 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMOT: The First Challenging Benchmark for Drone-based Multispectral Multi-Object Tracking
Oct 14, 2025Drone-based multi-object tracking is essential yet highly challenging due to small targets, severe occlusions, and cluttered backgrounds. Existing RGB-based tracking algorithms heavily depend on spatial appearance cues such as color and texture, which often degrade in aerial views, compromising reliability. Multispectral imagery, capturing pixel-level spectral reflectance, provides crucial cues that enhance object discriminability under degraded spatial conditions. However, the lack of dedicated multispectral UAV datasets has hindered progress in this domain. To bridge this gap, we introduce MMOT, the first challenging benchmark for drone-based multispectral multi-object tracking. It features three key characteristics: (i) Large Scale - 125 video sequences with over 488.8K annotations across eight categories; (ii) Comprehensive Challenges - covering diverse conditions such as extreme small targets, high-density scenarios, severe occlusions, and complex motion; and (iii) Precise Oriented Annotations - enabling accurate localization and reduced ambiguity under aerial perspectives. To better extract spectral features and leverage oriented annotations, we further present a multispectral and orientation-aware MOT scheme adapting existing methods, featuring: (i) a lightweight Spectral 3D-Stem integrating spectral features while preserving compatibility with RGB pretraining; (ii) an orientation-aware Kalman filter for precise state estimation; and (iii) an end-to-end orientation-adaptive transformer. Extensive experiments across representative trackers consistently show that multispectral input markedly improves tracking performance over RGB baselines, particularly for small and densely packed objects. We believe our work will advance drone-based multispectral multi-object tracking research. Our MMOT, code, and benchmarks are publicly available at https://github.com/Annzstbl/MMOT.
HSOD-BIT-V2: A New Challenging Benchmarkfor Hyperspectral Salient Object Detection
Mar 18, 2025Salient Object Detection (SOD) is crucial in computer vision, yet RGB-based methods face limitations in challenging scenes, such as small objects and similar color features. Hyperspectral images provide a promising solution for more accurate Hyperspectral Salient Object Detection (HSOD) by abundant spectral information, while HSOD methods are hindered by the lack of extensive and available datasets. In this context, we introduce HSOD-BIT-V2, the largest and most challenging HSOD benchmark dataset to date. Five distinct challenges focusing on small objects and foreground-background similarity are designed to emphasize spectral advantages and real-world complexity. To tackle these challenges, we propose Hyper-HRNet, a high-resolution HSOD network. Hyper-HRNet effectively extracts, integrates, and preserves effective spectral information while reducing dimensionality by capturing the self-similar spectral features. Additionally, it conveys fine details and precisely locates object contours by incorporating comprehensive global information and detailed object saliency representations. Experimental analysis demonstrates that Hyper-HRNet outperforms existing models, especially in challenging scenarios.
DMSSN: Distilled Mixed Spectral-Spatial Network for Hyperspectral Salient Object Detection
Mar 31, 2024



Hyperspectral salient object detection (HSOD) has exhibited remarkable promise across various applications, particularly in intricate scenarios where conventional RGB-based approaches fall short. Despite the considerable progress in HSOD method advancements, two critical challenges require immediate attention. Firstly, existing hyperspectral data dimension reduction techniques incur a loss of spectral information, which adversely affects detection accuracy. Secondly, previous methods insufficiently harness the inherent distinctive attributes of hyperspectral images (HSIs) during the feature extraction process. To address these challenges, we propose a novel approach termed the Distilled Mixed Spectral-Spatial Network (DMSSN), comprising a Distilled Spectral Encoding process and a Mixed Spectral-Spatial Transformer (MSST) feature extraction network. The encoding process utilizes knowledge distillation to construct a lightweight autoencoder for dimension reduction, striking a balance between robust encoding capabilities and low computational costs. The MSST extracts spectral-spatial features through multiple attention head groups, collaboratively enhancing its resistance to intricate scenarios. Moreover, we have created a large-scale HSOD dataset, HSOD-BIT, to tackle the issue of data scarcity in this field and meet the fundamental data requirements of deep network training. Extensive experiments demonstrate that our proposed DMSSN achieves state-of-the-art performance on multiple datasets. We will soon make the code and dataset publicly available on https://github.com/anonymous0519/HSOD-BIT.
Multi-step Temporal Modeling for UAV Tracking
Mar 07, 2024In the realm of unmanned aerial vehicle (UAV) tracking, Siamese-based approaches have gained traction due to their optimal balance between efficiency and precision. However, UAV scenarios often present challenges such as insufficient sampling resolution, fast motion and small objects with limited feature information. As a result, temporal context in UAV tracking tasks plays a pivotal role in target location, overshadowing the target's precise features. In this paper, we introduce MT-Track, a streamlined and efficient multi-step temporal modeling framework designed to harness the temporal context from historical frames for enhanced UAV tracking. This temporal integration occurs in two steps: correlation map generation and correlation map refinement. Specifically, we unveil a unique temporal correlation module that dynamically assesses the interplay between the template and search region features. This module leverages temporal information to refresh the template feature, yielding a more precise correlation map. Subsequently, we propose a mutual transformer module to refine the correlation maps of historical and current frames by modeling the temporal knowledge in the tracking sequence. This method significantly trims computational demands compared to the raw transformer. The compact yet potent nature of our tracking framework ensures commendable tracking outcomes, particularly in extended tracking scenarios.
Factorization Vision Transformer: Modeling Long Range Dependency with Local Window Cost
Dec 14, 2023

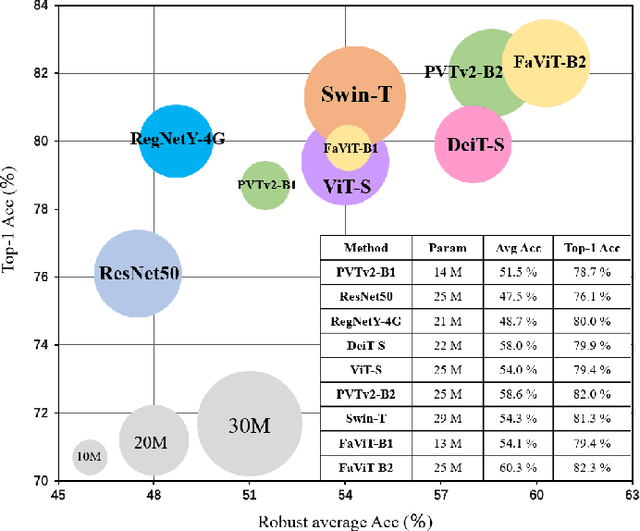

Transformers have astounding representational power but typically consume considerable computation which is quadratic with image resolution. The prevailing Swin transformer reduces computational costs through a local window strategy. However, this strategy inevitably causes two drawbacks: (1) the local window-based self-attention hinders global dependency modeling capability; (2) recent studies point out that local windows impair robustness. To overcome these challenges, we pursue a preferable trade-off between computational cost and performance. Accordingly, we propose a novel factorization self-attention mechanism (FaSA) that enjoys both the advantages of local window cost and long-range dependency modeling capability. By factorizing the conventional attention matrix into sparse sub-attention matrices, FaSA captures long-range dependencies while aggregating mixed-grained information at a computational cost equivalent to the local window-based self-attention. Leveraging FaSA, we present the factorization vision transformer (FaViT) with a hierarchical structure. FaViT achieves high performance and robustness, with linear computational complexity concerning input image spatial resolution. Extensive experiments have shown FaViT's advanced performance in classification and downstream tasks. Furthermore, it also exhibits strong model robustness to corrupted and biased data and hence demonstrates benefits in favor of practical applications. In comparison to the baseline model Swin-T, our FaViT-B2 significantly improves classification accuracy by 1% and robustness by 7%, while reducing model parameters by 14%. Our code will soon be publicly available at https://github.com/q2479036243/FaViT.
BACTrack: Building Appearance Collection for Aerial Tracking
Dec 11, 2023
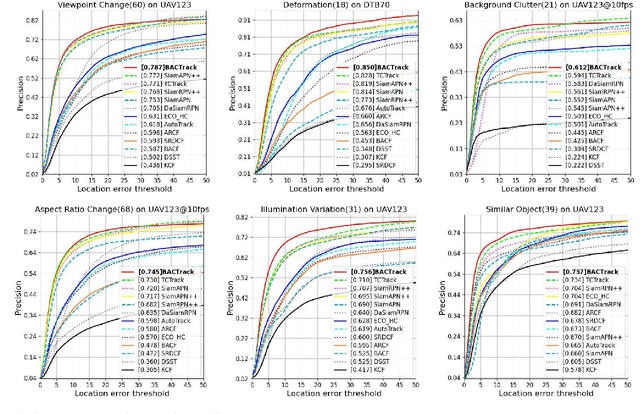
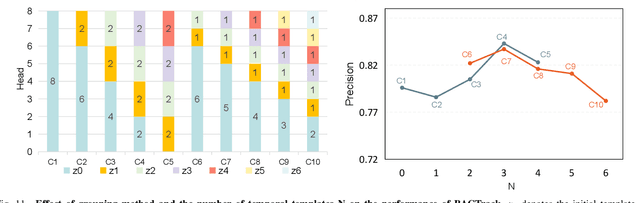
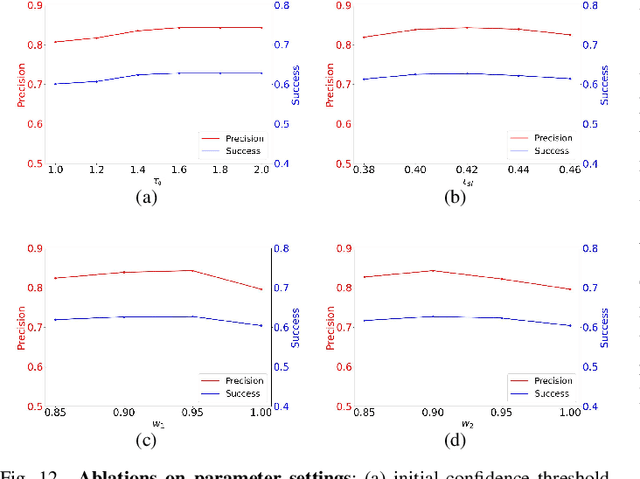
Siamese network-based trackers have shown remarkable success in aerial tracking. Most previous works, however, usually perform template matching only between the initial template and the search region and thus fail to deal with rapidly changing targets that often appear in aerial tracking. As a remedy, this work presents Building Appearance Collection Tracking (BACTrack). This simple yet effective tracking framework builds a dynamic collection of target templates online and performs efficient multi-template matching to achieve robust tracking. Specifically, BACTrack mainly comprises a Mixed-Temporal Transformer (MTT) and an appearance discriminator. The former is responsible for efficiently building relationships between the search region and multiple target templates in parallel through a mixed-temporal attention mechanism. At the same time, the appearance discriminator employs an online adaptive template-update strategy to ensure that the collected multiple templates remain reliable and diverse, allowing them to closely follow rapid changes in the target's appearance and suppress background interference during tracking. Extensive experiments show that our BACTrack achieves top performance on four challenging aerial tracking benchmarks while maintaining an impressive speed of over 87 FPS on a single GPU. Speed tests on embedded platforms also validate our potential suitability for deployment on UAV platforms.
Spectrum-driven Mixed-frequency Network for Hyperspectral Salient Object Detection
Dec 02, 2023



Hyperspectral salient object detection (HSOD) aims to detect spectrally salient objects in hyperspectral images (HSIs). However, existing methods inadequately utilize spectral information by either converting HSIs into false-color images or converging neural networks with clustering. We propose a novel approach that fully leverages the spectral characteristics by extracting two distinct frequency components from the spectrum: low-frequency Spectral Saliency and high-frequency Spectral Edge. The Spectral Saliency approximates the region of salient objects, while the Spectral Edge captures edge information of salient objects. These two complementary components, crucial for HSOD, are derived by computing from the inter-layer spectral angular distance of the Gaussian pyramid and the intra-neighborhood spectral angular gradients, respectively. To effectively utilize this dual-frequency information, we introduce a novel lightweight Spectrum-driven Mixed-frequency Network (SMN). SMN incorporates two parameter-free plug-and-play operators, namely Spectral Saliency Generator and Spectral Edge Operator, to extract the Spectral Saliency and Spectral Edge components from the input HSI independently. Subsequently, the Mixed-frequency Attention module, comprised of two frequency-dependent heads, intelligently combines the embedded features of edge and saliency information, resulting in a mixed-frequency feature representation. Furthermore, a saliency-edge-aware decoder progressively scales up the mixed-frequency feature while preserving rich detail and saliency information for accurate salient object prediction. Extensive experiments conducted on the HS-SOD benchmark and our custom dataset HSOD-BIT demonstrate that our SMN outperforms state-of-the-art methods regarding HSOD performance. Code and dataset will be available at https://github.com/laprf/SMN.