 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCOD: The First Challenging Benchmark and Baseline for Hyperspectral Camouflaged Object Detection
Jan 07, 2026RGB-based camouflaged object detection struggles in real-world scenarios where color and texture cues are ambiguous. While hyperspectral image offers a powerful alternative by capturing fine-grained spectral signatures, progress in hyperspectral camouflaged object detection (HCOD) has been critically hampered by the absence of a dedicated, large-scale benchmark. To spur innovation, we introduce HyperCOD, the first challenging benchmark for HCOD. Comprising 350 high-resolution hyperspectral images, It features complex real-world scenarios with minimal objects, intricate shapes, severe occlusions, and dynamic lighting to challenge current models. The advent of foundation models like the Segment Anything Model (SAM) presents a compelling opportunity. To adapt the Segment Anything Model (SAM) for HCOD, we propose HyperSpectral Camouflage-aware SAM (HSC-SAM). HSC-SAM ingeniously reformulates the hyperspectral image by decoupling it into a spatial map fed to SAM's image encoder and a spectral saliency map that serves as an adaptive prompt. This translation effectively bridges the modality gap. Extensive experiments show that HSC-SAM sets a new state-of-the-art on HyperCOD and generalizes robustly to other public HSI datasets. The HyperCOD dataset and our HSC-SAM baseline provide a robust foundation to foster future research in this emerging area.
MODA: The First Challenging Benchmark for Multispectral Object Detection in Aerial Images
Dec 10, 2025



Aerial object detection faces significant challenges in real-world scenarios, such as small objects and extensive background interference, which limit the performance of RGB-based detectors with insufficient discriminative information. Multispectral images (MSIs) capture additional spectral cues across multiple bands, offering a promising alternative. However, the lack of training data has been the primary bottleneck to exploiting the potential of MSIs. To address this gap, we introduce the first large-scale dataset for Multispectral Object Detection in Aerial images (MODA), which comprises 14,041 MSIs and 330,191 annotations across diverse, challenging scenarios, providing a comprehensive data foundation for this field. Furthermore, to overcome challenges inherent to aerial object detection using MSIs, we propose OSSDet, a framework that integrates spectral and spatial information with object-aware cues. OSSDet employs a cascaded spectral-spatial modulation structure to optimize target perception, aggregates spectrally related features by exploiting spectral similarities to reinforce intra-object correlations, and suppresses irrelevant background via object-aware masking. Moreover, cross-spectral attention further refines object-related representations under explicit object-aware guidance. Extensive experiments demonstrate that OSSDet outperforms existing methods with comparable parameters and efficiency.
MCOD: The First Challenging Benchmark for Multispectral Camouflaged Object Detection
Sep 19, 2025



Camouflaged Object Detection (COD) aims to identify objects that blend seamlessly into natural scenes. Although RGB-based methods have advanced, their performance remains limited under challenging conditions. Multispectral imagery, providing rich spectral information, offers a promising alternative for enhanced foreground-background discrimination. However, existing COD benchmark datasets are exclusively RGB-based, lacking essential support for multispectral approaches, which has impeded progress in this area. To address this gap, we introduce MCOD, the first challenging benchmark dataset specifically designed for multispectral camouflaged object detection. MCOD features three key advantages: (i) Comprehensive challenge attributes: It captures real-world difficulties such as small object sizes and extreme lighting conditions commonly encountered in COD tasks. (ii) Diverse real-world scenarios: The dataset spans a wide range of natural environments to better reflect practical applications. (iii) High-quality pixel-level annotations: Each image is manually annotated with precise object masks and corresponding challenge attribute labels. We benchmark eleven representative COD methods on MCOD, observing a consistent performance drop due to increased task difficulty. Notably, integrating multispectral modalities substantially alleviates this degradation, highlighting the value of spectral information in enhancing detection robustness. We anticipate MCOD will provide a strong foundation for future research in multispectral camouflaged object detection. The dataset is publicly accessible at https://github.com/yl2900260-bit/MCOD.
Hyperspectral Remote Sensing Images Salient Object Detection: The First Benchmark Dataset and Baseline
Apr 03, 2025



The objective of hyperspectral remote sensing image salient object detection (HRSI-SOD) is to identify objects or regions that exhibit distinct spectrum contrasts with the background. This area holds significant promise for practical applications; however, progress has been limited by a notable scarcity of dedicated datasets and methodologies. To bridge this gap and stimulate further research, we introduce the first HRSI-SOD dataset, termed HRSSD, which includes 704 hyperspectral images and 5327 pixel-level annotated salient objects. The HRSSD dataset poses substantial challenges for salient object detection algorithms due to large scale variation, diverse foreground-background relations, and multi-salient objects. Additionally, we propose an innovative and efficient baseline model for HRSI-SOD, termed the Deep Spectral Saliency Network (DSSN). The core of DSSN is the Cross-level Saliency Assessment Block, which performs pixel-wise attention and evaluates the contributions of multi-scale similarity maps at each spatial location, effectively reducing erroneous responses in cluttered regions and emphasizes salient regions across scales. Additionally, the High-resolution Fusion Module combines bottom-up fusion strategy and learned spatial upsampling to leverage the strengths of multi-scale saliency maps, ensuring accurate localization of small objects. Experiments on the HRSSD dataset robustly validate the superiority of DSSN, underscoring the critical need for specialized datasets and methodologies in this domain. Further evaluations on the HSOD-BIT and HS-SOD datasets demonstrate the generalizability of the proposed method. The dataset and source code are publicly available at https://github.com/laprf/HRSSD.
HSOD-BIT-V2: A New Challenging Benchmarkfor Hyperspectral Salient Object Detection
Mar 18, 2025Salient Object Detection (SOD) is crucial in computer vision, yet RGB-based methods face limitations in challenging scenes, such as small objects and similar color features. Hyperspectral images provide a promising solution for more accurate Hyperspectral Salient Object Detection (HSOD) by abundant spectral information, while HSOD methods are hindered by the lack of extensive and available datasets. In this context, we introduce HSOD-BIT-V2, the largest and most challenging HSOD benchmark dataset to date. Five distinct challenges focusing on small objects and foreground-background similarity are designed to emphasize spectral advantages and real-world complexity. To tackle these challenges, we propose Hyper-HRNet, a high-resolution HSOD network. Hyper-HRNet effectively extracts, integrates, and preserves effective spectral information while reducing dimensionality by capturing the self-similar spectral features. Additionally, it conveys fine details and precisely locates object contours by incorporating comprehensive global information and detailed object saliency representations. Experimental analysis demonstrates that Hyper-HRNet outperforms existing models, especially in challenging scenarios.
Spectrum-oriented Point-supervised Saliency Detector for Hyperspectral Images
Dec 24, 2024



Hyperspectral salient object detection (HSOD) aims to extract targets or regions with significantly different spectra from hyperspectral images. While existing deep learning-based methods can achieve good detection results, they generally necessitate pixel-level annotations, which are notably challenging to acquire for hyperspectral images. To address this issue, we introduce point supervision into HSOD, and incorporate Spectral Saliency, derived from conventional HSOD methods, as a pivotal spectral representation within the framework. This integration leads to the development of a novel Spectrum-oriented Point-supervised Saliency Detector (SPSD). Specifically, we propose a novel pipeline, specifically designed for HSIs, to generate pseudo-labels, effectively mitigating the performance decline associated with point supervision strategy. Additionally, Spectral Saliency is employed to counteract information loss during model supervision and saliency refinement, thereby maintaining the structural integrity and edge accuracy of the detected objects. Furthermore, we introduce a Spectrum-transformed Spatial Gate to focus more precisely on salient regions while reducing feature redundancy. We have carried out comprehensive experiments on both HSOD-BIT and HS-SOD datasets to validate the efficacy of our proposed method, using mean absolute error (MAE), E-measure, F-measure, Area Under Curve, and Cross Correlation as evaluation metrics. For instance, on the HSOD-BIT dataset, our SPSD achieves a MAE of 0.031 and an F-measure of 0.878. Thorough ablation studies have substantiated the effectiveness of each individual module and provided insights into the model's working mechanism. Further evaluations on RGB-thermal salient object detection datasets highlight the versatility of our approach.
Content-driven Magnitude-Derivative Spectrum Complementary Learning for Hyperspectral Image Classification
Jul 26, 2024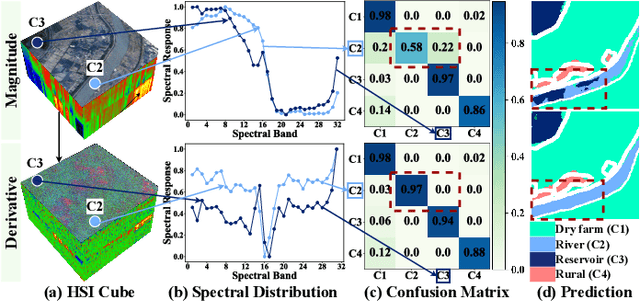

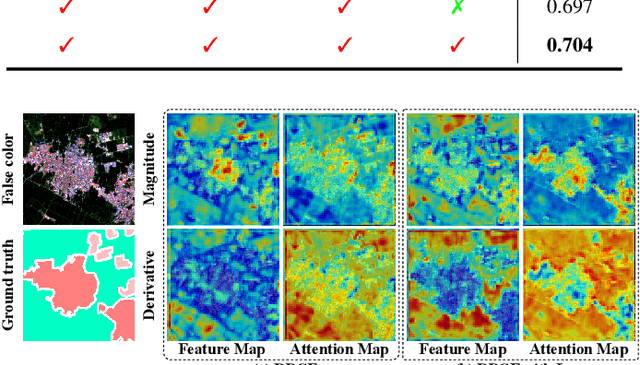
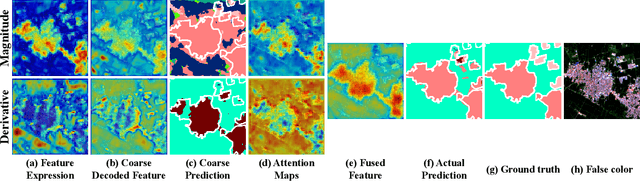
Extracting discriminative information from complex spectral details in hyperspectral image (HSI) for HSI classification is pivotal. While current prevailing methods rely on spectral magnitude features, they could cause confusion in certain classes, resulting in misclassification and decreased accuracy. We find that the derivative spectrum proves more adept at capturing concealed information, thereby offering a distinct advantage in separating these confusion classes. Leveraging the complementarity between spectral magnitude and derivative features, we propose a Content-driven Spectrum Complementary Network based on Magnitude-Derivative Dual Encoder, employing these two features as combined inputs. To fully utilize their complementary information, we raise a Content-adaptive Point-wise Fusion Module, enabling adaptive fusion of dual-encoder features in a point-wise selective manner, contingent upon feature representation. To preserve a rich source of complementary information while extracting more distinguishable features, we introduce a Hybrid Disparity-enhancing Loss that enhances the differential expression of the features from the two branches and increases the inter-class distance. As a result, our method achieves state-of-the-art results on the extensive WHU-OHS dataset and eight other benchmark datasets.
Dual-stage Hyperspectral Image Classification Model with Spectral Supertoken
Jul 10, 2024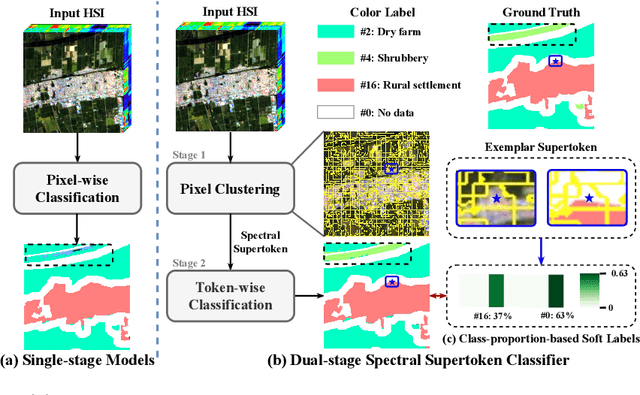
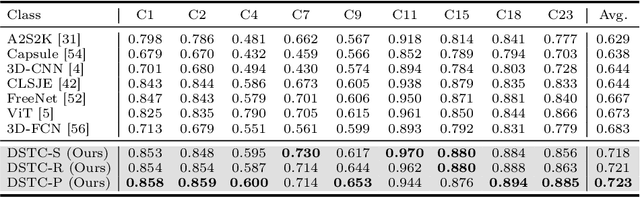
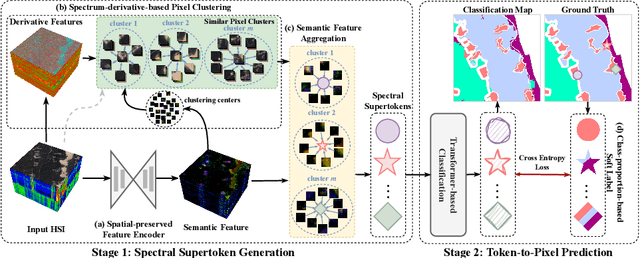
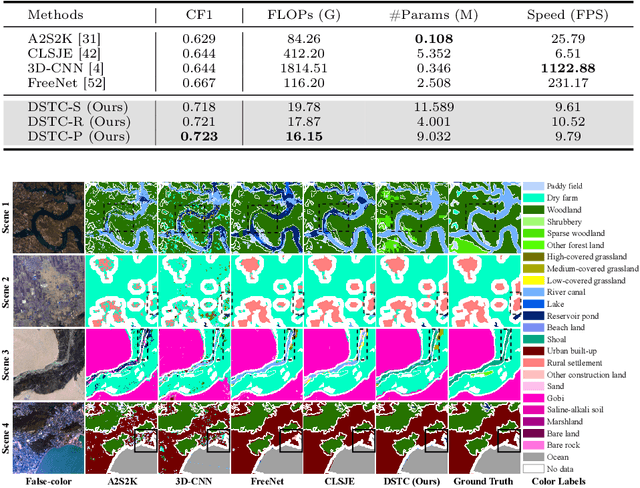
Hyperspectral image classification, a task that assigns pre-defined classes to each pixel in a hyperspectral image of remote sensing scenes, often faces challenges due to the neglect of correlations between spectrally similar pixels. This oversight can lead to inaccurate edge definitions and difficulties in managing minor spectral variations in contiguous areas. To address these issues, we introduce the novel Dual-stage Spectral Supertoken Classifier (DSTC), inspired by superpixel concepts. DSTC employs spectrum-derivative-based pixel clustering to group pixels with similar spectral characteristics into spectral supertokens. By projecting the classification of these tokens onto the image space, we achieve pixel-level results that maintain regional classification consistency and precise boundary. Moreover, recognizing the diversity within tokens, we propose a class-proportion-based soft label. This label adaptively assigns weights to different categories based on their prevalence, effectively managing data distribution imbalances and enhancing classification performance. Comprehensive experiments on WHU-OHS, IP, KSC, and UP datasets corroborate the robust classification capabilities of DSTC and the effectiveness of its individual components. Code will be publicly available at https://github.com/laprf/DSTC.
DMSSN: Distilled Mixed Spectral-Spatial Network for Hyperspectral Salient Object Detection
Mar 31, 2024



Hyperspectral salient object detection (HSOD) has exhibited remarkable promise across various applications, particularly in intricate scenarios where conventional RGB-based approaches fall short. Despite the considerable progress in HSOD method advancements, two critical challenges require immediate attention. Firstly, existing hyperspectral data dimension reduction techniques incur a loss of spectral information, which adversely affects detection accuracy. Secondly, previous methods insufficiently harness the inherent distinctive attributes of hyperspectral images (HSIs) during the feature extraction process. To address these challenges, we propose a novel approach termed the Distilled Mixed Spectral-Spatial Network (DMSSN), comprising a Distilled Spectral Encoding process and a Mixed Spectral-Spatial Transformer (MSST) feature extraction network. The encoding process utilizes knowledge distillation to construct a lightweight autoencoder for dimension reduction, striking a balance between robust encoding capabilities and low computational costs. The MSST extracts spectral-spatial features through multiple attention head groups, collaboratively enhancing its resistance to intricate scenarios. Moreover, we have created a large-scale HSOD dataset, HSOD-BIT, to tackle the issue of data scarcity in this field and meet the fundamental data requirements of deep network training. Extensive experiments demonstrate that our proposed DMSSN achieves state-of-the-art performance on multiple datasets. We will soon make the code and dataset publicly available on https://github.com/anonymous0519/HSOD-BIT.
Spectrum-driven Mixed-frequency Network for Hyperspectral Salient Object Detection
Dec 02, 2023



Hyperspectral salient object detection (HSOD) aims to detect spectrally salient objects in hyperspectral images (HSIs). However, existing methods inadequately utilize spectral information by either converting HSIs into false-color images or converging neural networks with clustering. We propose a novel approach that fully leverages the spectral characteristics by extracting two distinct frequency components from the spectrum: low-frequency Spectral Saliency and high-frequency Spectral Edge. The Spectral Saliency approximates the region of salient objects, while the Spectral Edge captures edge information of salient objects. These two complementary components, crucial for HSOD, are derived by computing from the inter-layer spectral angular distance of the Gaussian pyramid and the intra-neighborhood spectral angular gradients, respectively. To effectively utilize this dual-frequency information, we introduce a novel lightweight Spectrum-driven Mixed-frequency Network (SMN). SMN incorporates two parameter-free plug-and-play operators, namely Spectral Saliency Generator and Spectral Edge Operator, to extract the Spectral Saliency and Spectral Edge components from the input HSI independently. Subsequently, the Mixed-frequency Attention module, comprised of two frequency-dependent heads, intelligently combines the embedded features of edge and saliency information, resulting in a mixed-frequency feature representation. Furthermore, a saliency-edge-aware decoder progressively scales up the mixed-frequency feature while preserving rich detail and saliency information for accurate salient object prediction. Extensive experiments conducted on the HS-SOD benchmark and our custom dataset HSOD-BIT demonstrate that our SMN outperforms state-of-the-art methods regarding HSOD performance. Code and dataset will be available at https://github.com/laprf/SMN.