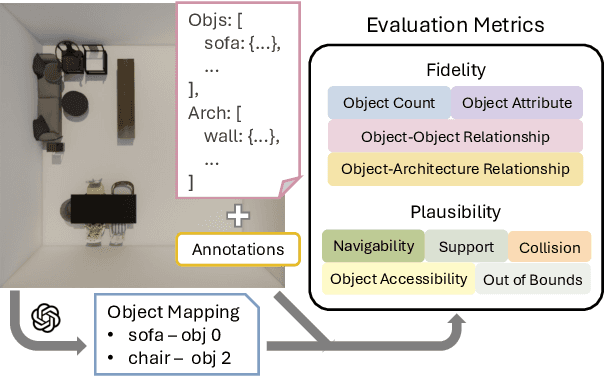

Despite recent advances in text-conditioned 3D indoor scene generation, there remain gaps in the evaluation of these methods. Existing metrics primarily assess the realism of generated scenes by comparing them to a set of ground-truth scenes, often overlooking alignment with the input text - a critical factor in determining how effectively a method meets user requirements. We present SceneEval, an evaluation framework designed to address this limitation. SceneEval includes metrics for both explicit user requirements, such as the presence of specific objects and their attributes described in the input text, and implicit expectations, like the absence of object collisions, providing a comprehensive assessment of scene quality. To facilitate evaluation, we introduce SceneEval-100, a dataset of scene descriptions with annotated ground-truth scene properties. We evaluate recent scene generation methods using SceneEval and demonstrate its ability to provide detailed assessments of the generated scenes, highlighting strengths and areas for improvement across multiple dimensions. Our results show that current methods struggle at generating scenes that meet user requirements, underscoring the need for further research in this direction.
Learning Object Placement Programs for Indoor Scene Synthesis with Iterative Self Training
Mar 06, 2025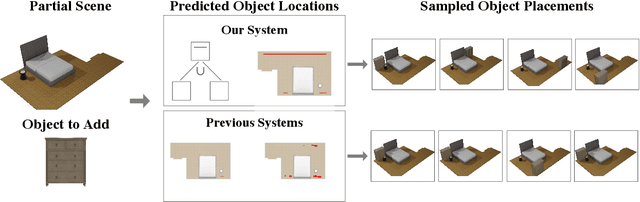
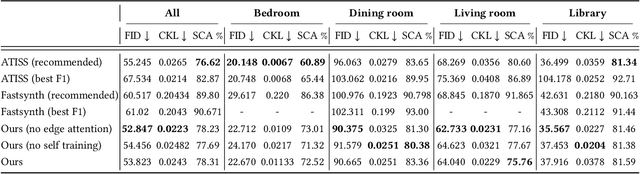
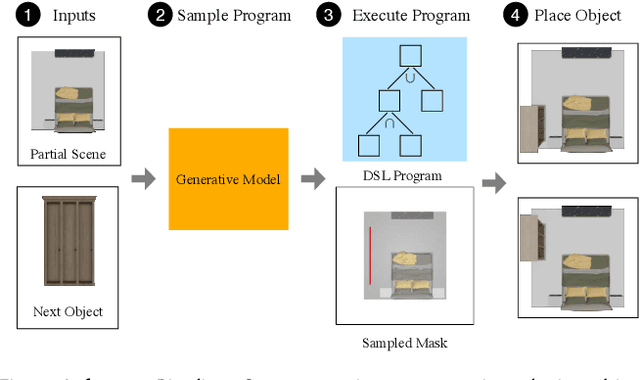
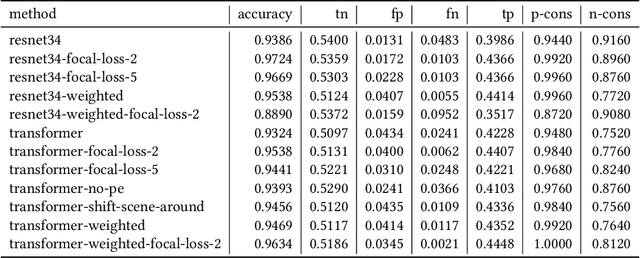
Data driven and autoregressive indoor scene synthesis systems generate indoor scenes automatically by suggesting and then placing objects one at a time. Empirical observations show that current systems tend to produce incomplete next object location distributions. We introduce a system which addresses this problem. We design a Domain Specific Language (DSL) that specifies functional constraints. Programs from our language take as input a partial scene and object to place. Upon execution they predict possible object placements. We design a generative model which writes these programs automatically. Available 3D scene datasets do not contain programs to train on, so we build upon previous work in unsupervised program induction to introduce a new program bootstrapping algorithm. In order to quantify our empirical observations we introduce a new evaluation procedure which captures how well a system models per-object location distributions. We ask human annotators to label all the possible places an object can go in a scene and show that our system produces per-object location distributions more consistent with human annotators. Our system also generates indoor scenes of comparable quality to previous systems and while previous systems degrade in performance when training data is sparse, our system does not degrade to the same degree.