 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring the Floor and Raising the Ceiling: A Merging-based Paradigm for Multi-modal Search Agents
Mar 02, 2026Recent advances in Vision-Language Models (VLMs) have motivated the development of multi-modal search agents that can actively invoke external search tools and integrate retrieved evidence through multi-step reasoning. While promising, existing approaches typically rely on large-scale supervised trajectories or expensive reinforcement learning (RL), leading to high training cost, instability, and a severe cold-start problem for standard VLMs. We propose a training-free paradigm to empower VLMs with autonomous search capabilities via cross-modal model merging. By fusing a text-based search agent with a base VLM, we show that multi-modal search capabilities can be effectively composed without any additional multi-modal training data. To mitigate parameter interference during cross-modal integration, we introduce Optimal Brain Merging (OBM), a saliency-aware merging algorithm that identifies task-critical parameters based on their impact on model loss using only a small set of calibration samples. Extensive experiments on search-intensive benchmarks (e.g., InfoSeek, MMSearch) reveal that: (1) Model merging secures a reasonable performance floor as a zero-shot agent, with OBM achieving superior search rates; (2) OBM significantly raises the performance ceiling as a warm-start strategy, achieving faster convergence and higher peak accuracy than standard VLM initialization.
EGSS: Entropy-guided Stepwise Scaling for Reliable Software Engineering
Feb 05, 2026Agentic Test-Time Scaling (TTS) has delivered state-of-the-art (SOTA) performance on complex software engineering tasks such as code generation and bug fixing. However, its practical adoption remains limited due to significant computational overhead, primarily driven by two key challenges: (1) the high cost associated with deploying excessively large ensembles, and (2) the lack of a reliable mechanism for selecting the optimal candidate solution, ultimately constraining the performance gains that can be realized. To address these challenges, we propose Entropy-Guided Stepwise Scaling (EGSS), a novel TTS framework that dynamically balances efficiency and effectiveness through entropy-guided adaptive search and robust test-suite augmentation. Extensive experiments on SWE-Bench-Verified demonstrate that EGSS consistently boosts performance by 5-10% across all evaluated models. Specifically, it increases the resolved ratio of Kimi-K2-Intruct from 63.2% to 72.2%, and GLM-4.6 from 65.8% to 74.6%. Furthermore, when paired with GLM-4.6, EGSS achieves a new state-of-the-art among open-source large language models. In addition to these accuracy improvements, EGSS reduces inference-time token usage by over 28% compared to existing TTS methods, achieving simultaneous gains in both effectiveness and computational efficiency.
SVRepair: Structured Visual Reasoning for Automated Program Repair
Feb 05, 2026Large language models (LLMs) have recently shown strong potential for Automated Program Repair (APR), yet most existing approaches remain unimodal and fail to leverage the rich diagnostic signals contained in visual artifacts such as screenshots and control-flow graphs. In practice, many bug reports convey critical information visually (e.g., layout breakage or missing widgets), but directly using such dense visual inputs often causes context loss and noise, making it difficult for MLLMs to ground visual observations into precise fault localization and executable patches. To bridge this semantic gap, we propose \textbf{SVRepair}, a multimodal APR framework with structured visual representation. SVRepair first fine-tunes a vision-language model, \textbf{Structured Visual Representation (SVR)}, to uniformly transform heterogeneous visual artifacts into a \emph{semantic scene graph} that captures GUI elements and their structural relations (e.g., hierarchy), providing normalized, code-relevant context for downstream repair. Building on the graph, SVRepair drives a coding agent to localize faults and synthesize patches, and further introduces an iterative visual-artifact segmentation strategy that progressively narrows the input to bug-centered regions to suppress irrelevant context and reduce hallucinations. Extensive experiments across multiple benchmarks demonstrate state-of-the-art performance: SVRepair achieves \textbf{36.47\%} accuracy on SWE-Bench M, \textbf{38.02\%} on MMCode, and \textbf{95.12\%} on CodeVision, validating the effectiveness of SVRepair for multimodal program repair.
Learning Adaptive Parallel Execution for Efficient Code Localization
Jan 27, 2026Code localization constitutes a key bottleneck in automated software development pipelines. While concurrent tool execution can enhance discovery speed, current agents demonstrate a 34.9\% redundant invocation rate, which negates parallelism benefits. We propose \textbf{FuseSearch}, reformulating parallel code localization as a \textbf{joint quality-efficiency optimization} task. Through defining \textbf{tool efficiency} -- the ratio of unique information gain to invocation count -- we utilize a two-phase SFT and RL training approach for learning adaptive parallel strategies. Different from fixed-breadth approaches, FuseSearch dynamically modulates search breadth according to task context, evolving from exploration phases to refinement stages. Evaluated on SWE-bench Verified, FuseSearch-4B achieves SOTA-level performance (84.7\% file-level and 56.4\% function-level $F_1$ scores) with 93.6\% speedup, utilizing 67.7\% fewer turns and 68.9\% fewer tokens. Results indicate that efficiency-aware training naturally improves quality through eliminating noisy redundant signals, enabling high-performance cost-effective localization agents.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
Hybrid Neural-MPM for Interactive Fluid Simulations in Real-Time
May 25, 2025



We propose a neural physics system for real-time, interactive fluid simulations. Traditional physics-based methods, while accurate, are computationally intensive and suffer from latency issues. Recent machine-learning methods reduce computational costs while preserving fidelity; yet most still fail to satisfy the latency constraints for real-time use and lack support for interactive applications. To bridge this gap, we introduce a novel hybrid method that integrates numerical simulation, neural physics, and generative control. Our neural physics jointly pursues low-latency simulation and high physical fidelity by employing a fallback safeguard to classical numerical solvers. Furthermore, we develop a diffusion-based controller that is trained using a reverse modeling strategy to generate external dynamic force fields for fluid manipulation. Our system demonstrates robust performance across diverse 2D/3D scenarios, material types, and obstacle interactions, achieving real-time simulations at high frame rates (11~29% latency) while enabling fluid control guided by user-friendly freehand sketches. We present a significant step towards practical, controllable, and physically plausible fluid simulations for real-time interactive applications. We promise to release both models and data upon acceptance.
Spectrum-oriented Point-supervised Saliency Detector for Hyperspectral Images
Dec 24, 2024



Hyperspectral salient object detection (HSOD) aims to extract targets or regions with significantly different spectra from hyperspectral images. While existing deep learning-based methods can achieve good detection results, they generally necessitate pixel-level annotations, which are notably challenging to acquire for hyperspectral images. To address this issue, we introduce point supervision into HSOD, and incorporate Spectral Saliency, derived from conventional HSOD methods, as a pivotal spectral representation within the framework. This integration leads to the development of a novel Spectrum-oriented Point-supervised Saliency Detector (SPSD). Specifically, we propose a novel pipeline, specifically designed for HSIs, to generate pseudo-labels, effectively mitigating the performance decline associated with point supervision strategy. Additionally, Spectral Saliency is employed to counteract information loss during model supervision and saliency refinement, thereby maintaining the structural integrity and edge accuracy of the detected objects. Furthermore, we introduce a Spectrum-transformed Spatial Gate to focus more precisely on salient regions while reducing feature redundancy. We have carried out comprehensive experiments on both HSOD-BIT and HS-SOD datasets to validate the efficacy of our proposed method, using mean absolute error (MAE), E-measure, F-measure, Area Under Curve, and Cross Correlation as evaluation metrics. For instance, on the HSOD-BIT dataset, our SPSD achieves a MAE of 0.031 and an F-measure of 0.878. Thorough ablation studies have substantiated the effectiveness of each individual module and provided insights into the model's working mechanism. Further evaluations on RGB-thermal salient object detection datasets highlight the versatility of our approach.
Data-Efficient Inference of Neural Fluid Fields via SciML Foundation Model
Dec 18, 2024



Recent developments in 3D vision have enabled successful progress in inferring neural fluid fields and realistic rendering of fluid dynamics. However, these methods require real-world flow captures, which demand dense video sequences and specialized lab setups, making the process costly and challenging. Scientific machine learning (SciML) foundation models, which are pretrained on extensive simulations of partial differential equations (PDEs), encode rich multiphysics knowledge and thus provide promising sources of domain priors for inferring fluid fields. Nevertheless, their potential to advance real-world vision problems remains largely underexplored, raising questions about the transferability and practical utility of these foundation models. In this work, we demonstrate that SciML foundation model can significantly improve the data efficiency of inferring real-world 3D fluid dynamics with improved generalization. At the core of our method is leveraging the strong forecasting capabilities and meaningful representations of SciML foundation models. We equip neural fluid fields with a novel collaborative training approach that utilizes augmented views and fluid features extracted by our foundation model. Our method demonstrates significant improvements in both quantitative metrics and visual quality, showcasing the practical applicability of SciML foundation models in real-world fluid dynamics.
Collapsed Language Models Promote Fairness
Oct 06, 2024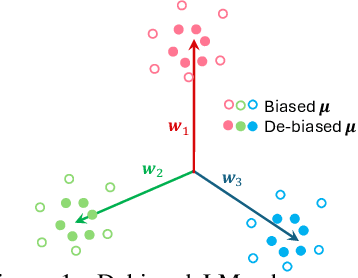
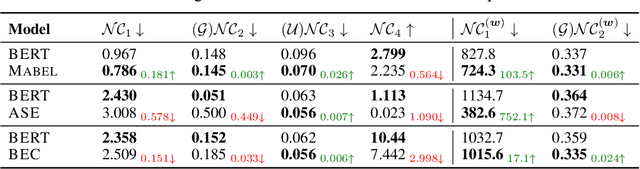
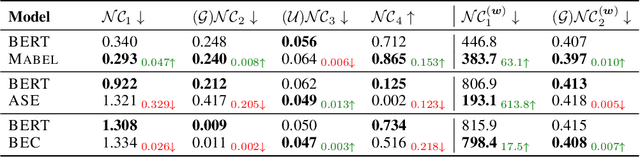
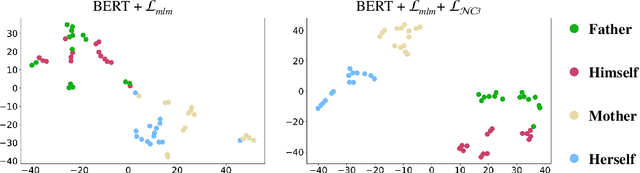
To mitigate societal biases implicitly encoded in recent successful pretrained language models, a diverse array of approaches have been proposed to encourage model fairness, focusing on prompting, data augmentation, regularized fine-tuning, and more. Despite the development, it is nontrivial to reach a principled understanding of fairness and an effective algorithm that can consistently debias language models. In this work, by rigorous evaluations of Neural Collapse -- a learning phenomenon happen in last-layer representations and classifiers in deep networks -- on fairness-related words, we find that debiased language models exhibit collapsed alignment between token representations and word embeddings. More importantly, this observation inspires us to design a principled fine-tuning method that can effectively improve fairness in a wide range of debiasing methods, while still preserving the performance of language models on standard natural language understanding tasks. We attach our code at https://anonymous.4open.science/r/Fairness_NC-457E .
Transferable and Principled Efficiency for Open-Vocabulary Segmentation
Apr 11, 2024



Recent success of pre-trained foundation vision-language models makes Open-Vocabulary Segmentation (OVS) possible. Despite the promising performance, this approach introduces heavy computational overheads for two challenges: 1) large model sizes of the backbone; 2) expensive costs during the fine-tuning. These challenges hinder this OVS strategy from being widely applicable and affordable in real-world scenarios. Although traditional methods such as model compression and efficient fine-tuning can address these challenges, they often rely on heuristics. This means that their solutions cannot be easily transferred and necessitate re-training on different models, which comes at a cost. In the context of efficient OVS, we target achieving performance that is comparable to or even better than prior OVS works based on large vision-language foundation models, by utilizing smaller models that incur lower training costs. The core strategy is to make our efficiency principled and thus seamlessly transferable from one OVS framework to others without further customization. Comprehensive experiments on diverse OVS benchmarks demonstrate our superior trade-off between segmentation accuracy and computation costs over previous works. Our code is available on https://github.com/Xujxyang/OpenTrans