 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum-driven Mixed-frequency Network for Hyperspectral Salient Object Detection
Dec 02, 2023



Hyperspectral salient object detection (HSOD) aims to detect spectrally salient objects in hyperspectral images (HSIs). However, existing methods inadequately utilize spectral information by either converting HSIs into false-color images or converging neural networks with clustering. We propose a novel approach that fully leverages the spectral characteristics by extracting two distinct frequency components from the spectrum: low-frequency Spectral Saliency and high-frequency Spectral Edge. The Spectral Saliency approximates the region of salient objects, while the Spectral Edge captures edge information of salient objects. These two complementary components, crucial for HSOD, are derived by computing from the inter-layer spectral angular distance of the Gaussian pyramid and the intra-neighborhood spectral angular gradients, respectively. To effectively utilize this dual-frequency information, we introduce a novel lightweight Spectrum-driven Mixed-frequency Network (SMN). SMN incorporates two parameter-free plug-and-play operators, namely Spectral Saliency Generator and Spectral Edge Operator, to extract the Spectral Saliency and Spectral Edge components from the input HSI independently. Subsequently, the Mixed-frequency Attention module, comprised of two frequency-dependent heads, intelligently combines the embedded features of edge and saliency information, resulting in a mixed-frequency feature representation. Furthermore, a saliency-edge-aware decoder progressively scales up the mixed-frequency feature while preserving rich detail and saliency information for accurate salient object prediction. Extensive experiments conducted on the HS-SOD benchmark and our custom dataset HSOD-BIT demonstrate that our SMN outperforms state-of-the-art methods regarding HSOD performance. Code and dataset will be available at https://github.com/laprf/SMN.
Spectral-wise Implicit Neural Representation for Hyperspectral Image Reconstruction
Dec 02, 2023Coded Aperture Snapshot Spectral Imaging (CASSI) reconstruction aims to recover the 3D spatial-spectral signal from 2D measurement. Existing methods for reconstructing Hyperspectral Image (HSI) typically involve learning mappings from a 2D compressed image to a predetermined set of discrete spectral bands. However, this approach overlooks the inherent continuity of the spectral information. In this study, we propose an innovative method called Spectral-wise Implicit Neural Representation (SINR) as a pioneering step toward addressing this limitation. SINR introduces a continuous spectral amplification process for HSI reconstruction, enabling spectral super-resolution with customizable magnification factors. To achieve this, we leverage the concept of implicit neural representation. Specifically, our approach introduces a spectral-wise attention mechanism that treats individual channels as distinct tokens, thereby capturing global spectral dependencies. Additionally, our approach incorporates two components, namely a Fourier coordinate encoder and a spectral scale factor module. The Fourier coordinate encoder enhances the SINR's ability to emphasize high-frequency components, while the spectral scale factor module guides the SINR to adapt to the variable number of spectral channels. Notably, the SINR framework enhances the flexibility of CASSI reconstruction by accommodating an unlimited number of spectral bands in the desired output. Extensive experiments demonstrate that our SINR outperforms baseline methods. By enabling continuous reconstruction within the CASSI framework, we take the initial stride toward integrating implicit neural representation into the field.
RDFNet: Regional Dynamic FISTA-Net for Spectral Snapshot Compressive Imaging
Feb 06, 2023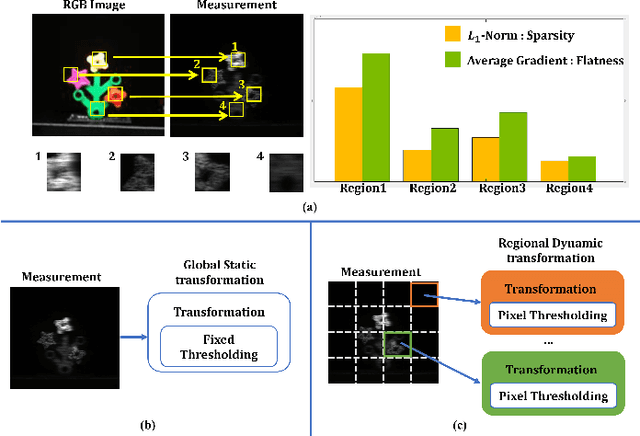
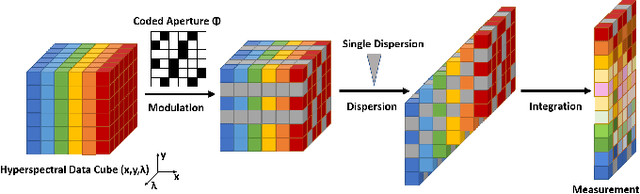
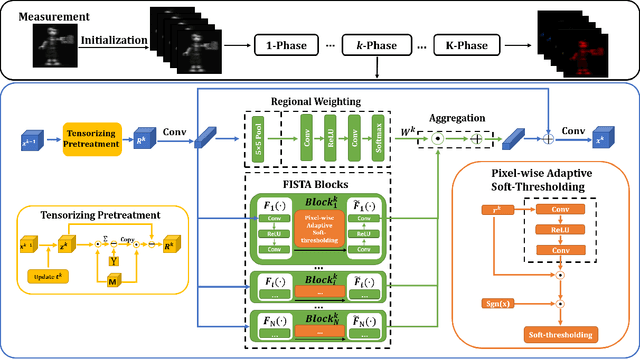
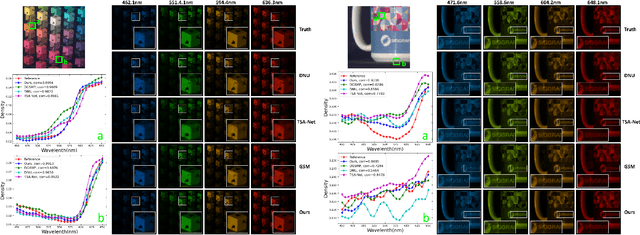
Deep convolutional neural networks have recently shown promising results in compressive spectral reconstruction. Previous methods, however, usually adopt a single mapping function for sparse representation. Considering that different regions have distinct characteristics, it is desirable to apply various mapping functions to adjust different regions' transformations dynamically. With this in mind, we first introduce a regional dynamic way of using Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) to exploit regional characteristics and derive dynamic sparse representations. Then, we propose to unfold the process into a hierarchical dynamic deep network, dubbed RDFNet. The network comprises multiple regional dynamic blocks and corresponding pixel-wise adaptive soft-thresholding modules, respectively in charge of region-based dynamic mapping and pixel-wise soft-thresholding selection. The regional dynamic block guides the network to adjust the transformation domain for different regions. Equipped with the adaptive soft-thresholding, our proposed regional dynamic architecture can also learn appropriate shrinkage scale in a pixel-wise manner. Extensive experiments on both simulated and real data demonstrate that our method outperforms prior state-of-the-arts.